3 - 基于ELK的ElasticSearch 7.8.x技术整理 - 高级篇( 偏理论 )
4、ES高级篇
4.1、集群部署
- 集群的意思:就是将多个节点归为一体罢了( 这个整体就有一个指定的名字了 )
4.1.1、window中部署集群 - 了解即可
- 把下载好的window版的ES中的data文件夹、logs文件夹下的所有的文件删掉,然后拷贝成三份,对文件重命名
修改node-1001节点的config/elasticsearch.yml配置文件
这个配置文件里面有原生的配置信息,感兴趣的可以查看,因为现在要做的配置信息都在原生的配置信息里,只是被注释掉了而已,当然:没兴趣的,直接全选删掉,然后做如下配置
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
# 集群名称 注意:是把多个节点归为一个整体,所以这个集群名字就是各节点归为一体之后的名字
# 因此:各个节点中这个集群名字也就要一样了
cluster.name: es-colony
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
# 节点名称 在一个集群中,这个名字要全局唯一
node.name: node-1001
# 是否有资格成为主机节点
node.master: true
# 是否是数据节点
node.data: true
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
# 当前节点的ip地址
network.host: 127.0.0.1
#
# Set a custom port for HTTP:
# 当前节点的端口号
http.port: 1001
# 当前节点的通讯端口( 监听端口 )
transport.tcp.port: 9301
# 跨域配置
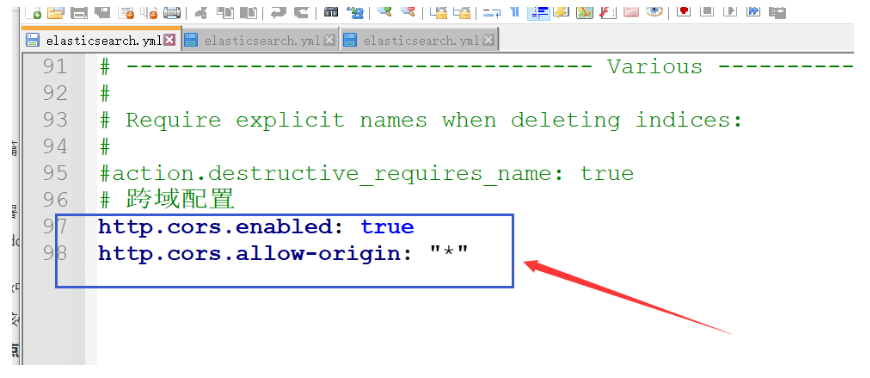
http.cors.enabled: true
http.cors.allow-origin: "*"
修改node-1002节点的config/elasticsearch.yml配置文件
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
# 集群名称 注意:是把多个节点归为一个整体,所以这个集群名字就是各节点归为一体之后的名字
# 因此:各个节点中这个集群名字也就要一样了
cluster.name: es-colony
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
# 节点名称 在一个集群中,这个名字要全局唯一
node.name: node-1002
# 是否是主机节点
node.master: true
# 是否是数据节点
node.data: true
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
# 当前节点的ip地址
network.host: 127.0.0.1
#
# Set a custom port for HTTP:
# 当前节点的端口号
http.port: 1002
# 当前节点的通讯端口( 监听端口 )
transport.tcp.port: 9302
# 当前节点不知道集群中另外节点是哪些涩,所以配置,让当前节点能够找到其他节点
discovery.seed_hosts: ["127.0.0.1:9301"]
# ping请求调用超时时间,但同时也是选主节点的delay time
discovery.zen.fd.ping_timeout: 1m
# 重试次数,防止GC[ 垃圾回收 ]节点不响应被剔除
discovery.zen.fd.ping_retries: 5
# 跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
修改node-1003节点的config/elasticsearch.yml配置文件
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
# 集群名称 注意:是把多个节点归为一个整体,所以这个集群名字就是各节点归为一体之后的名字
# 因此:各个节点中这个集群名字也就要一样了
cluster.name: es-colony
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
# 节点名称 在一个集群中,这个名字要全局唯一
node.name: node-1003
# 是否是主机节点
node.master: true
# 是否是数据节点
node.data: true
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
# 当前节点的ip地址
network.host: 127.0.0.1
#
# Set a custom port for HTTP:
# 当前节点的端口号
http.port: 1003
# 当前节点的通讯端口( 监听端口 )
transport.tcp.port: 9303
# 当前节点不知道集群中另外节点是哪些涩,所以配置,让当前节点能够找到其他节点
discovery.seed_hosts: ["127.0.0.1:9301","127.0.0.1:9302"]
# ping请求调用超时时间,但同时也是选主节点的delay time
discovery.zen.fd.ping_timeout: 1m
# 重试次数,防止GC[ 垃圾回收 ]节点不响应被剔除
discovery.zen.fd.ping_retries: 5
# 跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
依次启动1、2、3节点的bin/elasticsearch.bat即可启动集群
用postman测试集群
http://localhost:1001/_cluster/health # 请求方式:get
# 相应内容
{
"cluster_name": "es-colony",
"status": "green", # 重点查看位置 状态颜色
"timed_out": false,
"number_of_nodes": 3, # 重点查看位置 集群中的节点数量
"number_of_data_nodes": 3, # 重点查看位置 集群中的数据节点数量
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100.0
}
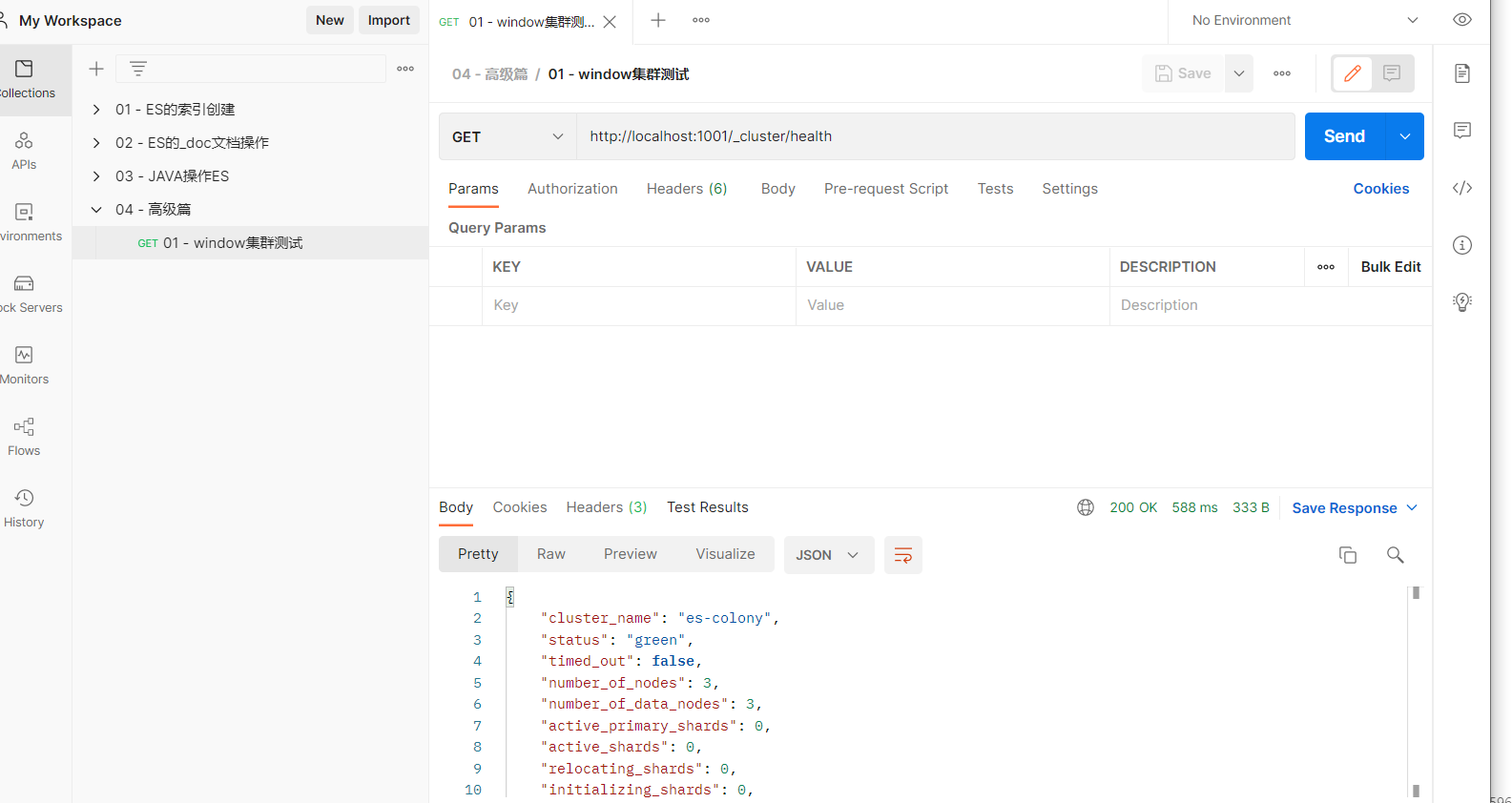
status字段颜色表示:当前集群在总体上是否工作正常。它的三种颜色含义如下:
- green:所有的主分片和副本分片都正常运行。
- yellow:所有的主分片都正常运行,但不是所有的副本分片都正常运行。
- red:有主分片没能正常运行
附加内容:一些配置说明,下面的一些配置目前有些人可能并没有遇到,但是在这里留个印象吧,知道个大概和怎么去找就行了
官网地址: https://www.elastic.co/guide/en/elasticsearch/reference/current/modules.html
1、主节点 [ host区域 ]:
cluster.name: elastics #定义集群名称所有节点统一配置
node.name: es-0 # 节点名称自定义
node.master: true # 主节点,数据节点设置为 false
node.data: false # 数据节点设置为true
path.data: /home/es/data
path.logs: /home/es/logs
bootstrap.mlockall: true #启动时锁定内存
network.publish_host: es-0
network.bind_host: es-0
http.port: 9200
