hive学习笔记之六:HiveQL基础
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
《hive学习笔记》系列导航
本篇概览
- 本文是《hive学习笔记》系列的第六篇,前面的文章咱们对数据类型、表结构有了基本了解,接下来对常用的查询语句做一次集中式的学习;
- HiveQL与SQL类似, 在语法上与大部分SQL兼容, 但是并非完全兼容,例如更新、事务等都不支持,子查询和join操作也有限, 这和底层依赖Hadoop有关;
准备数据
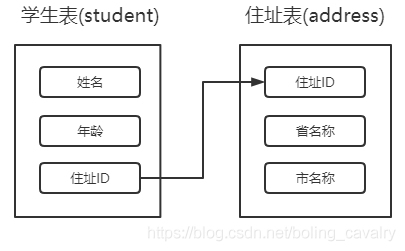
- 本次实战要准备两个表:学生表和住址表,字段都很简单,如下图所示,学生表有个住址ID字段,是住址表里的记录的唯一ID:
2. 先创建住址表:
create table address (addressid int, province string, city string)
row format delimited
fields terminated by ',';
- 创建address.txt文件,内容如下:
1,guangdong,guangzhou
2,guangdong,shenzhen
3,shanxi,xian
4,shanxi,hanzhong
6,jiangshu,nanjing
- 加载数据到address表:
load data
local inpath '/home/hadoop/temp/202010/25/address.txt'
into table address;
- 创建学生表,其addressid字段关联了address表的addressid字段:
create table student (name string, age int, addressid int)
row format delimited
fields terminated by ',';
- 创建student.txt文件,内容如下:
tom,11,1
jerry,12,2
mike,13,3
john,14,4
mary,15,5
- 加载数据到student表:
load data
local inpath '/home/hadoop/temp/202010/25/student.txt'
into table student;
- 至此,本次操作所需数据已准备完毕,如下所示:
hive> select * from address;
OK
1 guangdong guangzhou
2 guangdong shenzhen
3 shanxi xian
4 shanxi hanzhong
6 jiangshu nanjing
Time taken: 0.043 seconds, Fetched: 5 row(s)
hive> select * from student;
OK
tom 11 1
jerry 12 2
mike 13 3
john 14 4
mary 15 5
Time taken: 0.068 seconds, Fetched: 5 row(s)
- 开始体验HiveQL
select和where
最普通的带条件查询:
hive> select * from address where city like '%a%';
OK
1 guangdong guangzhou
3 shanxi xian
4 shanxi hanzhong
6 jiangshu nanjing
Time taken: 0.128 seconds, Fetched: 4 row(s)
group by
- 按province字段分组:
select province, count(*) from address group by province;
该查询会触发MR计算,结果如下:
...
Total MapReduce CPU Time Spent: 1 seconds 910 msec
OK
guangdong 2
jiangshu 1
shanxi 2
Time taken: 17.847 seconds, Fetched: 3 row(s)
- 试试嵌套查询,内部是查出city字段带有a字母的记录,然后将这些记录按照province字段分组:
select t.province, count(*) from (
select * from address where city like '%a%'
) t
group by t.province;
结果如下:
Total MapReduce CPU Time Spent: 1 seconds 760 msec
OK
guangdong 1
jiangshu 1
shanxi 2
Time taken: 18.036 seconds, Fetched: 3 row(s)
having
- 前面的嵌套查询,结果有两个省:guangdong和shanxi,如果再加个条件:只显示城市数量大于1的省,首先想到的是再加一层嵌套:
select t1.* from (
select t.province, count(*) as cnt from (
select * from address where city like '%a%'
) t
group by t.province) t1
where t1.cnt>1;
结果如下,可见只有shanxi被显示了:
Total MapReduce CPU Time Spent: 2 seconds 250 msec
OK
shanxi 2
Time taken: 20.067 seconds, Fetched: 1 row(s)
- 对于上述SQL,可以用having语法进行分组筛选,得到同样数据:
select t.province, count(*) as cnt from (
select * from address where city like '%a%'
) t
group by t.province having cnt>1;
order by
