hbase构建二级索引解决方案
关注公众号:
大数据技术派,回复“资料”,领取1024G资料。
1 为什么需要二级索引
HBase的一级索引就是rowkey,我们仅仅能通过rowkey进行检索。假设我们相对Hbase里面列族的列列进行一些组合查询,就只能全表扫描了。表如果较大的话,代价是不可接受的,所以要提出二级索引的方案。
二级索引的思想:简单理解就是,根据列族的列的值,查出rowkey,再按照rowkey就能很快从hbase查询出数据,我们需要构建出根据列族的列的值,很快查出rowkey的方案。
2 常见的二级索引方案
MapReduce方案;Coprocessor方案;elasticsearch+hbase方案;Solr+hbase方案;
2.1 MapReduce方案
IndexBuilder:利用MR的方式构建Index
长处:并发批量构建Index
缺点:不能实时构建Index
举例:
原表:
row 1 f1:name zhangsan
row 2 f1:name lisi
row 3 f1:name wangwu
索引表:
row zhangsan f1:id 1
row lisi f1:id 2
row wangwu f1:id 3
这种方式的思想是再构建一张hbase表,列族的列这里的name作为索引表的rowkey,根据rowkey查询出数据hbase是很快的,拿到id后,也就拿到了原表的rowkey了,因为源表的rowkey就是id,每次查询一共需要查询两张表。
2.2 Coprocessor方案
有关协处理器的讲解,Hbase官方文档是最好的,这里大体说一下它的作用与使用方法。
- Coprocessor提供了一种机制可以让开发者直接在RegionServer上运行自定义代码来管理数据。
通常我们使用get或者scan来从Hbase中获取数据,使用Filter过滤掉不需要的部分,最后在获得的数据上执行业务逻辑。但是当数据量非常大的时候,这样的方式就会在网络层面上遇到瓶颈。客户端也需要强大的计算能力和足够大的内存来处理这么多的数据,客户端的压力就会大大增加。但是如果使用Coprocessor,就可以将业务代码封装,并在RegionServer上运行,也就是数据在哪里,我们就在哪里跑代码,这样就节省了很大的数据传输的网络开销。 - Coprocessor有两种:Observer和Endpoint
EndPoint主要是做一些计算用的,比如计算一些平均值或者求和等等。而Observer的作用类似于传统关系型数据库的触发器,在一些特定的操作之前或者之后触发。学习过Spring的朋友肯定对AOP不陌生,想象一下AOP是怎么回事,就会很好的理解Observer了。Observer Coprocessor在一个特定的事件发生前或发生后触发。在事件发生前触发的Coprocessor需要重写以pre作为前缀的方法,比如prePut。在事件发生后触发的Coprocessor使用方法以post作为前缀,比如postPut。