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping_timeout: 120s
discovery.zen.minimum_master_nodes: 2 #至少要发现集群可做master的节点数,
client.transport.ping_timeout: 60s
discovery.zen.ping.unicast.hosts: ["es-0","es-1", "es-2","es-7","es-8","es-4","es-5","es-6"]
discovery.zen.fd.ping_timeout: 120s
discovery.zen.fd.ping_retries: 6
discovery.zen.fd.ping_interval: 30s
cluster.routing.allocation.disk.watermark.low: 100GB
cluster.routing.allocation.disk.watermark.high: 50GB
node.zone: hot #磁盘区域,分为hot和stale,做冷热分离
script.inline: true
script.indexed: true
cluster.routing.allocation.same_shard.host: true
threadpool.bulk.type: fixed
threadpool.bulk.size: 32
threadpool.bulk.queue_size: 100
threadpool.search.type: fixed
threadpool.search.size: 49
threadpool.search.queue_size: 10000
script.engine.groovy.inline.aggs: on
index.search.slowlog.threshold.query.warn: 20s
index.search.slowlog.threshold.query.info: 10s
index.search.slowlog.threshold.query.debug: 4s
index.search.slowlog.threshold.query.trace: 1s
index.search.slowlog.threshold.fetch.warn: 2s
index.search.slowlog.threshold.fetch.info: 1600ms
index.search.slowlog.threshold.fetch.debug: 500ms
index.search.slowlog.threshold.fetch.trace: 200ms
index.indexing.slowlog.threshold.index.warn: 20s
index.indexing.slowlog.threshold.index.info: 10s
index.indexing.slowlog.threshold.index.debug: 4s
index.indexing.slowlog.threshold.index.trace: 1s
indices.fielddata.cache.size: 20%
indices.fielddata.cache.expire: "48h"
indices.cache.filter.size: 10%
index.search.slowlog.level: WARN
数据节点 [ stale区域 ]
cluster.name: elastics # 集群名字
node.name: es-1 #节点名称
node.master: false # 不作为主节点,只存储数据
node.data: true # 做为数据节点
path.data: /data1/es-data,/data2/es-data,/data3/es-data # 存储目录,可配置多个磁盘
path.logs: /opt/es/logs # 日志目录
bootstrap.mlockall: true # 启动时锁定内存
network.publish_host: es-1 # 绑定网卡
network.bind_host: es-1 # 绑定网卡
http.port: 9200 # http端口
discovery.zen.ping.multicast.enabled: false # 禁用多播,夸网段不能用多播
discovery.zen.ping_timeout: 120s
discovery.zen.minimum_master_nodes: 2 # 至少要发现集群可做master的节点数
client.transport.ping_timeout: 60s
discovery.zen.ping.unicast.hosts: ["es-0","es-1", "es-2","es-7","es-8","es-4","es-5","es-6"] # 集群自动发现
# fd 是 fault detection
# discovery.zen.ping_timeout 仅在加入或者选举 master 主节点的时候才起作用;
# discovery.zen.fd.ping_timeout 在稳定运行的集群中,master检测所有节点,以及节点检测 master是否畅通时长期有用
discovery.zen.fd.ping_timeout: 120s # 超时时间(根据实际情况调整)
discovery.zen.fd.ping_retries: 6 # 重试次数,防止GC[垃圾回收]节点不响应被剔除
discovery.zen.fd.ping_interval: 30s # 运行间隔
# 控制磁盘使用的低水位。默认为85%,意味着如果节点磁盘使用超过85%,则ES不允许在分配新的分片。当配置具体的大小如100MB时,表示如果磁盘空间小于100MB不允许分配分片
cluster.routing.allocation.disk.watermark.low: 100GB #磁盘限额
# 控制磁盘使用的高水位。默认为90%,意味着如果磁盘空间使用高于90%时,ES将尝试分配分片到其他节点。上述两个配置可以使用API动态更新,ES每隔30s获取一次磁盘的使用信息,该值可以通过cluster.info.update.interval来设置
cluster.routing.allocation.disk.watermark.high: 50GB # 磁盘最低限额
node.zone: stale # 磁盘区域,分为hot和stale,做冷热分离
script.inline: true # 支持脚本
script.indexed: true
cluster.routing.allocation.same_shard.host: true #一台机器部署多个节点时防止一个分配到一台机器上,宕机导致丢失数据
threadpool.bulk.type: fixed # 以下6行为设置thread_pool
threadpool.bulk.size: 32
threadpool.bulk.queue_size: 100
threadpool.search.type: fixed
threadpool.search.size: 49
threadpool.search.queue_size: 10000
script.engine.groovy.inline.aggs: on
index.search.slowlog.threshold.query.warn: 20s # 以下为配置慢查询和慢索引的时间
index.search.slowlog.threshold.query.info: 10s
index.search.slowlog.threshold.query.debug: 4s
index.search.slowlog.threshold.query.trace: 1s
index.search.slowlog.threshold.fetch.warn: 2s
index.search.slowlog.threshold.fetch.info: 1600ms
