Hadoop生态圈-使用MapReduce处理HBase数据
Hadoop生态圈-使用MapReduce处理HBase数据
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.对HBase表中数据进行单词统计(TableInputFormat)
1>.准备环境
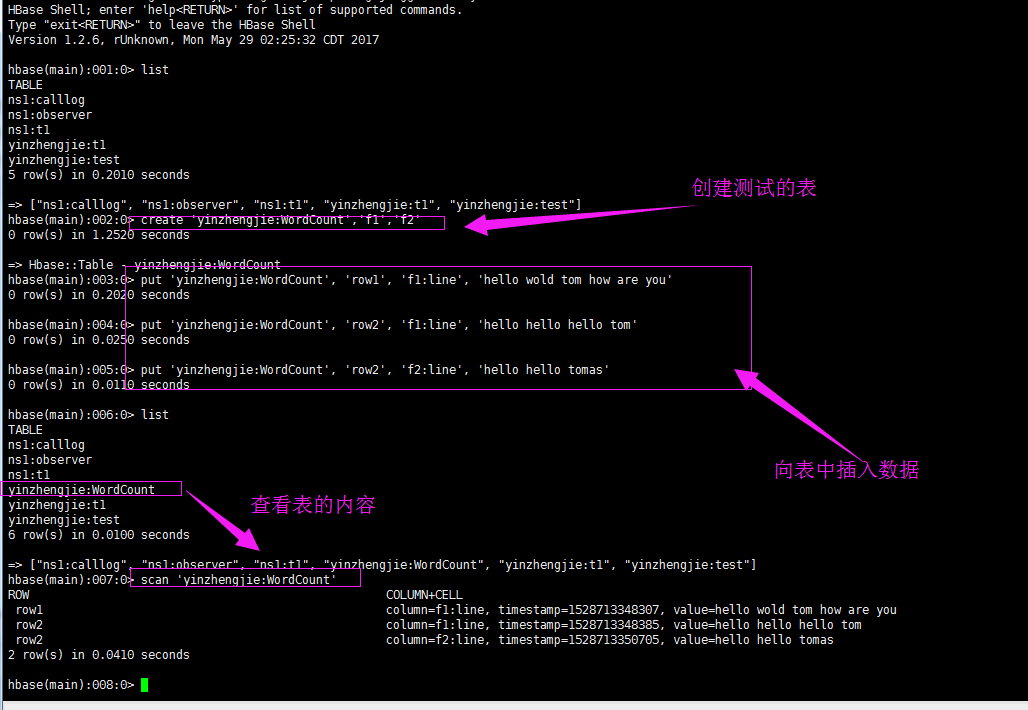
create_namespace 'yinzhengjie'
create 'yinzhengjie:WordCount','f1','f2'
put 'yinzhengjie:WordCount', 'row1', 'f1:line', 'hello wold tom how are you'
put 'yinzhengjie:WordCount', 'row2', 'f1:line', 'hello hello hello tom'
put 'yinzhengjie:WordCount', 'row2', 'f2:line', 'hello hello tomas'
scan 'yinzhengjie:WordCount'
2>.编写Map端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.tableinput; import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException;
import java.util.List; /**
* 使用hbase表做wordcount
*/
public class TableInputMapper extends Mapper<ImmutableBytesWritable,Result, Text,IntWritable> { /**
*
* @param key : 可以理解为HBase中的rowkey
* @param value : 输入端的结果集
* @param context : 和reduce端进行数据传输的上下文
*/
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
//将输入端的结果集编程一个集合
List<Cell> cells = value.listCells();
//遍历集合,拿到每个元素的值,然后在按照空格进行切分,并将处理的结果传给reduce端
for (Cell cell : cells) {
String line = Bytes.toString(CellUtil.cloneValue(cell));
String[] arr = line.split(" ");
for(String word : arr){
context.write(new Text(word), new IntWritable(1));
}
}
}
}
3>.编写Reducer端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.tableinput; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class TableInputReducer extends Reducer<Text,IntWritable,Text,IntWritable> { @Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key,new IntWritable(sum));
}
}
4>.编写主程序代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.tableinput; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.mapreduce.TableInputFormat;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import static org.apache.hadoop.hbase.mapreduce.TableInputFormat.INPUT_TABLE;
import static org.apache.hadoop.hbase.mapreduce.TableInputFormat.SCAN_COLUMN_FAMILY; public class App { public static void main(String[] args) throws Exception {
//创建一个conf对象
Configuration conf = HBaseConfiguration.create();
//设置输入表,即指定源数据来自HBase的那个表
conf.set(INPUT_TABLE,"yinzhengjie:WordCount");
//设置扫描列族
conf.set(SCAN_COLUMN_FAMILY,"f1");
//创建一个任务对象job,别忘记把conf传进去哟!