Observer Coprocessor的使用场景如下:
2.1. 安全性:在执行Get或Put操作前,通过preGet或prePut方法检查是否允许该操作;
2.2. 引用完整性约束:HBase并不直接支持关系型数据库中的引用完整性约束概念,即通常所说的外键。但是我们可以使用Coprocessor增强这种约束。比如根据业务需要,我们每次写入user表的同时也要向user_daily_attendance表中插入一条相应的记录,此时我们可以实现一个Coprocessor,在prePut方法中添加相应的代码实现这种业务需求。
2.3. 二级索引:可以使用Coprocessor来维持一个二级索引。正是我们需要的
索引设计思想
关键部分来了,既然Hbase并没有提供二级索引,那如何实现呢?先看下面这张图
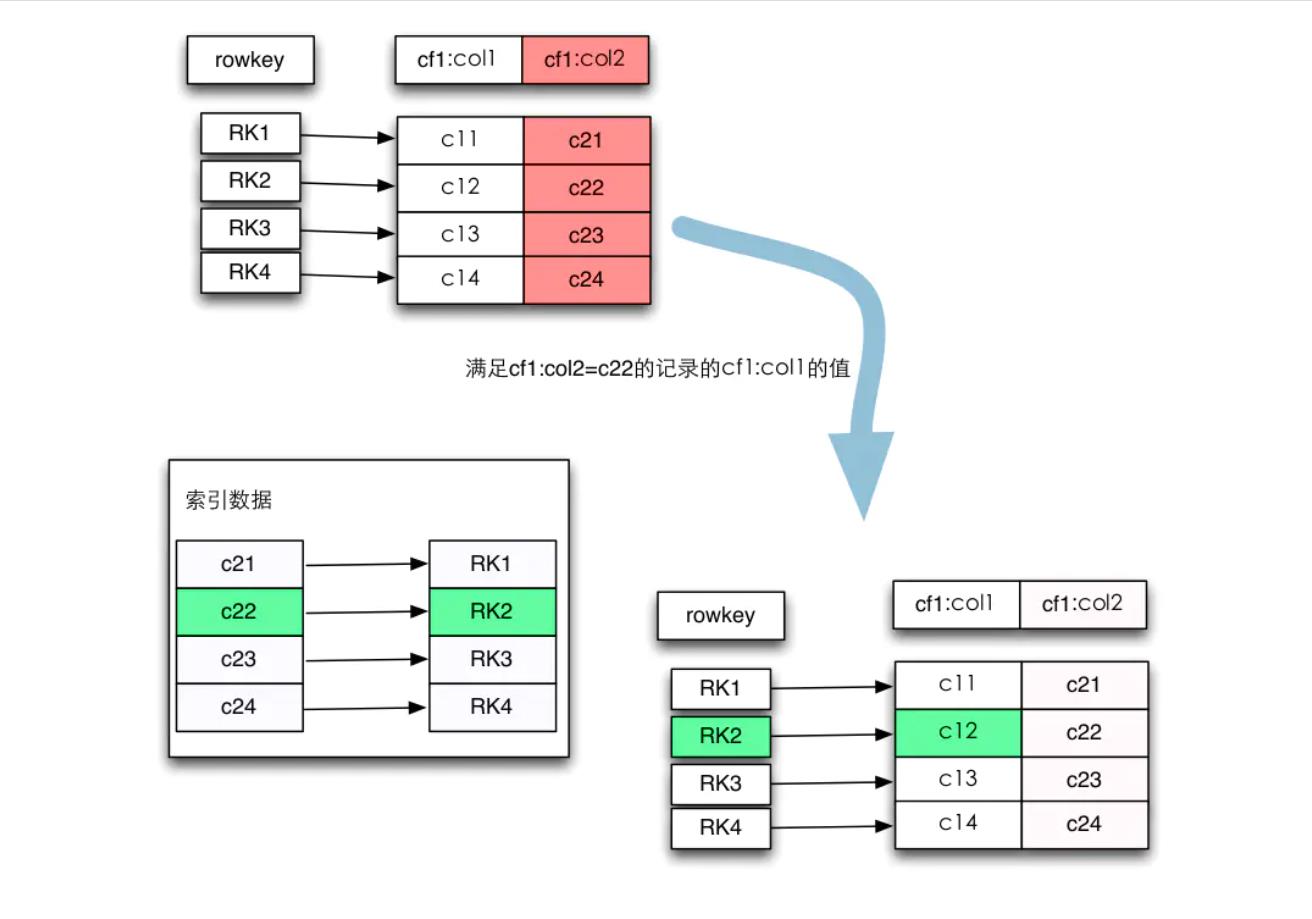
我们的需求是找出满足cf1:col2=c22这条记录的cf1:col1的值,实现方法如图,首先根据cf1:col2=c22查找到该记录的行键,然后再通过行健找到对应的cf1:col1的值。其中第二步是很容易实现的,因为Hbase的行键是有索引的,那关键就是第一步,如何通过cf1:col2的值找到它对应的行键。很容易想到建立cf1:col2的映射关系,即将它们提取出来单独放在一张索引表中,原表的值作为索引表的行键,原表的行键作为索引表的值,这就是Hbase的倒排索引的思想。
2.3 elasticsearch+hbase方案
比如说你现在有一行数据
id name age ….30 个字段
但是你现在搜索,只需要根据 id name age 三个字段来搜索
如果你傻乎乎的往 es 里写入一行数据所有的字段,就会导致说 70% 的数据是不用来搜索的,结果硬是占据了 es 机器上的 filesystem cache 的空间,单挑数据的数据量越大,就会导致 filesystem cahce 能缓存的数据就越少
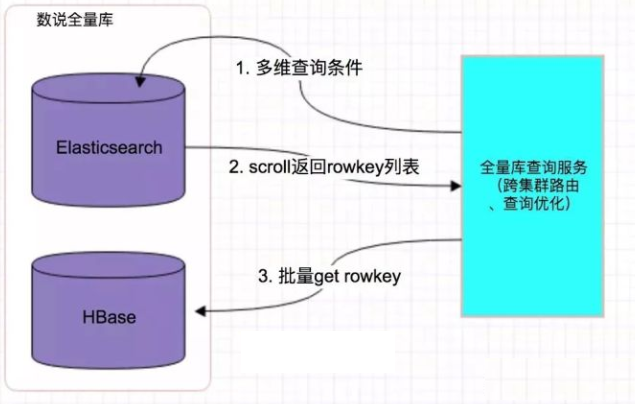
仅仅只是写入 es 中要用来检索的少数几个字段就可以了,比如说,就写入 es id name age 三个字段就可以了,然后你可以把其他的字段数据存在 mysql 里面,我们一般是建议用 es + hbase 的这么一个架构。
hbase 的特点是适用于海量数据的在线存储,就是对 hbase 可以写入海量数据,不要做复杂的搜索,就是做很简单的一些根据 id 或者范围进行查询的这么一个操作就可以了