index.search.slowlog.threshold.fetch.debug: 500ms
index.search.slowlog.threshold.fetch.trace: 200ms
index.indexing.slowlog.threshold.index.warn: 20s
index.indexing.slowlog.threshold.index.info: 10s
index.indexing.slowlog.threshold.index.debug: 4s
index.indexing.slowlog.threshold.index.trace: 1s
4.1.2、linux中部署ES
4.1.2.1、部署单机ES
- 准备工作
- 1、下载linux版的ES,自行百度进行下载,老规矩,我的版本是:7.8.0
- 2、将下载好的linux版ES放到自己的服务器中去
解压文件:命令 tar zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz
对文件重命名: 命令 mv elasticsearch-7.8.0 es

创建用户
因为安全问题, Elasticsearch 不允许 root 用户直接运行,所以要创建新用户,在 root 用户中创建新用户
点击查看代码
useradd es # 新增 es 用户
passwd es # 为 es 用户设置密码,输入此命令后,输入自己想设置的ES密码即可
userdel -r es # 如果错了,可以把用户删除了再重新加
chown -R es:es /opt/install/es # 文件授权 注意:/opt/install/es 改成自己的ES存放路径即可
- 修改 config/elasticsearch.yml 配置文件
点击查看代码
# 在elasticsearch.yml文件末尾加入如下配置
cluster.name: elasticsearch
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]

最后:保存 怕你是个大哥不会linux 操作方式 ——— 先按ESC 然后按shift+;分号 最后输入wq即可
后面懒得说操作方式,linux都不会的话,开什么玩笑
修改 /etc/security/limits.conf 文件 命令 vim /etc/security/limits.conf
点击查看代码
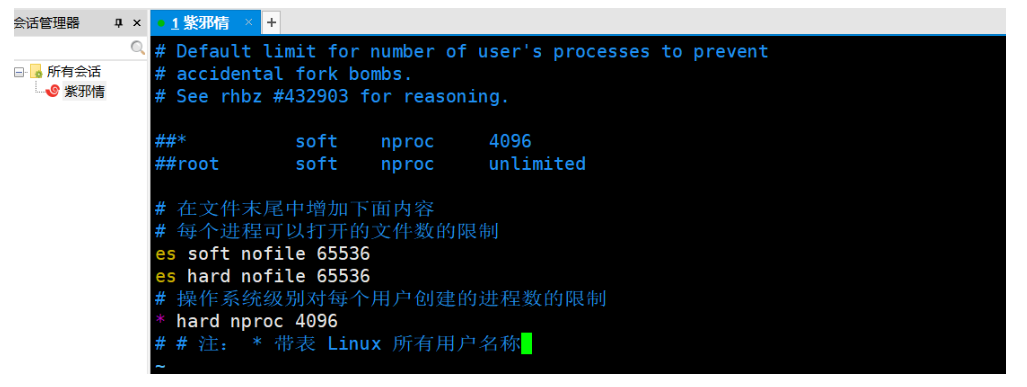
# 在文件末尾中增加下面内容
# 这个配置是:每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536
- 修改 /etc/security/limits.d/20-nproc.conf 文件 命令 vim /etc/security/limits.d/20-nproc.conf
点击查看代码
# 在文件末尾中增加下面内容
# 每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536
# 操作系统级别对每个用户创建的进程数的限制
* hard nproc 4096
# 注: * 表示 Linux 所有用户名称
- 修改 /etc/sysctl.conf 文件
点击查看代码
# 在文件中增加下面内容
# 一个进程可以拥有的 VMA(虚拟内存区域)的数量,默认值为 65536
vm.max_map_count=655360
- 重新加载文件
点击查看代码
# 命令
sysctl -p
启动程序 : 准备进入坑中
点击查看代码
cd /opt/install/es/
# 启动
bin/elasticsearch
# 后台启动
bin/elasticsearch -d
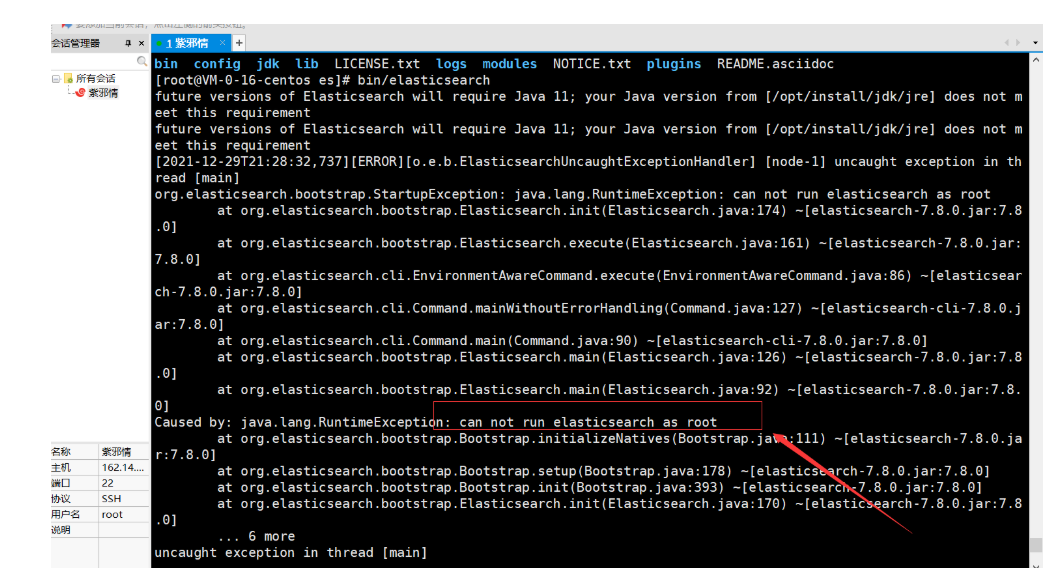
- 这个错误告知:不能用root用户,所以:切换到刚刚创建的es用户 命令 su es
- 然后再次启动程序,进入下一个坑
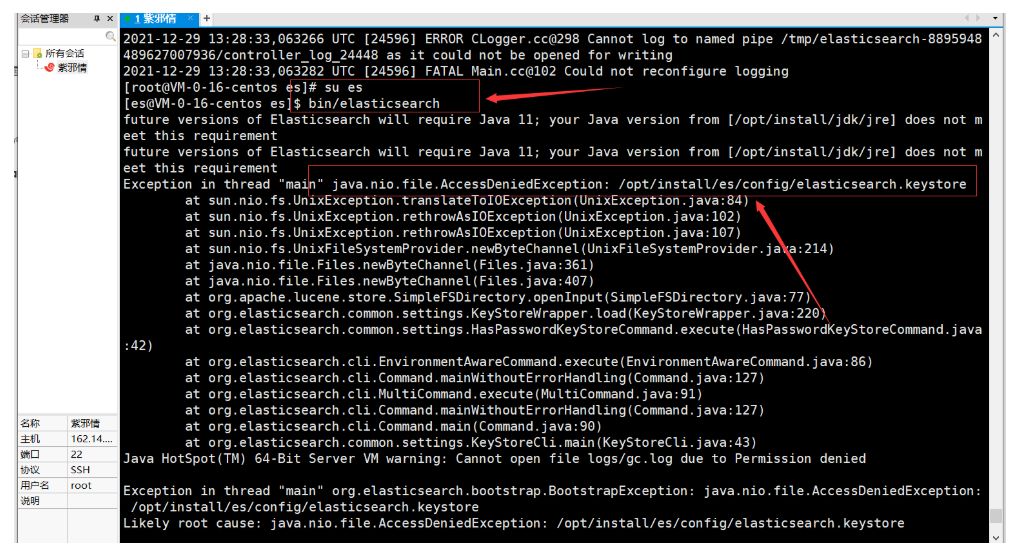
- 这个错误是因为:启动程序的时候会动态生成一些文件,这和ES没得关系,所以:需要切回到root用户,然后把文件权限再次刷新一下
点击查看代码
# 切换到root用户
su root
# 切换到root用户之后,执行此命令即可
chown -R es:es /opt/install/es
# 再切换到es用户
su es

再次启动程序
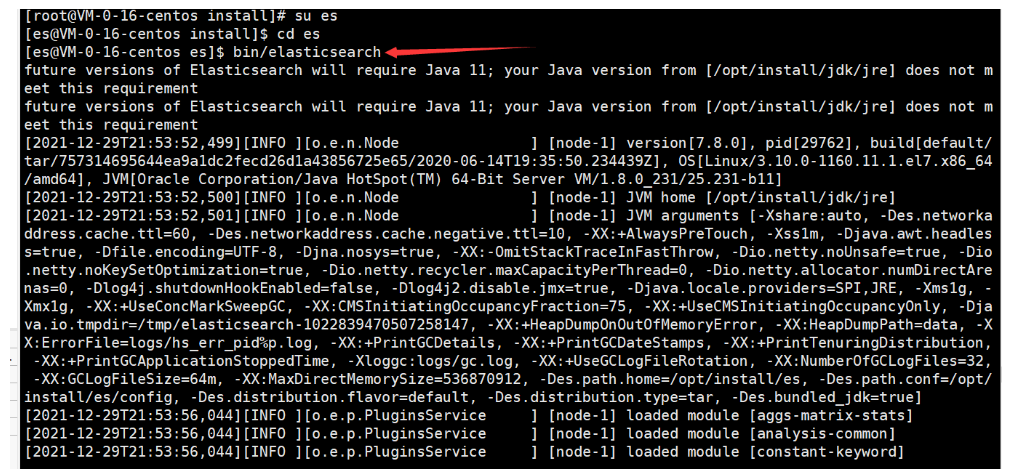
吃鸡,这样linux中单机ES就部署成功了
不过啊,前面这种方式都是low的方式,有更简单的方式,就是使用docker容器来进行配置,简直不要太简单,虽然:使用docker容器来启动程序有弊端,如:MySQL就不建议放在docker容器中,因为:MySQL是不断地进行io操作,放到docker容器中,就会让io操作效率降低,而ES放到docker中也是同样的道理,但是:可以玩,因为:有些公司其实并没有在意docker的弊端,管他三七二十一扔到docker中
- 如果想要用docker容器进行ES配置,编写如下的docker-compose.yml文件
点击查看代码
version: "3.1"
services:
elasticsearch:
image: daocloud.io/library/elasticsearch:7.9.0 # 注:此网站版本不全,可以直接用管我elasticsearch:7.8.0
restart: always
container_name: elasticsearch
ports:
- 9200:9200
environment:
- JAVA_OPTS=--Xms256m -Xmx1024m
然后启动容器即可
注:使用docker安装需要保证自己的linux中安装了docker和docker-compose,没有安装的话,教程链接如下:
测试是否成功
# 在浏览器和postman中输入以下指令均可
http://ip:9200/ # 注:ip是自己服务器的ip 如果是用postman,则:请求方式为 get
浏览器效果
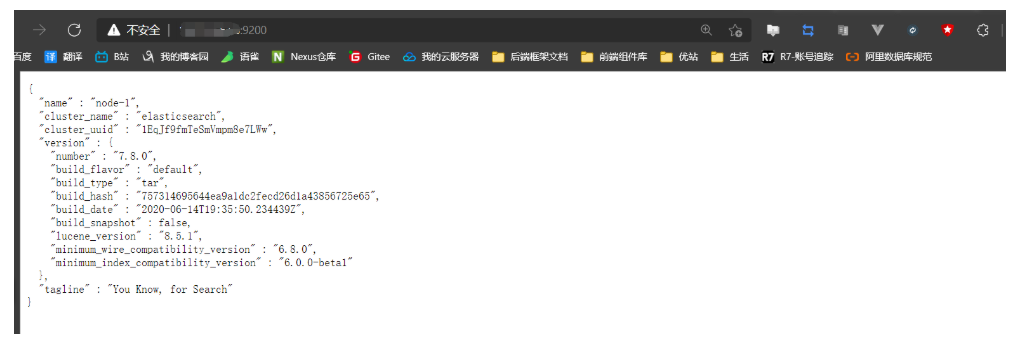
- 注:浏览器访问不了,看看自己服务器开放9200端口没有,别搞这种扯犊子事啊
postman的效果

4.1.2.2、部署集群ES
最简单易懂但复杂的方式:对照windows版的集群就可以了
- 解压ES、重命名
- 复制几份ES文件夹
- 修改对应配置
更简单的方式
- 解压linux版的ES,重命名
- 分发节点
xsync es-colony # es-colony就是重命名之后的es文件夹
- 注:要是没有配置xsync,则:需要单独配置好,面向百度吧,很简单的,就使用yum命令安装rsync、添加hosts信息、编辑xsync脚本、给文件授权,然后就搞定了
4.2、巩固核心概念
4.2.1、索引 index
所谓索引:类似于关系型数据库中的数据库
但是索引这个东西在ES中又有点东西,它的作用和关系型数据库中的索引是一样的,相当于门牌号,一个标识,旨在:提高查询效率,当然,不是说只针对查询,CRUD都可以弄索引,所以这么一说ES中的索引和关系型数据库中的索引是一样的,就不太类似于关系型中的数据库了,此言差矣!在关系型中有了数据库,才有表结构( 行、列、类型...... ),而在ES中就是有了索引,才有doc、field.....,因此:这就类似于关系型中的数据库,只是作用和关系型中的索引一样罢了
因此:ES中索引类似于关系型中的数据库,作用:类似于关系型中的索引,旨在:提高查询效率,当然:在一个集群中可以定义N多个索引,同时:索引名字必须采用全小写字母
当然:也别忘了有一个倒排索引
- 关系型数据库通过增加一个B+树索引到指定的列上,以便提升数据检索速度。索引ElasticSearch 使用了一个叫做
倒排索引的结构来达到相同的目的