Job job = Job.getInstance(conf);
//给任务起个名字
job.setJobName("Table WC");
//指定main函数所在的类,也就是当前所在的类名
job.setJarByClass(App.class);
//设置自定义的Map程序和Reduce程序
job.setMapperClass(TableInputMapper.class);
job.setReducerClass(TableInputReducer.class);
//设置输入格式
job.setInputFormatClass(TableInputFormat.class);
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path("file:///D:\\BigData\\yinzhengjieData\\out"));
//设置输出k-v
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//等待任务执行结束
job.waitForCompletion(true);
}
}
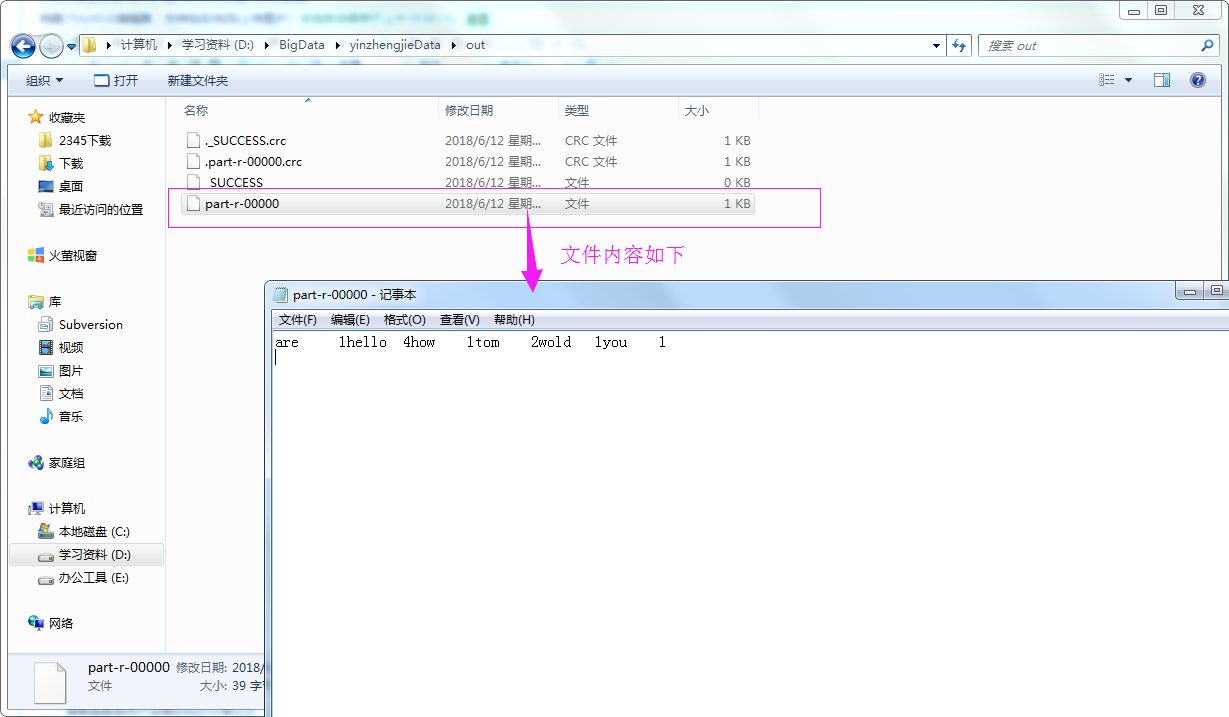
5>.查看测试结果
二.将本地文件进行单词统计的结果输出到HBase中(TableOutputFormat)
1>.准备环境
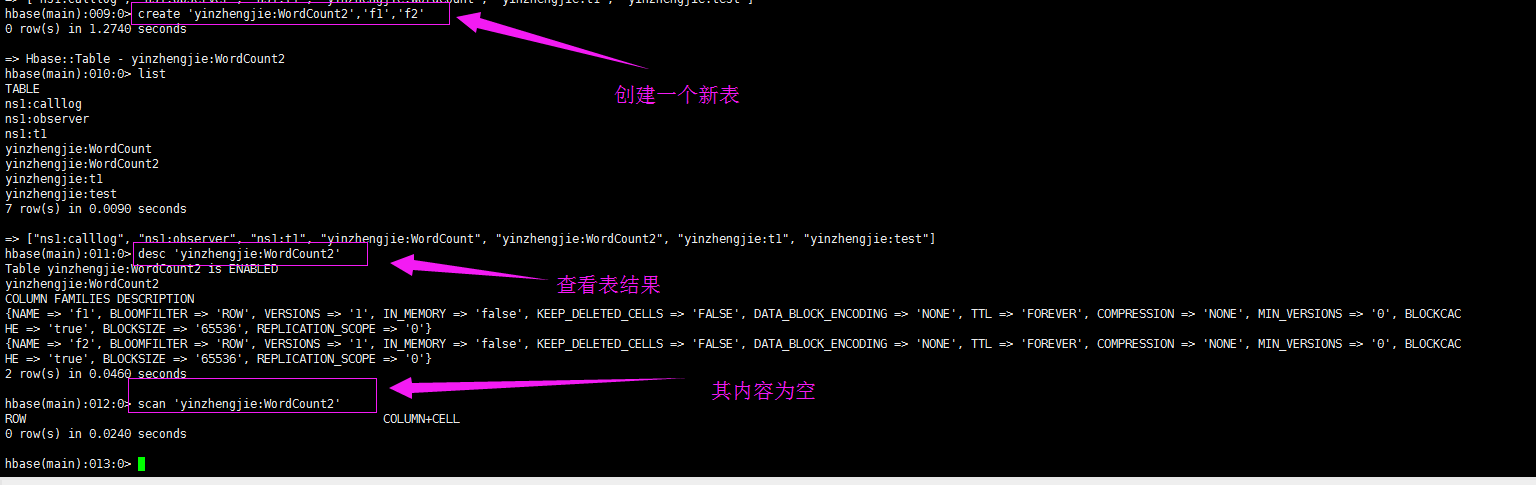
list
create 'yinzhengjie:WordCount2','f1','f2'
list
desc 'yinzhengjie:WordCount2'
scan 'yinzhengjie:WordCount2'
2>.编写Map端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.tableoutput; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException; public class TableOutputMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//得到一行数据
String line = value.toString();
//按空格进行切分
String[] arr = line.split(" ");
//遍历切分后的数据,并将每个单词数的赋初始值为1
for (String word : arr){
context.write(new Text(word),new IntWritable(1));
}
}
}
3>.编写Reducer端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.tableoutput; import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException; public class TableOutputReducer extends Reducer<Text,IntWritable,NullWritable,Put> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//对同一个key的出现的次数进行相加操作,算出一个单词出现的次数
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
} /**
* 注意,“key.toString().length() > 0”的目的是排除空串,所谓空转就是两个连续的空格链接在一起,
* 比如“hello world”,有两个空格,如果以空格切分的话,由于有两个空格,因此hello和world之间会被切割
* 两次,这也就意味着会出现三个对象,即"hello","","world"。由于这个空串("")的长度为0,因此,如果我
* 们指向统计单词的个数,只需要让长度大于0,就可以轻松过滤出“hello”和“world”两个参数啦!
