elasticsearch使用ik中文分词器
elasticsearch使用ik中文分词器
一、背景
es自带了一堆的分词器,比如standard、whitespace、language(比如english)等分词器,但是都对中文分词的效果不太好,此处安装第三方分词器ik,来实现分词。
二、安装 ik 分词器
1、从 github 上找到和本次 es 版本匹配上的 分词器
# 下载地址
https://github.com/medcl/elasticsearch-analysis-ik/releases
2、使用 es 自带的插件管理 elasticsearch-plugin 来进行安装
- 直接从网络地址安装
cd /Users/huan/soft/elastic-stack/es/es02/bin
# 下载插件
./elasticsearch-plugin -v install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.0/elasticsearch-analysis-ik-7.12.0.zip
# 查看插件是否下载成功
./elasticsearch-plugin list
- 从本地安装
cd /Users/huan/soft/elastic-stack/es/es02/bin
# 下载插件(file后面跟的是插件在本地的地址)
./elasticsearch-plugin install file:///path/to/plugin.zip
注意:
如果本地插件的路径中存在空格,需要使用双引号包装起来。
3、重启es
# 查找es进程
jps -l | grep 'Elasticsearch'
# 杀掉es进程
kill pid
# 启动es
/Users/huan/soft/elastic-stack/es/es01/bin/elasticsearch -d -p pid01
三、测试 ik 分词
ik分词器提供了2种分词的模式
ik_max_word: 将需要分词的文本做最小粒度的拆分,尽量分更多的词。ik_smart: 将需要分词的文本做最大粒度的拆分。
1、测试默认的分词效果
语句
GET _analyze
{
"analyzer": "default",
"text": ["中文分词语"]
}
结果
{
"tokens" : [
{
"token" : "中",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "文",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "分",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "词",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "语",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}
可以看到默认的分词器,对中文的分词完全无法达到我们中文的分词的效果。
2、测试 ik_max_word 的分词效果
语句
GET _analyze
{
"analyzer": "ik_max_word",
"text": ["中文分词语"]
}
结果
{
"tokens" : [
{
"token" : "中文",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "分词",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "词语",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
可以看到基于ik分词可以达到我们需要的分词效果。
3、测试 ik_smart 的分词效果