- 关系型数据库通过增加一个B+树索引到指定的列上,以便提升数据检索速度。索引ElasticSearch 使用了一个叫做
4.2.2、类型 type
这玩意儿就相当于关系型数据库中的表,注意啊:关系型中表是在数据库下,那么ES中也相应的 类型是在索引之下建立的
表是个什么玩意呢?行和列嘛,这行和列有多少N多行和N多列嘛,所以:ES中的类型也一样,可以定义N种类型。同时:每张表要存储的数据都不一样吧,所以表是用来干嘛的?分类 / 分区嘛,所以ES中的类型的作用也来了:就是为了分类嘛。另外:关系型中可以定义N张表,那么在ES中,也可以定义N种类型
因此:ES中的类型类似于关系型中的表,作用:为了分类 / 分区,同时:可以定义N种类型,但是:类型必须是在索引之下建立的( 是索引的逻辑体现嘛 )
但是:不同版本的ES,类型也发生了变化,上面的解读不是全通用的

4.2.3、文档 document
- 这玩意儿类似管关系型中的行。 一个文档是一个可被索引的基础信息单元,也就是一条数据嘛
4.2.4、字段field
- 这也就类似于关系型中的列。 对文档数据根据不同属性( 列字段 )进行的分类标识
4.2.5、映射 mapping
- 指的就是:结构信息 / 限制条件
- 还是对照关系型来看,在关系型中表有哪些字段、该字段是否为null、默认值是什么........诸如此的限制条件,所以ES中的映射就是:数据的使用规则设置
4.2.6、分片 shards - 重要
这玩意儿就类似于关系型中的分表
在关系型中如果一个表的数据太大了,查询效率很低、响应很慢,所以就会采用大表拆小表,如:用户表,不可能和用户相关的啥子东西都放在一张表吧,这不是找事吗?因此:需要分表
相应的在ES中,也需要像上面这么干,如:存储100亿文档数据的索引,在单节点中没办法存储这么多的文档数据,所以需要进行切割,就是将这整个100亿文档数据切几刀,然后每一刀切分出来的每份数据就是一个分片 ( 索引 ),然后在切开的每份数据单独放在一个节点中,这样切开的所有文档数据合在一起就是一份完整的100亿数据,因此:这个的作用也是为了提高效率
创建一个索引的时候,可以指定想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上
分片有两方面的原因:
- 允许水平分割 / 扩展内容容量,水平扩充,负载均衡嘛
- 允许在分片之上进行分布式的、并行的操作,进而提高性能 / 吞吐量
注意啊: 当 Elasticsearch 在索引中搜索的时候, 它发送查询到每一个属于索引的分片,然后合并每个分片的结果到一个全局的结果集中
4.2.7、副本 Replicas - 重要
这不是游戏中的刷副本的那个副本啊。是指:分片的复制品
失败是常有的事嘛,所以:在ES中也会失败呀,可能因为网络、也可能因此其他鬼原因就导致失败了,此时不就需要一种故障转移机制吗,也就是 创建分片的一份或多份拷贝,这些拷贝就叫做复制分片( 副本 )
副本( 复制分片 )之所以重要,有两个原因:
- 在分片 / 节点失败的情况下,提供了高可用性。因为这个原因,复制分片不与原 / 主要( original / primary )分片置于同一节点上是非常重要的
- 扩展搜索量 / 吞吐量,因为搜索可以在所有的副本上并行运行
多说一嘴啊,分片和副本这两个不就是配套了吗,分片是切割数据,放在不同的节点中( 服务中 );副本是以防服务宕掉了,从而丢失数据,进而把分片拷贝了任意份。这个像什么?不就是Redis中的主备机制吗( 我说的是主备机制,不是主从复制啊 ,这两个有区别的,主从是一台主机、一台从机,主、从机都具有读写操作;而主备是一台主机、一台从机,主机具有读写操作,而从机只有读操作 ,不一样的啊 )
不过,有个细节一定需要注意啊,在Redis中是主备放在一台服务器中,而在ES中,分片和副本不是在同一台服务器中,是分开的,如:分片P1在节点1中,那么副本R1就不能在节点1中,而是其他服务中,不然服务宕掉了,那数据不就全丢了吗
4.2.8、分配 Allocation
前面讲到了分片和副本,对照Redis中的主备来看了,那么对照Redis的主从来看呢?主机宕掉了怎么重新选一个主机?Redis中是加了一个哨兵模式,从而达到的。那么在ES中哪个是主节点、哪个是从节点、分片怎么去分的?就是利用了分配
所谓的分配是指: 将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。注意:这个过程是由 master 节点完成的,和Redis还是有点不一样的啊
既然都说了这么多,那就再来一个ES的系统架构吧
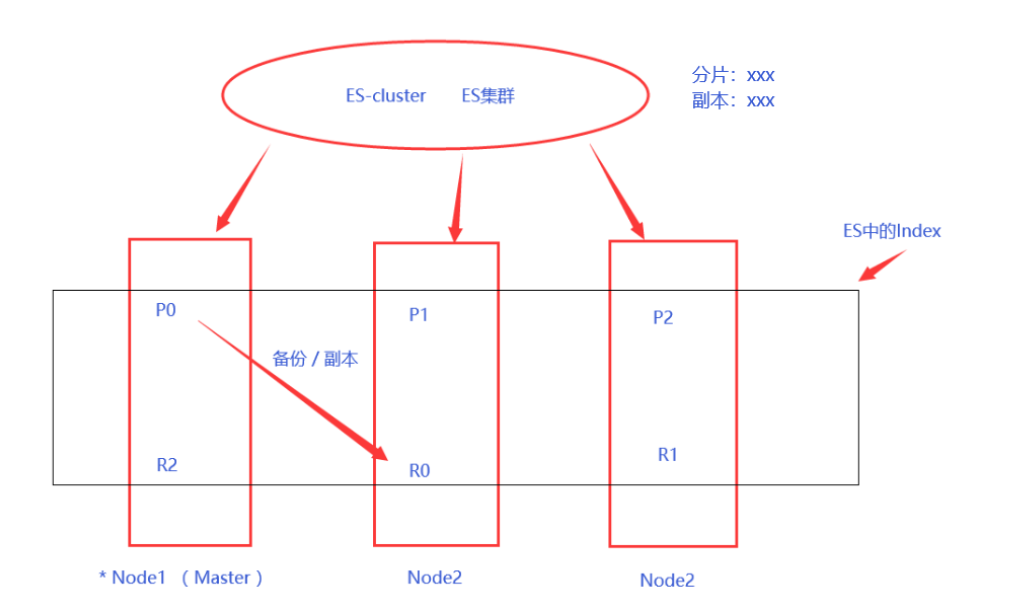
其中,P表示分片、R表示副本
默认情况下,分片和副本都是1,根据需要可以改变
4.3、单节点集群
这里为了方便就使用window版做演示,就不再linux中演示了
- 打开前面玩的window版集群的1节点
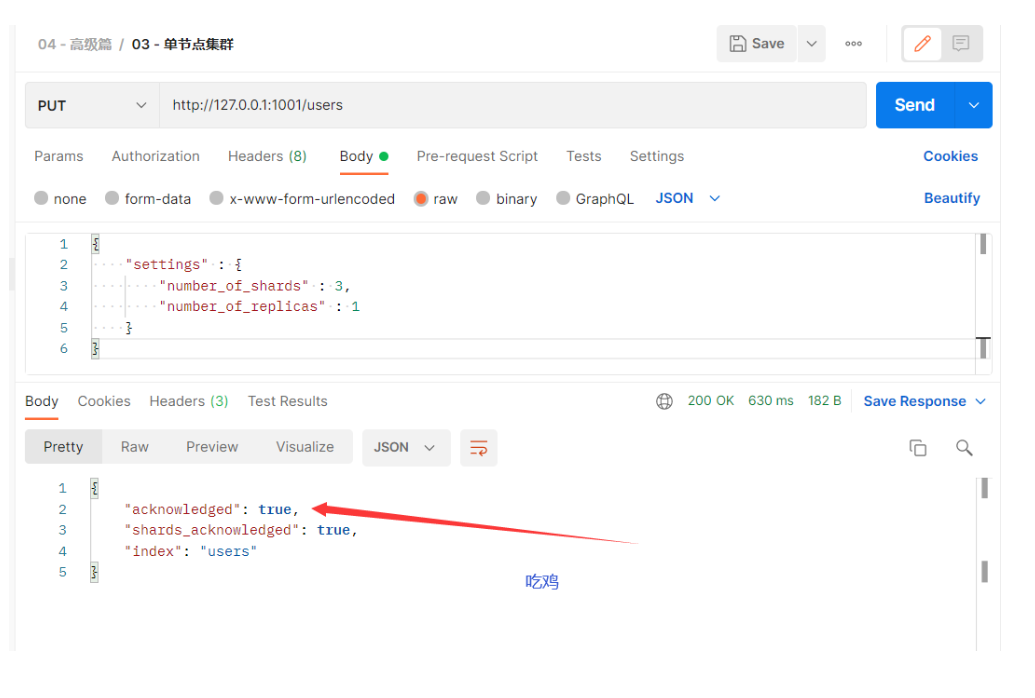
- 创建索引 把这个索引切成3份( 切片 )、每份拷贝1份副本
http://127.0.0.1:1001/users # 请求方式:put
# 请求体内容
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
开始安装head插件,这就是一个可视化界面而已,后续还会用Kibana
自行到官网下载elasticsearch-head-master,这是用Vue写的
这个插件有两种安装方式,chrome浏览器直接把这个压缩包解压之后,然后把解压的文件夹拖到扩展程序中去,这就成为一个插件,集成到Chrome中去了,也就可以直接用了
还有一种是通过Vue的方式,这种需要保证自己的电脑安装了Node.js,我想都是玩过前后端分离的,也就玩过Vue了,所以这些Vue的配套安装也就有了的 —— 安装Node.js也不难,就官网下载、解压、配置环境变量、然后进到解压的elasticsearch-head-master目录,使用npm install拉取模块,最后使用npm run start就完了。当然npm是国外的,很慢,而使用淘宝的cnpm更快,cnpm安装方式更简单,直接
npm install -g cnpm --registry=https://registry.npm.taobao.org拉取镜像即可,然后就可以使用cnpm来代替npm,从而执行命令了由于我用的是Edge浏览器,所以我是采用的Vue方式启动的elasticsearch-head-master,启动效果如下:
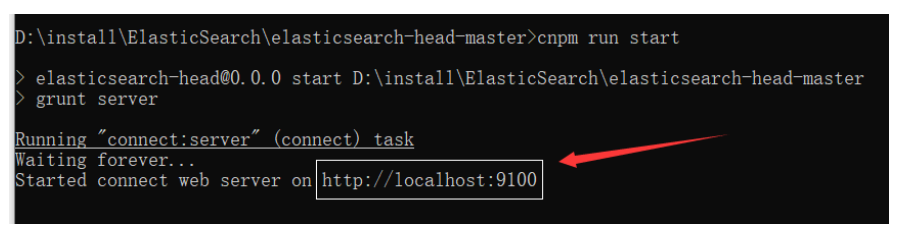
访问上图中的地址即可,但是:这个端口是9100,而我们的ES事9200端口,所以9100访问9200事跨越的,因此:需要对ES设置跨越问题,而这个问题在第一次玩ES集群时就配置了的
head打开之后就是下图中的样子
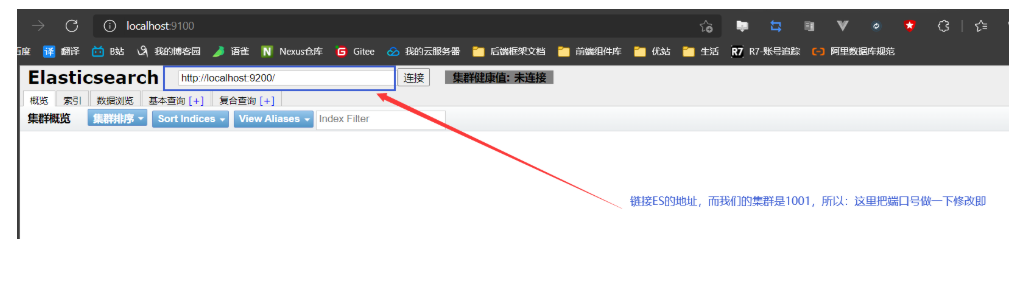
head链接ES之后就是下图的样子
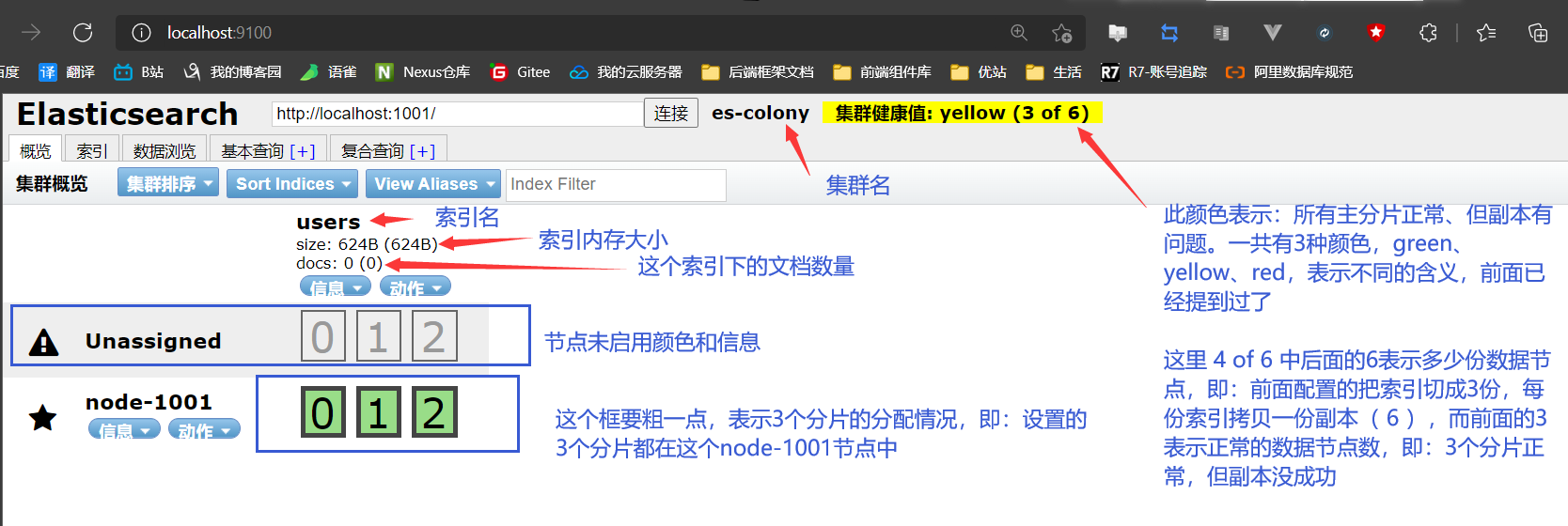
三种颜色再巩固一下:
- green:所有的主分片和副本分片都正常运行
- yellow:所有的主分片都正常运行,但不是所有的副本分片都正常运行
- red:有主分片没能正常运行
但是:上述的单节点集群有问题,就是将分片和副本都放在一个节点( node-1001 )中了,这样会导致前面说的服务宕掉,数据就没了,做的副本就是无用功
当然:在head中测试时,可能会报master_not_discovered_exception,但是再启动一个节点node-1002之后,发现又可以得吃了,而head界面中的颜色从yellow变成green了,这种情况是因为:原有数据导致的,即前面玩windows版ES集群时有另外的数据在里面,只需要把目录下的data文件夹和logs文件夹“下”,把它的东西删了再启动就可以了
但是啊,这里一是玩的windows版,二是为了玩ES才这么干的,这种方式别轻易干啊,学习阶段还是多上网查一下,有很多解决方案的,这里是玩才搞的
回到正题,怎么解决这个集群问题?