从 es 中根据 name 和 age 去搜索,拿到的结果可能就 20 个 doc id,然后根据 doc id 到 hbase 里去查询每个 doc id 对应的完整的数据,给查出来,再返回给前端。
你最好是写入 es 的数据小于等于,或者是略微大于 es 的 filesystem cache 的内存容量
然后你从 es 检索可能就花费 20ms,然后再根据 es 返回的 id 去 hbase 里查询,查 20 条数据,可能也就耗费个 30ms,可能你原来那么玩儿,1T 数据都放 es,会每次查询都是 5 ~ 10 秒,现在可能性能就会很高,每次查询就是 50ms。
四个字总结的话,我觉得就是“各司其职”,HBase 就用来存储,ES 就用来做索引,况且目前的实际情况跟文章中说的也很像,要查询的字段就几个,而其他的字段又很大又没用,没必要都丢到 ES 中,浪费查询效率
2.4 Solr+hbase方案
Solr是一个独立的企业级搜索应用server,它对并提供相似干Web-service的API接口。用户能够通过http请求,向搜索引擎server提交一定格式的XML文件,生成索引。也能够通过Http Get操作提出查找请求,并得到XML格式的返回结果。
Solr是一个高性能。採用Java5开发。基干Lucene的全文搜索server。同一时候对其进行了扩展。提供了比Lucene更为丰富的查询语言,同一时候实现了可配置、可扩展并对查询性能进行了优化,而且提供了一个完好的功能节理界面。是一款非常优秀的全文搜索引擎。
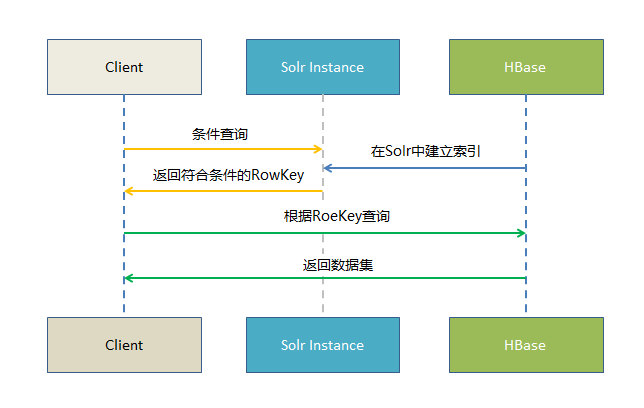
HBase无可置疑拥有其优势,但其本身仅仅对rowkey支持毫秒级的高速检索,对于多字段的组合查询却无能为力。基于Solr的HBase多条件查询原理非常easy。将HBase表中涉及条件过滤的字段和rowkey在Solr中建立索引,通过Solr的多条件查询高速获得符合过滤条件的rowkey值,拿到这些rowkey之后在HBASE中通过指定rowkey进行查询。
网上其它还有根据Phoenix构建的,redis、mysql等都是可以尝试的。
交流群
加我微信:ddxygq,回复“加群”,我拉你进群。
猜你喜欢
数仓建模—指标体系
数仓建模—宽表的设计
Spark SQL知识点与实战
Hive计算最大连续登陆天数
Flink计算pv和uv的通用方法
hbase构建二级索引解决方案的更多相关文章
- HBase建立二级索引的一些解决方式
HBase的一级索引就是rowkey,我们仅仅能通过rowkey进行检索. 假设我们相对hbase里面列族的列列进行一些组合查询.就须要採用HBase的二级索引方案来进行多条件的查询. 常见的二级索引 ...