- 对分组结果做排序:
select t.province, count(*) as cnt from (
select * from address where city like '%a%'
) t
group by t.province order by cnt;
会触发MR,结果如下:
Total MapReduce CPU Time Spent: 3 seconds 50 msec
OK
jiangshu 1
guangdong 1
shanxi 2
Time taken: 40.315 seconds, Fetched: 3 row(s)
- order by对于的实现,是在最后通过一个reducer进行全部排序,该过程可能耗时较长,针对这种情况,hive提供了sort by,功能与order by一样,但是会在每个reducer中进行排序,这样最终做排序的时候效率就会提升;
- 要注意的是:sort by解决的问题是最终结果排序的效率,因此数据量不大时,排序不是瓶颈,此时使用sort by也不会加快整体速度;
内连接(inner join)
- 内连接用join简写,与连接标准匹配的数据在两张表中都存在,才会保留:
select
s.name, s.age,
a.province, a.city
from
student s
inner join
address a
on
s.addressid=a.addressid;
结果如下:
Total MapReduce CPU Time Spent: 1 seconds 20 msec
OK
tom 11 guangdong guangzhou
jerry 12 guangdong shenzhen
mike 13 shanxi xian
john 14 shanxi hanzhong
Time taken: 17.294 seconds, Fetched: 4 row(s)
自然连接(natural join)
- 自然连接是在两张表中寻找数据类型和列明都相同的字段,并自动连接起来:
select name, age, province, city from student natural join address;
结果如下,可见不会根据student表的addressid字段值去address查找记录,而是将addrerss的记录全部连接一次:
Total MapReduce CPU Time Spent: 940 msec
OK
tom 11 guangdong guangzhou
jerry 12 guangdong guangzhou
mike 13 guangdong guangzhou
john 14 guangdong guangzhou
mary 15 guangdong guangzhou
tom 11 guangdong shenzhen
jerry 12 guangdong shenzhen
mike 13 guangdong shenzhen
john 14 guangdong shenzhen
mary 15 guangdong shenzhen
tom 11 shanxi xian
jerry 12 shanxi xian
mike 13 shanxi xian
john 14 shanxi xian
mary 15 shanxi xian
tom 11 shanxi hanzhong
jerry 12 shanxi hanzhong
mike 13 shanxi hanzhong
john 14 shanxi hanzhong
mary 15 shanxi hanzhong
tom 11 jiangshu nanjing
jerry 12 jiangshu nanjing
mike 13 jiangshu nanjing
john 14 jiangshu nanjing
mary 15 jiangshu nanjing
Time taken: 18.525 seconds, Fetched: 25 row(s)
左外连接(left outer join)
- 以连接中的左表为主:
select
s.name, s.age, s.addressid,
a.province, a.city
from
student s
left outer join
address a
on
s.addressid=a.addressid;
结果如下,可见name=mary的记录,addressid等于5,在address中不存在addressid等于5的记录,因此province和city字段都展示了NULL,而在前面使用inner join时,结果中没有这条记录:
Total MapReduce CPU Time Spent: 950 msec
OK
tom 11 1 guangdong guangzhou
jerry 12 2 guangdong shenzhen
mike 13 3 shanxi xian
john 14 4 shanxi hanzhong
mary 15 5 NULL NULL
Time taken: 18.442 seconds, Fetched: 5 row(s)
右外连接(right outer join)
和左连接类似,只不过是以右表为主,语法是right outer join:
select
s.name, s.age, s.addressid,
a.province, a.city
from
student s
right outer join
address a
on
s.addressid=a.addressid;
结果如下,可见city=nanjing的记录,在student表中没有一条记录与之关联,因此结果中展示了address的字段,而student的字段为NULL:
Total MapReduce CPU Time Spent: 970 msec
OK
tom 11 1 guangdong guangzhou
jerry 12 2 guangdong shenzhen
mike 13 3 shanxi xian