*/
if(key.toString().length() > 0){
Put put = new Put(Bytes.toBytes(key.toString()));
//添加每列的数据
put.addColumn(Bytes.toBytes("f1"),Bytes.toBytes("count"),Bytes.toBytes(sum+""));
context.write(NullWritable.get(),put);
}
}
}
4>.编写主程序代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.tableoutput; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; public class App {
public static void main(String[] args) throws Exception {
//创建一个conf对象
Configuration conf = HBaseConfiguration.create();
//设置输出表,即指定将数据存储在哪个HBase表
conf.set(TableOutputFormat.OUTPUT_TABLE,"yinzhengjie:WordCount2");
//创建一个任务对象job,别忘记把conf传进去哟!
Job job = Job.getInstance(conf);
//给任务起个名字
job.setJobName("Table WordCount2");
//指定main函数所在的类,也就是当前所在的类名
job.setJarByClass(App.class);
//设置自定义的Map程序和Reduce程序
job.setMapperClass(TableOutputMapper.class);
job.setReducerClass(TableOutputReducer.class);
//设置输出格式
job.setOutputFormatClass(TableOutputFormat.class);
//设置输入路径
FileInputFormat.addInputPath(job,new Path("file:///D:\\BigData\\yinzhengjieData\\word.txt"));
//设置输出k-v
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Put.class);
//设置map端输出k-v
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//等待任务执行结束
job.waitForCompletion(true);
}
}
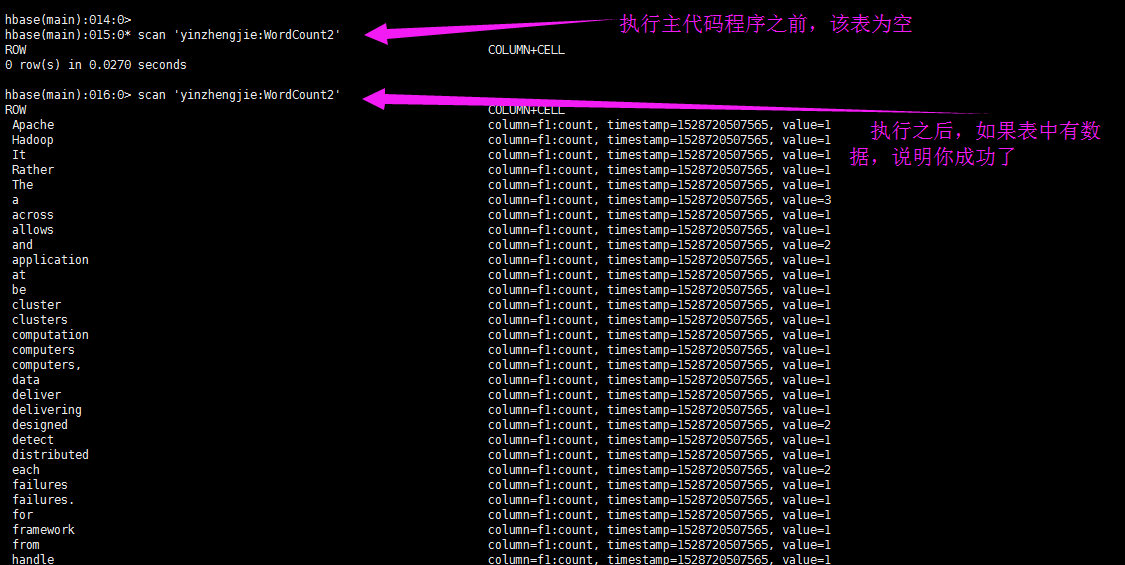
5>.查看测试结果(需要执行主代码程序)
hbase(main)::* scan 'yinzhengjie:WordCount2'
ROW COLUMN+CELL
row(s) in 0.0270 seconds hbase(main)::> scan 'yinzhengjie:WordCount2'
ROW COLUMN+CELL
Apache column=f1:count, timestamp=, value=
Hadoop column=f1:count, timestamp=, value=
It column=f1:count, timestamp=, value=
Rather column=f1:count, timestamp=, value=
The column=f1:count, timestamp=, value=
a column=f1:count, timestamp=, value=
across column=f1:count, timestamp=, value=
allows column=f1:count, timestamp=, value=
and column=f1:count, timestamp=, value=
application column=f1:count, timestamp=, value=
at column=f1:count, timestamp=, value=
be column=f1:count, timestamp=, value=
cluster column=f1:count, timestamp=, value=
clusters column=f1:count, timestamp=, value=
computation column=f1:count, timestamp=, value=
computers column=f1:count, timestamp=, value=
computers, column=f1:count, timestamp=, value=
data column=f1:count, timestamp=, value=
deliver column=f1:count, timestamp=, value=
delivering column=f1:count, timestamp=, value=
designed column=f1:count, timestamp=, value=
detect column=f1:count, timestamp=, value=