4.4、故障转移
这个东西其实已经见到了,就是前面说的报master_not_discovered_exception的情况,此时再启动一个节点即可实现故障转移
启动node-1002节点
一样的,可能由于玩windows版时的一些数据导致node-1002节点启动不了,所以删掉data文件夹和logs文件夹下的东西即可
刷新head可视化页面
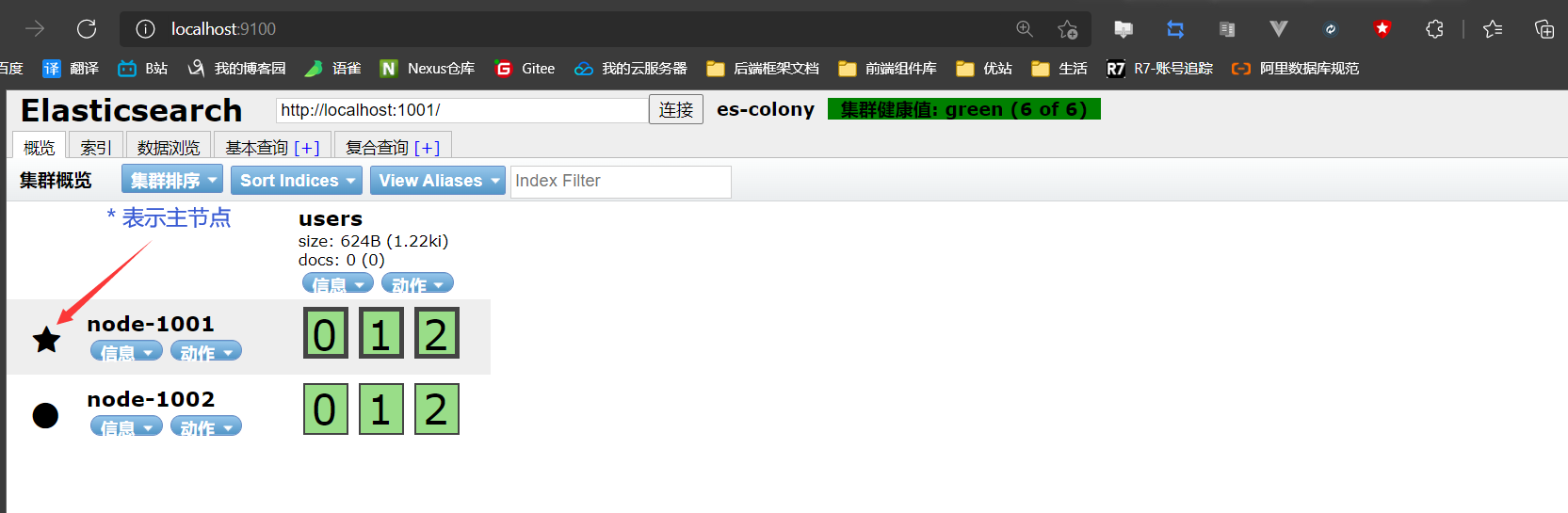
恢复正常
4.5、水平扩容 / 负载均衡
启动node-1003节点
刷新head页面
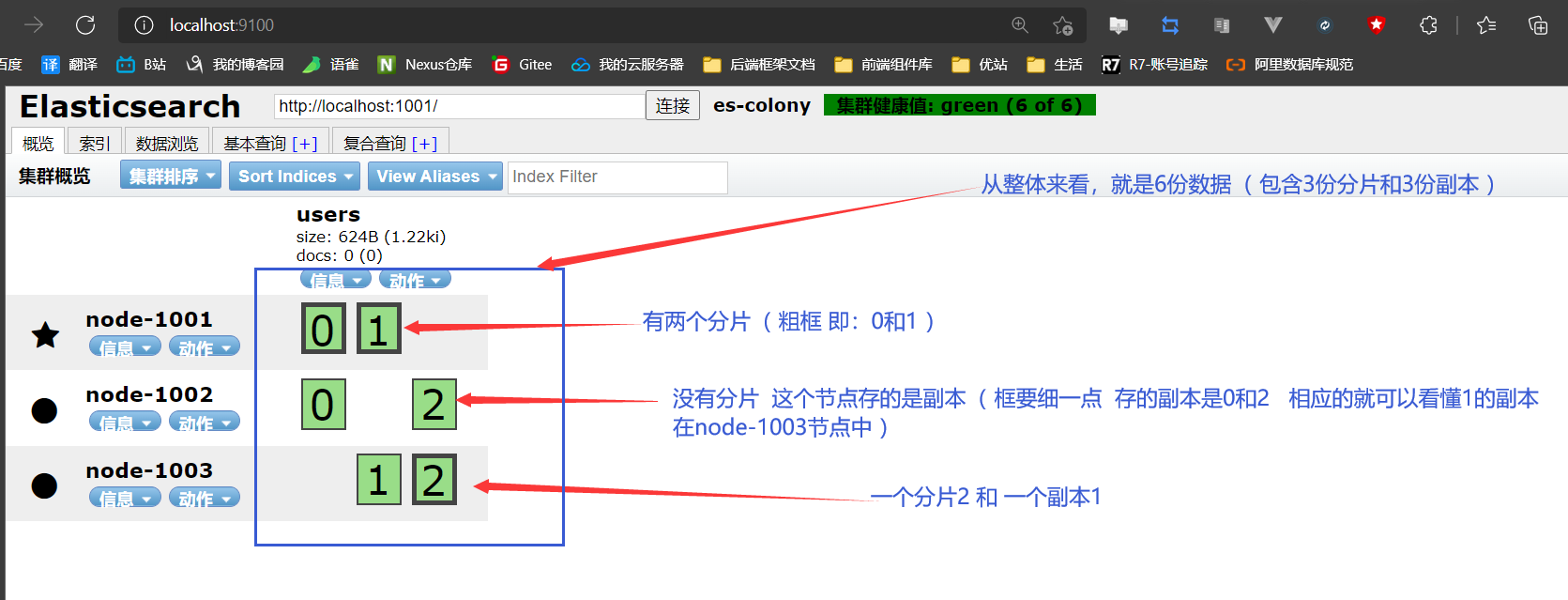
对照前面单节点集群来看,数据就被很好的分开了,这样性能不就提上来了吗?试问是去一个节点上访问数据快还是把数据分开之后,减少压力从而效率快呢?肯定后者嘛
但是:如果相应继续扩容呢?即:超过6份数据( 6个节点,前面讲到过索引切分之后,每一份又是单独的索引、副本也算节点 ),那怎么办?