john 14 4 shanxi hanzhong
NULL NULL NULL jiangshu nanjing
Time taken: 18.294 seconds, Fetched: 5 row(s)
全外连接(full outer join)
查询结果等于左外连接和右外连接之和,语法是full outer join:
select
s.name, s.age, s.addressid,
a.province, a.city
from
student s
full outer join
address a
on
s.addressid=a.addressid;
结果如下:
Total MapReduce CPU Time Spent: 2 seconds 630 msec
OK
tom 11 1 guangdong guangzhou
jerry 12 2 guangdong shenzhen
mike 13 3 shanxi xian
john 14 4 shanxi hanzhong
mary 15 5 NULL NULL
NULL NULL NULL jiangshu nanjing
Time taken: 22.189 seconds, Fetched: 6 row(s)
- 至此,常用HiveQL体验完毕,希望能给您一些参考,接下来的章节会进一步学习HiveQL的特性;
你不孤单,欣宸原创一路相伴
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
hive学习笔记之六:HiveQL基础的更多相关文章
- hive学习笔记之九:基础UDF
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之一:基本数据类型
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之三:内部表和外部表
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之四:分区表
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之五:分桶
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之七:内置函数
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- Java学习笔记:语言基础
Java学习笔记:语言基础 2014-1-31 最近开始学习Java,目的倒不在于想深入的掌握Java开发,而是想了解Java的基本语法,可以阅读Java源代码,从而拓展一些知识面.同时为学习An ...
- 【Visual C++】游戏编程学习笔记之六:多背景循环动画
本系列文章由@二货梦想家张程 所写,转载请注明出处. 本文章链接:http://blog.csdn.net/terence1212/article/details/44264153 作者:ZeeCod ...
随机推荐
- envoy 官方example运行失败问题处理
镜像内安装包失败处理 方法一:修改Dockerfile,在Dockerfile中增加如下 ubuntu示例 RUN sed -i 's/archive.ubuntu.com/mirrors.aliyu ...
- [bug] IDEA 右侧模块灰色
参考 https://blog.csdn.net/weixin_44188501/article/details/104717177
- [BD] HBase
NoSQL数据库 关系型数据库:用表格的行-列来保存数据,OLTP,写入多,行式存储 非关系型数据库:只用来存储数据,业务逻辑由应用程序处理,OLAP,查询多,列式存储 常见NoSQL数据库 Redi ...
- [刷题] PTA 6-11 求自定类型元素序列的中位数 (25分)
采用希尔排序 1 #include <stdio.h> 2 3 #define MAXN 10 4 typedef float ElementType; 5 6 ElementType M ...
- RHEL sosreport
RHEL sosreport简介 sosreport对很多RedHat爱好者来说应该并不陌生! 它是一款在RedHat Linux下帮你收集系统信息打成一个tar包的工具,你可以将这个tar包发给供应 ...
- linux安装命令行 图形查看 CPU温度 传感器-20191218
方法1:命令行sensors # sensorsi350bb-pci-0700Adapter: PCI adapterloc1: +46.0°C (high = +120.0°C, crit = +1 ...
- mysql数据库-备份与还原实操
目录 备份工具 1 基于 LVM 的快照备份(几乎热备) 2 数据库冷备份和还原 3 mysqldump备份工具 3.1 实战备份策略 3.1.1 全备份 3.1.2 分库分表备份 3.2 mysql ...
- Jaxb的优点与用法(bean转xml的插件,简化webservice接口的开发工作量)
一.jaxb是什么 JAXB是Java Architecture for XML Binding的缩写.可以将一个Java对象转变成为XML格式,反之亦然. 我们把对象与关系数据库之间的映射称 ...
- 西门子 S7-200 通过以太网通讯模块连接MCGS 通讯
北京华科远创科技有限研发的远创智控ETH-YC模块,以太网通讯模块型号有MPI-ETH-YC01和PPI-ETH-YC01,适用于西门子S7-200/S7-300/S7-400.SMART S7-20 ...
- 第四代自动泊车从APA到AVP技术
第四代自动泊车从APA到AVP技术 前言 自动泊车是指汽车自动泊车入位不需要人工控制,系统能够自动帮你将车辆停入车位,在倒车入库中可谓是驾驶者的一项利器.当我们找到一个理想的停车地点,只需轻轻启动按钮 ...