语句
GET _analyze
{
"analyzer": "ik_smart",
"text": ["中文分词语"]
}
结果
{
"tokens" : [
{
"token" : "中文",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "分",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "词语",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
4、自定义 ik 的启用词和停用词
1、找到 ik 的配置目录
${IK_HOME}/config/analysis-ik
/Users/huan/soft/elastic-stack/es/es01/config/analysis-ik
2、修改 IKAnalyzer.cfg.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom-ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom-stop.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
3、custom-ext.dic 和 custom-stop.dic 的内容

注意:
1、自定义分词的文件必须是UTF-8的编码。
4、配置文件完整路径
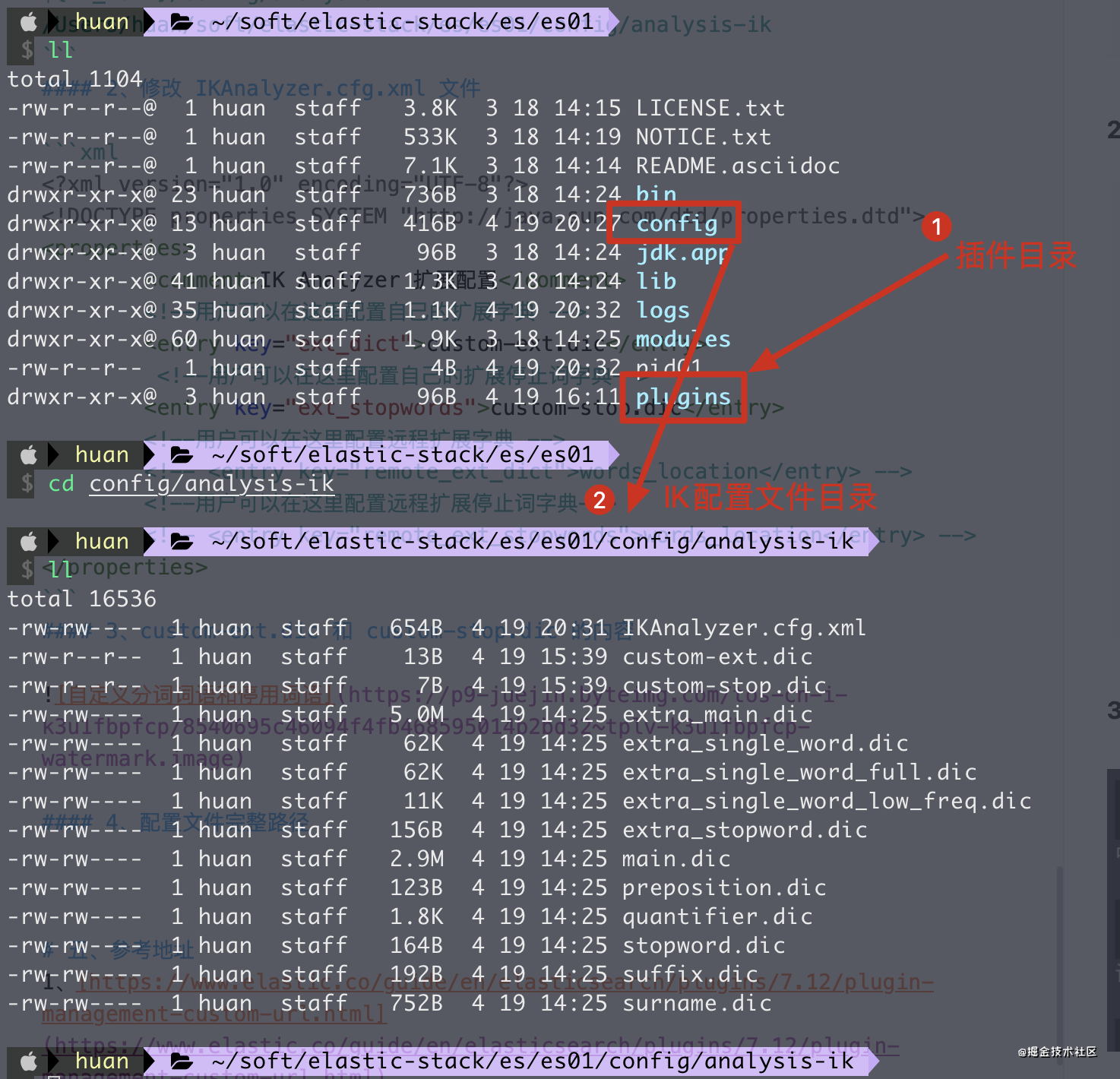
5、查看分词结果

5、热更新IK分词
1、修改 IKAnalyzer.cfg.xml 文件,配置远程字典。
$ cat /Users/huan/soft/elastic-stack/es/es01/config/analysis-ik/IKAnalyzer.cfg.xml 11.87s 16.48G 2.68
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://localhost:8686/custom-ext.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords"></entry>
</properties>
注意:
1、此处的 custom-ext.dic 文件在下方将会配置到 nginx中,保证可以访问。
2、http 请求需要返回两个头部(header),一个是 Last-Modified,一个是 ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
3、http 请求返回的内容格式是一行一个分词,换行符用 \n 即可。
4、在 nginx 的目录下放置一个 custom-ext.dic 文件
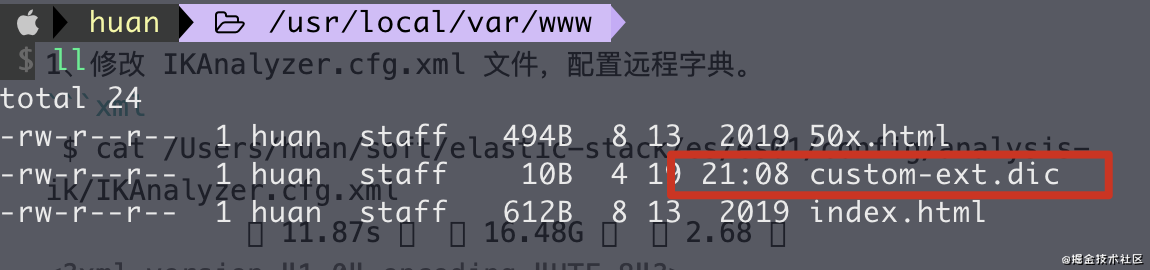
多次修改 custom-ext.dic 文件,可以看到分词的结果也会实时变化,如此就实现了分词的热更新。
五、参考地址
1、https://www.elastic.co/guide/en/elasticsearch/plugins/7.12/plugin-management-custom-url.html
2、https://github.com/medcl/elasticsearch-analysis-ik/releases
3、https://github.com/medcl/elasticsearch-analysis-ik
elasticsearch使用ik中文分词器的更多相关文章
- Elasticsearch:IK中文分词器
Elasticsearch内置的分词器对中文不友好,只会一个字一个字的分,无法形成词语,比如: POST /_analyze { "text": "我爱北京天安门&quo ...