- 首先知道一个点:主分片的数目在索引创建时就已经确定下来了的,这个我们没法改变,这个数目定义了这个索引能够存储的最大数据量( 实际大小取决于你的数据、硬件和使用场景 )
- 但是,读操作——搜索和返回数据——可以同时被主分片 或 副本分片所处理,所以当你拥有越多的副本分片时,也将拥有越高的吞吐量
- 因此:增加副本分片的数量即可
http://127.0.0.1:1001/users/_settings # 请求方式:put
# 请求体内容
{
"number_of_replicas": 2
}
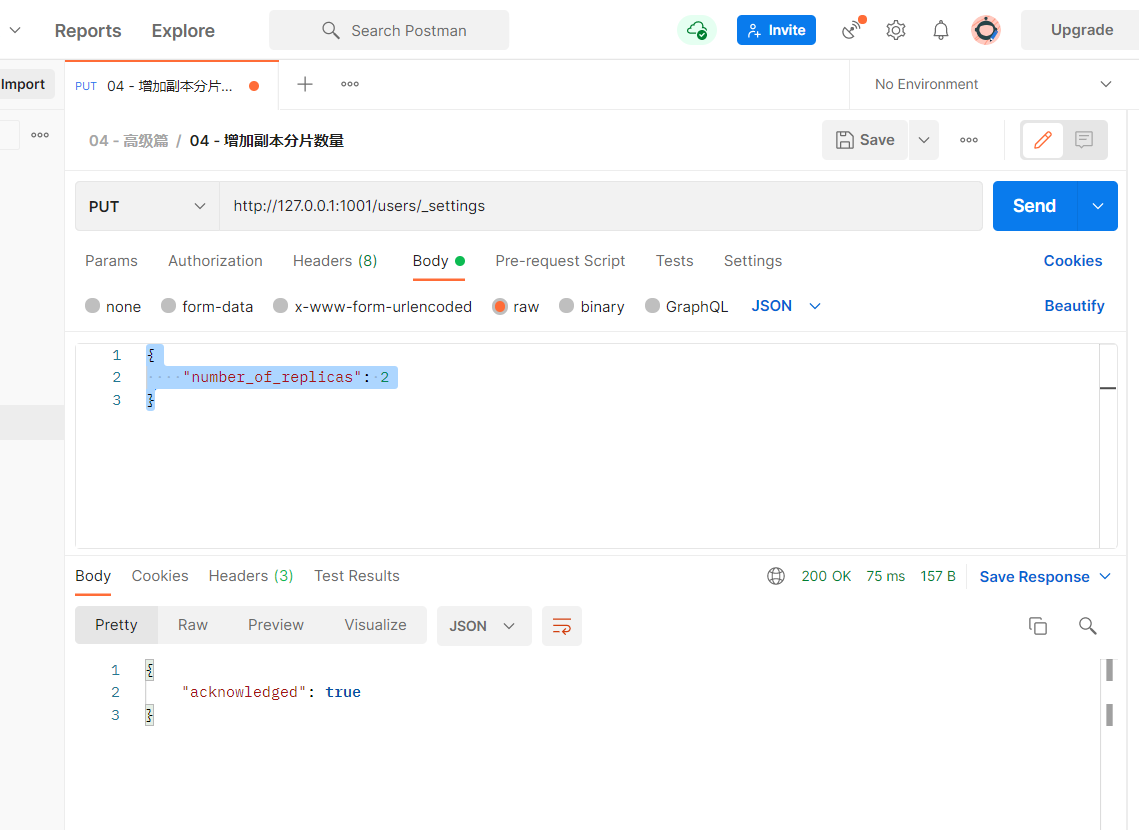
- 刷新head页面
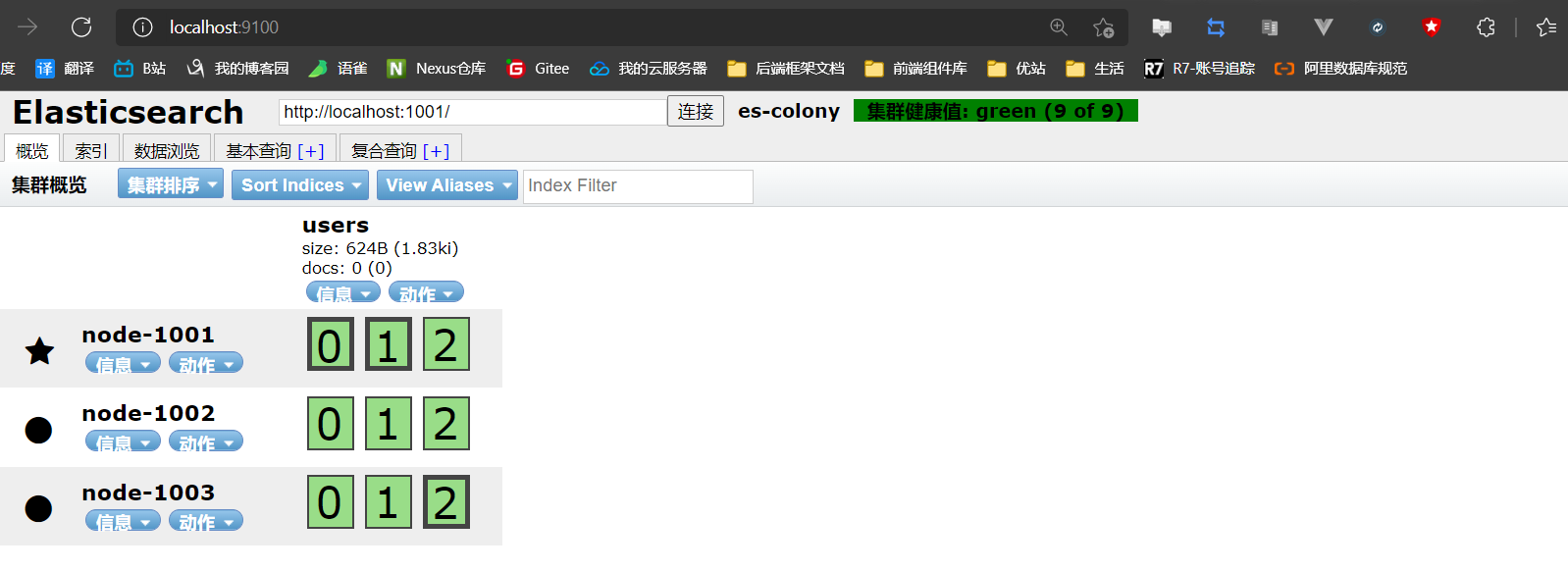
4.6、应对故障
应对的是什么故障?前面一直在说:服务宕掉了嘛
关掉node-1001节点( 主节点 )
刷新head页面
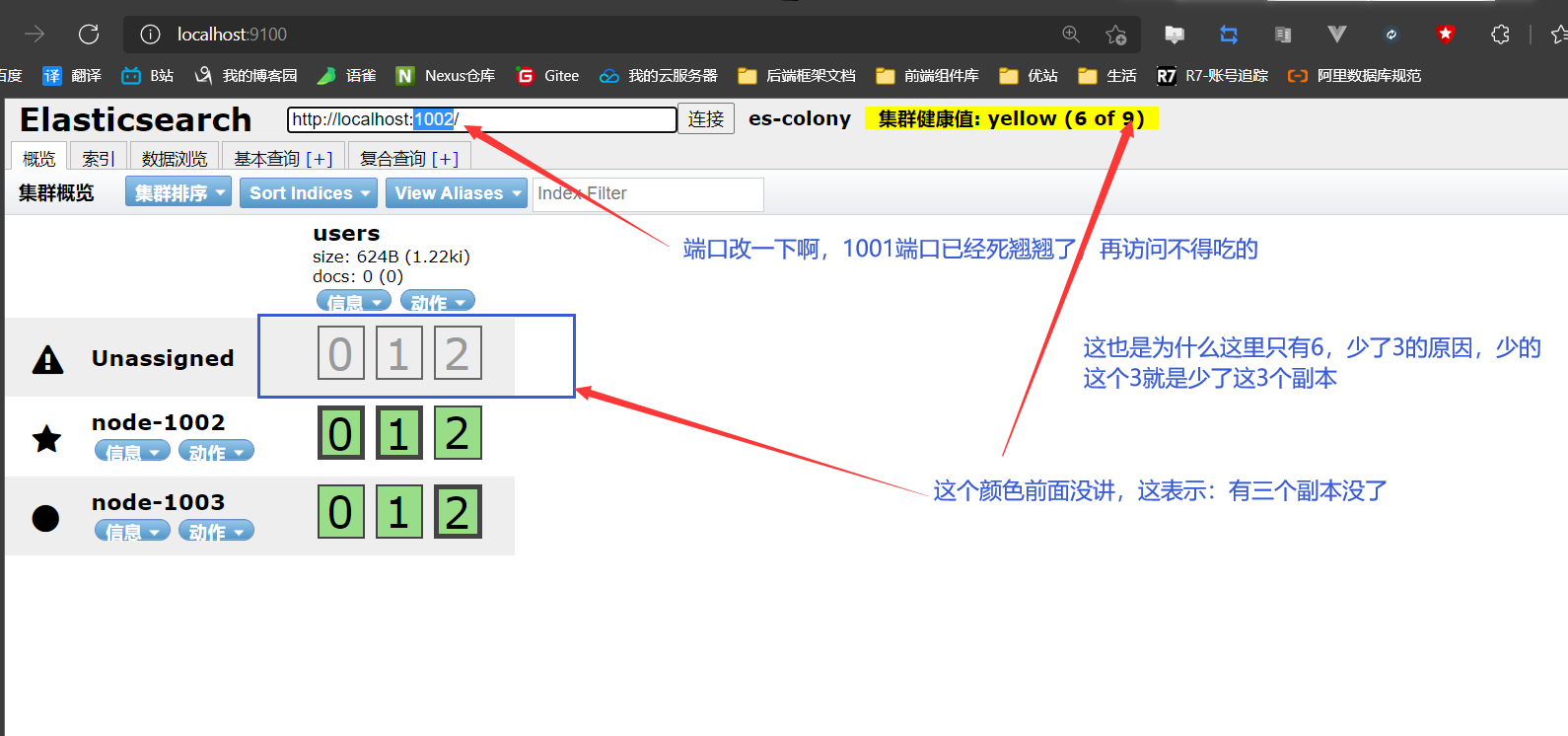
但是注意啊:yellow虽然不正常,但是不影响操作啊,就像你看了这个yellow之后,影响你正常发挥吗?只是可能有点虚脱而已,所以对于ES来说也是可以正常查询数据的,只是:效率降低了而已嘛( 主节点和3个分片都在的嘛 )
解决这种问题
- 开启新节点( 把node-1001节点启动 ———— 此时它就不是主节点了 ,当初新节点了嘛

- 这就会报错: unless existing master is discovered 找不到主节点( 对于启动的集群来说,它现在是新节点涩 ),因此:需要做一下配置修改( node-1001的config/ElasticSearch.yml )
- 开启新节点( 把node-1001节点启动 ———— 此时它就不是主节点了 ,当初新节点了嘛
discovery.seed_hosts: ["127.0.0.1:9302","127.0.0.1:9303"]
保存开启node-1001节点即可

刷新head页面
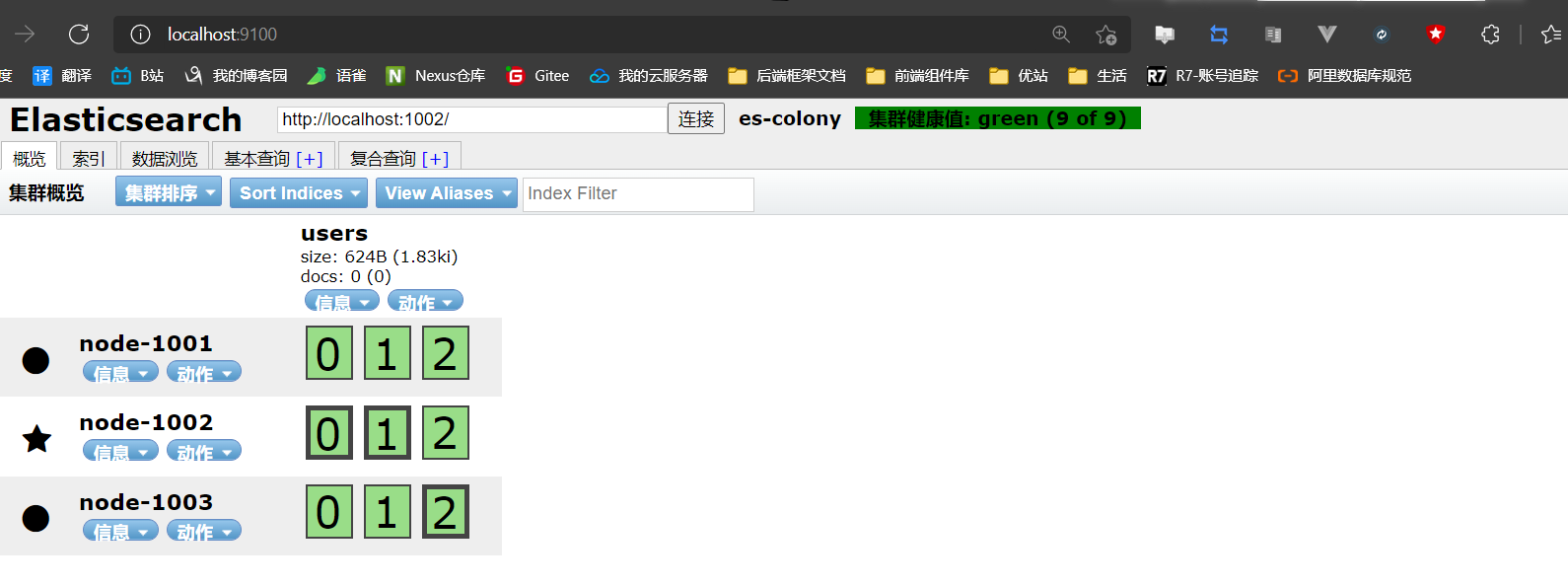
故障恢复了,所以:这也告知一个问题,配置集群时,最好在每个节点的配置文件中都加上上述的配置,从而节点宕掉之后,重启节点即可( 不然每次改不得烦死 ),注意:ES版本不一样,这个配置方法不一样的,6.x的版本是用cluster.initial_master_nodes: 来进行配置的
4.7、路由计算和分片控制理论
4.7.1、路由计算
- 路由、路由,这个东西太熟悉了,在Vue中就见过路由router了( 用来转发和重定向的嘛 )
- 那在ES中的路由计算又是怎么回事?这个主要针对的是ES集群中的存数据,试想:你知道你存的数据是在哪个节点 / 哪个主分片中吗( 副本是拷贝的主分片,所以主分片才是核心 )?