distributed column=f1:count, timestamp=, value=
each column=f1:count, timestamp=, value=
failures column=f1:count, timestamp=, value=
failures. column=f1:count, timestamp=, value=
for column=f1:count, timestamp=, value=
framework column=f1:count, timestamp=, value=
from column=f1:count, timestamp=, value=
handle column=f1:count, timestamp=, value=
hardware column=f1:count, timestamp=, value=
high-availability, column=f1:count, timestamp=, value=
highly-available column=f1:count, timestamp=, value=
is column=f1:count, timestamp=, value=
itself column=f1:count, timestamp=, value=
large column=f1:count, timestamp=, value=
layer, column=f1:count, timestamp=, value=
library column=f1:count, timestamp=, value=
local column=f1:count, timestamp=, value=
machines, column=f1:count, timestamp=, value=
may column=f1:count, timestamp=, value=
models. column=f1:count, timestamp=, value=
of column=f1:count, timestamp=, value=
offering column=f1:count, timestamp=, value=
on column=f1:count, timestamp=, value=
processing column=f1:count, timestamp=, value=
programming column=f1:count, timestamp=, value=
prone column=f1:count, timestamp=, value=
rely column=f1:count, timestamp=, value=
scale column=f1:count, timestamp=, value=
servers column=f1:count, timestamp=, value=
service column=f1:count, timestamp=, value=
sets column=f1:count, timestamp=, value=
simple column=f1:count, timestamp=, value=
single column=f1:count, timestamp=, value=
so column=f1:count, timestamp=, value=
software column=f1:count, timestamp=, value=
storage. column=f1:count, timestamp=, value=
than column=f1:count, timestamp=, value=
that column=f1:count, timestamp=, value=
the column=f1:count, timestamp=, value=
thousands column=f1:count, timestamp=, value=
to column=f1:count, timestamp=, value=
top column=f1:count, timestamp=, value=
up column=f1:count, timestamp=, value=
using column=f1:count, timestamp=, value=
which column=f1:count, timestamp=, value=
row(s) in 0.1600 seconds hbase(main)::>
hbase(main):016:0> scan 'yinzhengjie:WordCount2'
Hadoop生态圈-使用MapReduce处理HBase数据的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 使用MapReduce读取HBase数据存储到MySQL
Mapper读取HBase数据 package MapReduce; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hba ...
- hadoop2的mapreduce操作hbase数据
1.从hbase中取数据,再把计算结果插入hbase中 package com.yeliang; import java.io.IOException; import org.apache.hadoo ...