- elasticsearch ik中文分词器安装
特殊说明:灰色文字用来辅助理解的. 安装IK中文分词器 我在百度上搜索了下,大多介绍的都是用maven打包下载下来的源码,这种方法也行,但是不够方便,为什么这么说? 首先需要安装maven吧?其次需要 ...
- ElasticSearch速学 - IK中文分词器远程字典设置
前面已经对”IK中文分词器“有了简单的了解: 但是可以发现不是对所有的词都能很好的区分,比如: 逼格这个词就没有分出来. 词库 实际上IK分词器也是根据一些词库来进行分词的,我们可以丰富这个词库. ...
- 搜索引擎ElasticSearch系列(五): ElasticSearch2.4.4 IK中文分词器插件安装
一:IK分词器简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
- ES-Mac OS环境搭建-ik中文分词器
下载 从github下载ik中文分词器,点击地址,需要注意的是,ik分词器和elasticsearch版本必须一致. 安装 下载到本地并解压到elasticsearch中的plugins目录内即可. ...
- 30.IK中文分词器的安装和简单使用
在之前我们学的都是英文,用的也是英文的standard分词器.从这一节开始,学习中文分词器.中国人基本上都是中文应用,很少是英文的,而standard分词器是没有办法对中文进行合理分词的,只是将每个中 ...
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
随机推荐
- SQL-DELETE触发器练习
&练习一 如下所示三张表( student,grade,student_updata_before ): student表 grade表 Student_update_before表 # 触发 ...
- RocketMQ详解(一)原理概览
专题目录 RocketMQ详解(一)原理概览 RocketMQ详解(二)安装使用详解 RocketMQ详解(三)启动运行原理 RocketMQ详解(四)核心设计原理 RocketMQ详解(五)总结提高 ...
- 安装Centos7,出现无法联网的问题-----解决办法
安装Centos7,出现无法联网的问题-----解决办法 我安装的是centos7的版本 在我照着centos7安装教程-CentOS-PHP中文网这个教程安装完后 我发现我的centOS无法联网,在 ...
- 学习PHP中好玩的Gmagick图像操作扩展的使用
在 PHP 的图像处理领域,要说最出名的 GD 库为什么好,那就是因为它不需要额外安装的别的什么图像处理工具,而且是随 PHP 源码一起发布的,只需要在安装 PHP 的时候添加上编译参数就可以了. G ...
- learn git(远程仓库github)
|由于本地Git仓库和GitHub仓库之间的传输是通过SSH加密的,所以,需要一点设置: 第1步:创建SSH Key.在用户主目录下,看看有没有.ssh目录,如果有,再看看这个目录下有没有id_rsa ...
- IDEA - 2019中文版安装教程
前言 个人安装备忘录 软件简介 IDEA 全称IntelliJ IDEA,是java语言开发的集成环境,在业界被公认为最好的java开发工具之一,尤其在智能代码助手.代码自动提示.重构.J2EE支持. ...
- Ubuntu学习之alias命令
Ubuntu学习之alias命令 1.1 alias功能介绍 当我们经常需要在命令窗键入复杂冗长的命令时,alias就派上用场啦.alias允许用户为命令创建简单的名称或缩写,哪怕这个缩写只有一个字符 ...
- P4716-[模板]最小树形图
正题 题目链接:https://www.luogu.com.cn/problem/P4716 题目大意 给出\(n\)个点\(m\)条边的一张有向图,求以\(r\)为根的最小外向树. \(1\leq ...
- 2021“MINIEYE杯”中国大学生算法设计超级联赛(7)部分题解
前言 找大佬嫖到个号来划水打比赛了,有的题没写或者不是我写的就不放了. 目前只有:1004,1005,1007,1008,1011 正题 题目链接:https://acm.hdu.edu.cn/con ...
- P3643-[APIO2016]划艇【dp】
正题 题目链接:https://www.luogu.com.cn/problem/P3643 题目大意 求有多少个\(n\)个数的序列\(x\)满足,\(x_i\in \{0\}\cup[a_i,b_ ...