- 当然知道啊,就是那几个节点中的任意一个嘛。娘希匹~这样的骚回答好吗?其实这是由一个公式来决定的
shard = hash( routing ) % number_of_primary_shards
其中
- routing是一个任意值,默认是文档的_id,也可以自定义
- number_of_primary_shards 表示主分片的数量( 如前面切分为了3份 )
- hash()是一个hash函数嘛
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量并且永远不会改变这个数量:因为如果数量变化了,那么之前所有路由的值都会无效,文档也再也找不到了
4.7.2、分片控制
既然有了存数据的问题,那当然就有取数据的问题了。请问:在ES集群中,取数据时,ES怎么知道去哪个节点中取数据( 假如在3节点中,你去1节点中,可以取到吗?),因此:来了分片控制
其实ES不知道数据在哪个节点中,但是:你自己却可以取到数据,为什么?
- 负载均衡涩,轮询嘛。所以这里有个小知识点,就是:协调节点
coordinating node,我们可以发送请求到集群中的任一节点,每个节点都有能力处理任意请求,每个节点都知道集群中任一文档位置,这就是分片控制,而我们发送请求的哪个节点就是:协调节点,它会去帮我们找到我们要的数据在哪里
- 负载均衡涩,轮询嘛。所以这里有个小知识点,就是:协调节点
因此:当发送请求的时候, 为了扩展负载,更好的做法是轮询集群中所有的节点( 先知道这样做即可 )
4.8、数据写流程
新建、索引和删除请求都是写操作, 必须在主分片上面完成之后才能被复制到相关的副本分片
整个流程也很简单
- 客户端请求任意节点( 协调节点 )
- 通过路由计算,协调节点把请求转向指定的节点
- 转向的节点的主分片保存数据
- 主节点再将数据转发给副本保存
- 副本给主节点反馈保存结果
- 主节点给客户端反馈保存结果
- 客户端收到反馈结果

但是:从图中就可以看出来,这套流程完了,才可以做其他事( 如:才可以去查询数据 ),那我为什么不可以异步呢?就是我只要保证到了哪一个步骤之后,就可以进行数据查询,所以:这里有两个小东西需要了解
在进行写数据时,我们做个小小的配置
4.8.1、一致性 consistency
这玩意就是为了和读数据搭配起来嘛,写入和读取保证数据的一致性呗
这玩意可以设定的值如下:
- one :只要主分片状态 ok 就允许执行读操作,这种写入速度快,但不能保证读到最新的更改
- all:这是强一致性,必须要主分片和所有副本分片的状态没问题才允许执行写操作
- quorum:这是ES的默认值啊, 即大多数的分片副本状态没问题就允许执行写操作。这是折中的方法,write的时候,W>N/2,即参与写入操作的节点数W,必须超过副本节点数N的一半,在这个默认情况下,ES是怎么判定你的分片数量的,就一个公式:int( primary + number_of_replicas) / 2 ) + 1
- 注意:primary指的是创建的索引数量;number_of_replicas是指的在索引设置中设定的副本分片数,如果你的索引设置中指定了当前索引拥有3个副本分片,那规定数量的计算结果为:int( 1 primary + 3 replicas) / 2 ) + 1 = 3,如果此时你只启动两个节点,那么处于活跃状态的分片副本数量就达不到规定数量,也因此你将无法索引和删除任何文档
- realtime request:就是从translog里头读,可以保证是最新的。但是注意啊:get是最新的,但是检索等其他方法不是( 如果需要搜索出来也是最新的,需要refresh,这个会刷新该shard但不是整个index,因此如果read请求分发到repliac shard,那么可能读到的不是最新的数据,这个时候就需要指定preference=_primar y)
4.8.2、超时 timeout
如果没有足够的副本分片会发生什么?Elasticsearch 会等待,希望更多的分片出现。默认情况下,它最多等待 1 分钟。 如果你需要,你可以使用timeout参数使它更早终止,单位是毫秒,如:100就是100毫秒
新索引默认有1个副本分片,这意味着为满足规定数量应该需要两个活动的分片副本。 但是,这些默认的设置会阻止我们在单一节点上做任何事情。为了避免这个问题,要求只有当number_of_replicas 大于1的时候,规定数量才会执行
上面的理论不理解、或者感觉枯燥也没事儿,后面慢慢的就理解了,这里只是打个预防针、了解理论罢了
4.9、数据读流程
有写流程,那肯定也要说一下读流程嘛,其实和写流程很像,只是变了那么一丢丢而已
流程如下:
- 客户端发送请求到任意节点( 协调节点 )
- 这里不同,此时协调节点会做两件事:1、通过路由计算得到分片位置,2、还会把当前查询的数据所在的另外节点也找到( 如:副本 )
- 为了负载均衡( 可能某个节点中的访问量很大嘛,减少一下压力咯 ),所以就会对查出来的所有节点做轮询操作,从而找到想要的数据( 因此:你想要的数据在主节点中有、副本中也有,但是:给你的数据可能是主节点中的,也可能是副本中的 ———— 看轮询到的是哪个节点中的 )
- 节点反馈结果
- 客户端收到反馈结果
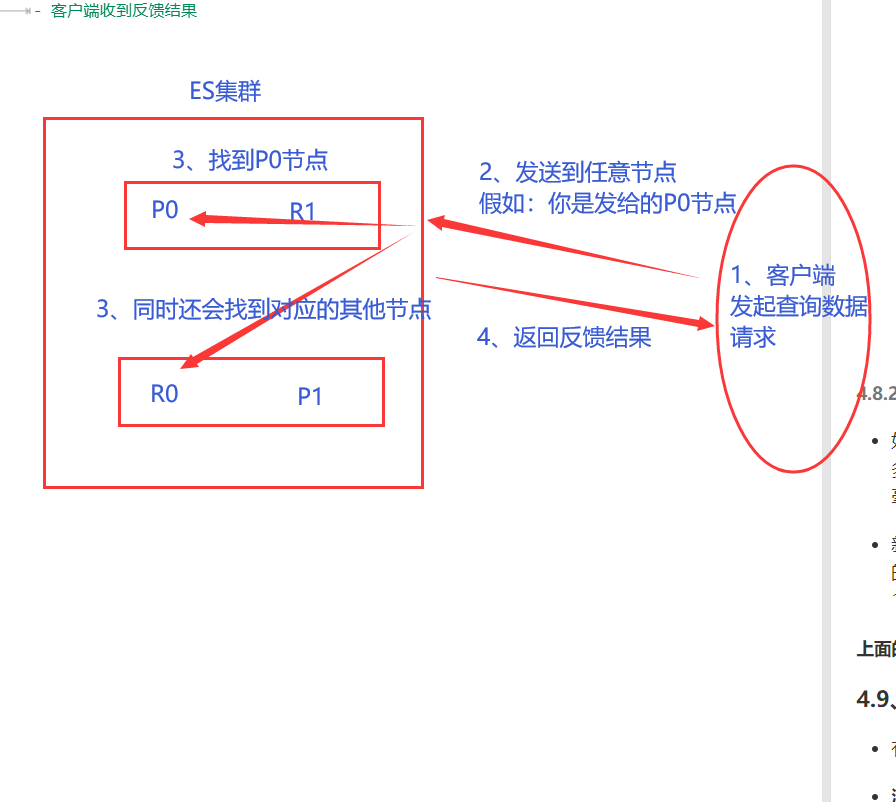
当然:这里有个注意点啊( 需要结合前面说的一致性理论 )
- 在文档( 数据 )被检索时,已经被索引的文档可能已经存在于主分片上但是还没有复制到副本分片。 在这种情况下,副本分片可能会报文档不存在,但是主分片可能成功返回文档。 一旦索引请求成功返回给用户,文档在主分片和副本分片都是可用的
4.10、更新操作流程和批量更新操作流程
4.10.1、更新操作流程

1、客户端向node 1发送更新请求。
2、它将请求转发到主分片所在的node 3 。
3、node 3从主分片检索文档,修改_source字段中的JSON,并且尝试重新索引主分片的文档。如果文档已经被另一个进程修改,它会重试步骤3 ,超过retry_on_conflict次后放弃。
4、如果 node 3成功地更新文档,它将新版本的文档并行转发到node 1和 node 2上的副本分片,重新建立索引。一旦所有副本分片都返回成功,node 3向协调节点也返回成功,协调节点向客户端返回成功
当然:上面有个漏洞,就是万一在另一个进程修改之后,当前修改进程又去修改了,那要是把原有的数据修改了呢?这不就成关系型数据库中的“不可重复读”了吗?