- 大数据和Hadoop生态圈
大数据和Hadoop生态圈 一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop ...
- Hadoop专业解决方案-第1章 大数据和Hadoop生态圈
一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop生态圈小组已经翻译完成,在此 ...
- 脱离JVM? Hadoop生态圈的挣扎与演化
本文由知乎<大数据应用与实践>专栏 李呈祥授权发布,版权所有归作者,转载请联系作者! 新世纪以来,互联网及个人终端的普及,传统行业的信息化及物联网的发展等产业变化产生了大量的数据,远远超出 ...
- Hadoop生态圈介绍及入门(转)
本帖最后由 howtodown 于 2015-4-2 23:15 编辑 问题导读 1.Hadoop生态圈介绍了哪些组件,分别都是什么? 2.大数据与Hadoop是什么关系? 本章主要内容: 理解大数据 ...
- Hbase框架原理及相关的知识点理解、Hbase访问MapReduce、Hbase访问Java API、Hbase shell及Hbase性能优化总结
转自:http://blog.csdn.net/zhongwen7710/article/details/39577431 本blog的内容包含: 第一部分:Hbase框架原理理解 第二部分:Hbas ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
随机推荐
- TeamWork#1,Week 2,Learn In Team
我觉得做为一个团队,每个人的能力固然重要,但是更重要的是几个人能同心协力. 俗话说“三个臭皮匠,赛过诸葛亮”,团队合作往往能激发出团体不可思议的潜力,集体协作干出的成果往往能超过成员个人业绩的总和.在 ...
- BugPhobia准备篇章:Beta阶段前后端接口文档
0x00:序言 Two strangers fell in love, Only one knows it wasn’t by chance. To the searching tags, you m ...
- 20172325 2017-2018-2 《Java程序设计》第五周学习总结
20172325 2017-2018-2 <Java程序设计>第五周学习总结 教材学习内容总结 1.布尔表达式的值只有真或假,表达式的结果决定了下一步将要执行的语句. 2.循环语句可以用在 ...
- 判断二叉树B是否是树A的子树
如下图所示,则认为树B是树A的子树. 代码如下: /** public class TreeNode { int val = 0; TreeNode left = null; TreeNode rig ...
- 深入理解Java虚拟机 &GC分代年龄
堆内存 Java 中的堆是 JVM 所管理的最大的一块内存空间,主要用于存放各种类的实例对象.在 Java 中,堆被划分成两个不同的区域:新生代 ( Young ).老年代 ( Old ).新生代 ( ...
- profibus 的DPV0 和DPV1
DP的功能经过扩展,一共有3个版本:DP-V0,DP-V1和DP-V2.有的用户手册将DP-V1简写为DPV1. 1.基本功能(DP-V0) (1)总线访问方法:各主站之间为令牌传送,主站与从站间为主 ...
- linux创建账户并自动生成主目录和主目录下的文件
# useradd -d /home/test -m test; 然后给test设置密码. # passwd test; 1. useradd 添加用户或更新新创建用户的默认信息 语法:useradd ...
- js框架总结
参考地址 http://www.techweb.com.cn/network/system/2015-12-23/2245809.shtml https://www.cnblogs.com/mbail ...
- 第218天:Angular---模块和控制器
1.使用NG实现双边数据绑定 所有需要ng管理的代码必须被包裹在一个有ng-app指令的元素中ng-app是ng的入口,表示当前元素的所有指令都会被angular管理(对每一个指令进行分析和操作) & ...
- BZOJ5120 无限之环(费用流)
方案合法相当于要求接口之间配对,黑白染色一波,考虑网络流.有一个很奇怪的限制是不能旋转直线型水管,考虑非直线型水管有什么特殊性,可以发现其接口都是连续的.那么对于旋转水管,可以看做是把顺/逆时针方向上 ...