基于Lucene的全文检索实践
由于项目的需要,使用到了全文检索技术,这里将前段时间所做的工作进行一个实践总结,方便以后查阅。在实际的工作中,需要灵活的使用lucene里面的查询技术,以达到满足业务要求与搜索性能提升的目的。
一、全文检索介绍
1.1为什么需要全文检索
数据可以分为结构化数据和非结构化数据,对数据查询时,结构化数据可以通过SQL语句等方式查询,而非结构化数据(如txt,word等)无法用此方式查询。
我们利用将非结构化数据转化为非结构化数据(即先将文件中单词按空格拆分,把单词创建一个索引,然后查询索引,根据单词和文档的关系找到文档列表,即全文检索),进行快速查询。
1.2什么是全文检索
先创建索引,然后查询索引的过程是全文检索
具有一次创建,多次使用的特点(创建的速度有点慢)。
二、全文检索流程
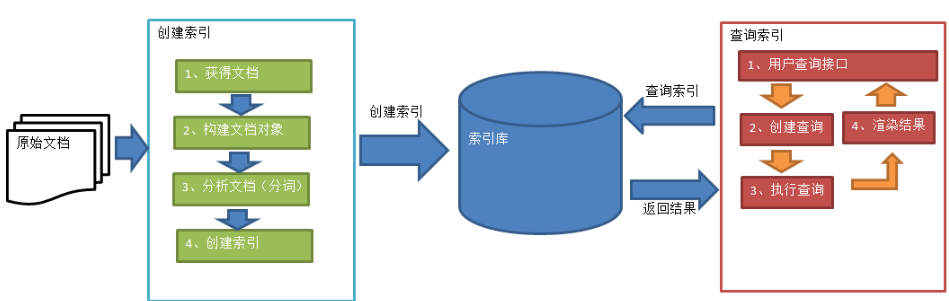
1. 绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:确定原始内容即要搜索的内容→采集文档→创建文档→分析文档→索引文档。
2. 红色表示搜索过程,从索引库中搜索内容,搜索过程包括:用户通过搜索界面→创建查询→执行搜索,从索引库搜索→渲染搜索结果。
三、全文检索索引
3.1倒排索引
倒排索引即为全文检索的核心的部分,所谓倒排索引,简单地就是,根据单词,返回它在哪个文件中出现过,而且频率是多少的结果。这就像百度里的搜索,你输入一个关键字,那么百度引擎就迅速的在它的服务器里找到有该关键字的文件,并根据频率和其他的一些策略(如页面点击投票率)等来给你返回结果。这个过程中,倒排索引就起到很关键的作用。

3.2创建索引
你可以利用你的技术从数据库、互联网、爬虫、word等方式获取原始数据,即采集信息
3.3构建索引文档
对应每个原始文档创建一个Document对象(拥有唯一的ID)
每个Document中包含多个Field
不同的Document可以有不同的Field
同一个Document可以有相同的Field
域中以键值对的形式保存域的名称和值
四、全文检索使用
1、所需核心库
|
lucene-core |
lucene核心库 |
|
lucene-queryparser |
lucene查询解析器 |
|
lucene-analyzers-common |
lucene默认分词器 |
|
lucene-analyzers-smartcn |
lucene提供的中文分词器 |
|
ik-analyzer |
开源中文分词器 |
2、lucene查询
|
查询方式 |
意义 |
| TermQuery | 精确查询 |
| TermRangeQuery | 查询一个范围 |
| PrefixQuery | 前缀匹配查询 |
| WildcardQuery | 通配符查询 |
| BooleanQuery | 多条件查询 |
| PhraseQuery | 短语查询 |
| FuzzyQuery | 模糊查询 |
| Queryparser | 万能查询(上面的都可以用这个来查询到 |
基于Lucene的全文检索实践的更多相关文章
- Lucene:基于Java的全文检索引擎简介
Lucene:基于Java的全文检索引擎简介 Lucene是一个基于Java的全文索引工具包. 基于Java的全文索引/检索引擎--Lucene Lucene不是一个完整的全文索引应用,而是是一个用J ...
- Lucene:基于Java的全文检索引擎简介 (zhuan)
http://www.chedong.com/tech/lucene.html ********************************************** Lucene是一个基于Ja ...
- 聊聊基于Lucene的搜索引擎核心技术实践
最近公司用到了ES搜索引擎,由于ES是基于Lucene的企业搜索引擎,无意间在“聊聊架构”微信公众号里发现了这篇文章,分享给大家. 请点击链接:聊聊基于Lucene的搜索引擎核心技术实践
- Lucene5.5.4入门以及基于Lucene实现博客搜索功能
前言 一直以来个人博客的搜索功能很蹩脚,只是自己简单用数据库的like %keyword%来实现的,所以导致经常搜不到想要找的内容,而且高亮显示.摘要截取等也不好实现,所以决定采用Lucene改写博客 ...