- 不会的。因为当主分片把更改转发到副本分片时, 它不会转发更新请求。 相反,它转发完整文档的新版本。注意点:这些更改将会“异步转发”到副本分片,并且不能保证它们以相同的顺序到达。 如果 ES 仅转发更改请求,则可能以错误的顺序应用更改,导致得到的是损坏的文档
4.10.2、批量更新操作流程
这个其实更容易理解,单文档更新懂了,那多文档更新就懂了嘛,多文档就请求拆分呗
所谓的多文档更新就是:将整个多文档请求分解成每个分片的文档请求,并且将这些请求并行转发到每个参与节点。协调节点一旦收到来自每个节点的应答,就将每个节点的响应收集整理成单个响应,返回给客户端
原理图的话:我就在网上偷一张了
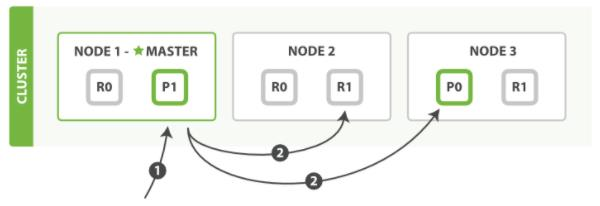
其实mget 和 bulk API的模式就类似于单文档模式。区别在于协调节点知道每个文档存在于哪个分片中
4.11、再次回顾分片和倒排索引
4.11.1、分片
所谓的分片就是:将索引切分成任意份嘛,然后得到的每一份数据都是一个单独的索引
分片完成后,我们存数据时,存到哪个节点上,就是通过
shard = hash( routing ) % number_of_primary_shards得到的而我们查询数据时,ES怎么知道我们要找的数据在哪个节点上,就是通过
协调节点做到的,它会去找到和数据相关的所有节点,从而轮询( 所以最后的结果可能是从主分片上得到的,也可能是从副本上得到的,就看最后轮询到的是哪个节点罢了
4.11.2、倒排索引
- 这个其实在基础篇中一上来说明索引时就提到了,基础篇链接如下:
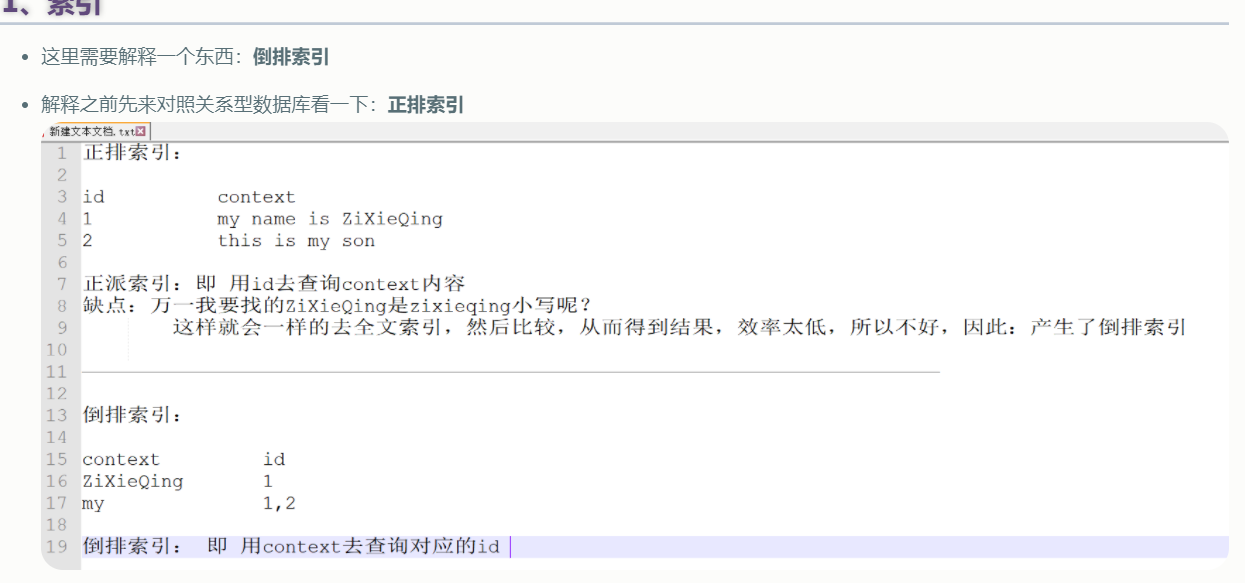
图中这里,是将内容( 关键字 )拆分了,然后来对应ID,所以:这里还有一种东西:分词,后面会接触Kibana,再做详细介绍
但是,那只是简单提了一下而已,其实还有三个东西没说明
4.11.2.1、词条
- 它是指:索引中的最小存储或查询单元。这个其实很好理解,白话文来讲就是:字或者词组,英文就是一个单词,中文就是字或词组嘛,比如:你要查询的是某一个字或词组,这就是词条呗
4.11.2.2、词典
- 这个就更简单了,就是词条的集合嘛。字或者词组组成的内容呗
4.11.2.3、倒排表
- 就是指:关键字 / 关键词在索引中的位置 / 概率,有点类似于数组,你查询数组中某个元素的位置,但是区别很大啊,我只是为了好理解,所以才这么举例子的
4.12、后面的安排
后续的内容,打算抽取出来,重新弄成一片小博客,知识点太多,看起来太费劲了
让我弄知识点的哪些半吊子,如果是从基础篇:https://www.cnblogs.com/xiegongzi/p/15684307.html,到java操作篇:https://www.cnblogs.com/xiegongzi/p/15690534.html,老老实实看到现在的话,那么掌握的ES知识足够了
后续有时间就弄一个ES小Demo出来,没时间就略过了
后续的内容就是一些理论、Kibana、框架集成,重点是Kibana、框架集成
3 - 基于ELK的ElasticSearch 7.8.x技术整理 - 高级篇( 偏理论 )的更多相关文章
- 4 - 基于ELK的ElasticSearch 7.8.x技术整理 - 高级篇( 续 ) - 更新完毕
0.前言 这里面一些理论和前面的知识点挂钩的,所以:建议看一下另外3篇知识内容 基础篇:https://www.cnblogs.com/xiegongzi/p/15684307.html java操作 ...
- 1 - 基于ELK的ElasticSearch 7.8.x 技术整理 - 基础语法篇 - 更新完毕
准备工作 0.什么是ElasticSearch?它和Lucene以及solr的关系是什么? 这些是自己的知识获取能力,自行百度百科 1.下载ElasticSearch的window版,linux版后续 ...
- 2 - 基于ELK的ElasticSearch 7.8.x技术整理 - java操作篇 - 更新完毕
3.java操作ES篇 3.1.摸索java链接ES的流程 自行创建一个maven项目 3.1.1.依赖管理 点击查看代码 <properties> <ES-version>7 ...
- 基于ELK5.1(ElasticSearch, Logstash, Kibana)的一次整合测试
前言开源实时日志分析ELK平台(ElasticSearch, Logstash, Kibana组成),能很方便的帮我们收集日志,进行集中化的管理,并且能很方便的进行日志的统计和检索,下面基于ELK的最 ...
- 基于ELK5.1(ElasticSearch, Logstash, Kibana)的一次整合
前言开源实时日志分析ELK平台(ElasticSearch, Logstash, Kibana组成),能很方便的帮我们收集日志,进行集中化的管理,并且能很方便的进行日志的统计和检索,下面基于ELK的最 ...
- 基于ELK的简单数据分析
原文链接: http://www.open-open.com/lib/view/open1455673846058.html 环境 CentOS 6.5 64位 JDK 1.8.0_20 Elasti ...
- 基于ELK进行邮箱访问日志的分析
公司希望能够搭建自己的日志分析系统.现在基于ELK的技术分析日志的公司越来越多,在此也记录一下我利用ELK搭建的日志分析系统. 系统搭建 系统主要是基于elasticsearch+logstash+f ...
- 从0搭建一个基于 ELK 的日志、指标收集与监控系统
为了使得私有化部署的系统能更健壮,同时不增加额外的部署运维工作量,本文提出了一种基于 ELK 的开箱即用的日志和指标收集方案. 在当前的项目中,我们已经使用了 Elasticsearch 作为业务的数 ...
- ELK stack elasticsearch/logstash/kibana 关系和介绍
ELK stack elasticsearch 后续简称ES logstack 简称LS kibana 简称K 日志分析利器 elasticsearch 是索引集群系统 logstash 是日志归集集 ...
随机推荐
- 2019广东工业大学新生杯决赛 I-迷途的怪物
题目:I-I-迷途的怪物_2019年广东工业大学腾讯杯新生程序设计竞赛(同步赛) (nowcoder.com) 将(p-1)^n 按照多项式定理拆开,会发现只有一项没有p,其余项都有p,可直接约掉. ...
- spring boot集成swagger文档
pom <!-- swagger --> <dependency> <groupId>io.springfox</groupId> <artifa ...
- archive后upload to app store时遇到app id不可用的问题
问题如下图 出现此问题的原因有两种: 1.此app id在AppStore中已经存在,也就是说你使用别人注册的app ID , 如果是这样,你只能更换app ID 2.此app ID是自己的,突然之 ...
- Linux基础命令---uptime
uptime uptime指令用来显示系统运行多长时间.有多少用户登录.系统负载情况. 此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS.Fedora.SUSE.openSUSE. ...
- 【编程思想】【设计模式】【创建模式creational】Borg/Monostate
Python版 https://github.com/faif/python-patterns/blob/master/creational/borg.py #!/usr/bin/env python ...
- 微服务下前后端分离的统一认证授权服务,基于Spring Security OAuth2 + Spring Cloud Gateway实现单点登录
1. 整体架构 在这种结构中,网关就是一个资源服务器,它负责统一授权(鉴权).路由转发.保护下游微服务. 后端微服务应用完全不用考虑权限问题,也不需要引入spring security依赖,就正常的 ...
- C#.NET编程小考30题错题纠错
1)以下关于序列化和反序列化的描述错误的是( C). a) 序列化是将对象的状态存储到特定存储介质中的过程 b) 二进制格式化器的Serialize()和Deserialize()方法可以分别用来实现 ...
- Wireshark(四):网络性能排查之TCP重传与重复ACK
原文出处: EMC中文支持论坛 作为网络管理员,很多时间必然会耗费在修复慢速服务器和其他终端.但用户感到网络运行缓慢并不意味着就是网络问题. 解决网络性能问题,首先从TCP错误恢复功能(TCP重传与重 ...
- 筛选Table.SelectRows-日期与时间(Power Query 之 M 语言)
数据源: 包含日期与时间的任意数据 目标: 对日期与时间进行筛选 M公式: = Table.SelectRows( 表,筛选条件) 筛选条件: 等于:each [日期列] = #date(年,月,日) ...
- CF1520D Same Differences 题解
Content 给定 \(n\) 个数 \(a_1,a_2,\dots,a_n\),求有多少个二元组 \((i,j)\) 满足: \(i<j\). \(a_j-a_i=j-i\). 数据范围:\ ...