- JAVAEE——Lucene基础:什么是全文检索、Lucene实现全文检索的流程、配置开发环境、索引库创建与管理
1. 学习计划 第一天:Lucene的基础知识 1.案例分析:什么是全文检索,如何实现全文检索 2.Lucene实现全文检索的流程 a) 创建索引 b) 查询索引 3.配置开发环境 4.创建索引库 5 ...
- 通通WPF随笔(1)——基于lucene.NET让ComboBox拥有强大的下拉联想功能
原文:通通WPF随笔(1)--基于lucene.NET让ComboBox拥有强大的下拉联想功能 我一直很疑惑百度.谷哥搜索框的下拉联想功能是怎么实现的?是不断地查询数据库吗?其实到现在我也不知道,他们 ...
- Lucene的全文检索学习
Lucene的官方网站(Apache的顶级项目):http://lucene.apache.org/ 1.什么是Lucene? Lucene 是 apache 软件基金会的一个子项目,由 Doug C ...
- C#编写了一个基于Lucene.Net的搜索引擎查询通用工具类:SearchEngineUtil
最近由于工作原因,一直忙于公司的各种项目(大部份都是基于spring cloud的微服务项目),故有一段时间没有与大家分享总结最近的技术研究成果的,其实最近我一直在不断的深入研究学习Spring.Sp ...
- WebGIS中兴趣点简单查询、基于Lucene分词查询的设计和实现
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/. 1.前言 兴趣点查询是指:输入框中输入地名.人名等查询信息后,地图上可 ...
随机推荐
- jmeter5.2版本 配置元件之参数化详解
1.方式1 :CSV Data Set Config : 打开方式:配置元件---csv data set config 作用:用于读取txt.csv文件数据,注意:默认txt.csv文件的第一行内容 ...
- spring入门2-aop和集成测试
1.AOP开发 1.1.简述 作用:面向切面编程:在程序运行期间,在不修改源码的情况下对代码进行增强 优势:减少代码重复,提高开发效率,便于维护 底层:动态代理实现(jdk动态代理,cglib动态代理 ...
- 痞子衡嵌入式:MCUBootUtility v3.4发布,支持串行NAND
-- 痞子衡维护的 NXP-MCUBootUtility 工具距离上一个大版本(v3.3.0)发布过去 4 个多月了,这一次痞子衡为大家带来了版本升级 v3.4.0,这个版本主要有几个非常重要的更新需 ...
- Linux学习笔记整理-1
内核检测常用的7个命令: fdisk命令:用于检查磁盘使用情况,以及可以对磁盘进行分区. #fdisk -l 列出系统内所有能找到的设备的分区 #fdisk /dev/sda 列出sda磁盘的分区情况 ...
- 使用CEF(三)— 从CEF官方Demo源码入手解析CEF架构与CefApp、CefClient对象
在上文<使用CEF(2)- 基于VS2019编写一个简单CEF样例>中,我们介绍了如何编写一个CEF的样例,在文章中提供了一些代码清单,在这些代码清单中提到了一些CEF的定义的类,例如Ce ...
- 洛谷1429 平面最近点对(KDTree)
qwq(明明可以直接分治过掉的) 但是还是当作联系了 首先,对于这种点的题,很显然的套路,我们要维护一个子树\(mx[i],mn[i]\)分别表示每个维度的最大值和最小值 (这里有一个要注意的东西!就 ...
- android和IOS自动化定位方法
元素定位 方法:id定位,name定位(text定位),class_name定位, accessibility_id定位,xpath定位等 (目前1.5版本的已经不支持name定位了),所以APP的定 ...
- VMware中Linux虚拟机与Windows主机共享文件夹
VMware下Linux虚拟机与Windows主机共享文件夹 1. 安装vm-tool 2. 开启共享文件夹 虚拟机->设置->选项->共享文件夹"右边选择"总是 ...
- 流量治理神器-Sentinel的限流模式,选单机还是集群?
大家好,架构摆渡人.这是我的第5篇原创文章,还请多多支持. 上篇文章给大家推荐了一些限流的框架,如果说硬要我推荐一款,我会推荐Sentinel,Sentinel的限流模式分为两种,分别是单机模式和集群 ...
- PTA实验4-2-3 验证“哥德巴赫猜想” (20分)
实验4-2-3 验证"哥德巴赫猜想" (20分) 数学领域著名的"哥德巴赫猜想"的大致意思是:任何一个大于2的偶数总能表示为两个素数之和.比如:24=5+19, ...