- HBase的二级索引,以及phoenix的安装(需再做一次)
一:HBase的二级索引 1.讲解 uid+ts 11111_20161126111111:查询某一uid的某一个时间段内的数据 查询某一时间段内所有用户的数据:按照时间 索引表 rowkey:ts+ ...
- 085 HBase的二级索引,以及phoenix的安装(需再做一次)
一:问题由来 1.举例 有A列与B列,分别是年龄与姓名. 如果想通过年龄查询姓名. 正常的检索是通过rowkey进行检索. 根据年龄查询rowkey,然后根据rowkey进行查找姓名. 这样的效率不高 ...
- HBase的二级索引
使用HBase存储中国好声音数据的案例,业务描述如下: 为了能高效的查询到我们需要的数据,我们在RowKey的设计上下了不少功夫,因为过滤RowKey或者根据RowKey查询数据的效率是最高的,我们的 ...
- 基于Solr实现HBase的二级索引
文章来源:http://www.open-open.com/lib/view/open1421501717312.html 实现目的: 由于hbase基于行健有序存储,在查询时使用行健十分高效,然后想 ...
- hbase coprocessor 二级索引
Coprocessor方式二级索引 1. Coprocessor提供了一种机制可以让开发者直接在RegionServer上运行自定义代码来管理数据.通常我们使用get或者scan来从Hbase中获取数 ...
- [How to] MapReduce on HBase ----- 简单二级索引的实现
1.简介 MapReduce计算框架是二代hadoop的YARN一部分,能够提供大数据量的平行批处理.MR只提供了基本的计算方法,之所以能够使用在不用的数据格式上包括HBase表上是因为特定格式上的数 ...
- 利用Phoenix为HBase创建二级索引
为什么需要Secondary Index 对于Hbase而言,如果想精确地定位到某行记录,唯一的办法是通过rowkey来查询.如果不通过rowkey来查找数据,就必须逐行地比较每一列的值,即全表扫瞄. ...
- HBase 二级索引与Join
二级索引与索引Join是Online业务系统要求存储引擎提供的基本特性.RDBMS支持得比较好,NOSQL阵营也在摸索着符合自身特点的最佳解决方案. 这篇文章会以HBase做为对象来探讨如何基于Hba ...
随机推荐
- 日常Java 2021/10/4
读取控制台输入 将System.in包装在BufferedReader对象中来创建一个字符流 BufferedReader b = new BufferedReader(new InputStream ...
- Express中间件原理详解
前言 Express和Koa是目前最主流的基于node的web开发框架,他们的开发者是同一班人马.貌似现在Koa更加流行,但是仍然有大量的项目在使用Express,所以我想通过这篇文章说说Expres ...
- 用户名、密码、整数等常用的js正则表达式
1 用户名正则 //用户名正则,4到16位(字母,数字,下划线,减号) var uPattern = /^[a-zA-Z0-9_-]{4,16}$/; //输出 true console.log(uP ...
- SpringBoot让测试类飞起来的方法
单元测试是项目开发中必不可少的一环,在 SpringBoot 的项目中,我们用 @SpringBootTest 注解来标注一个测试类,在测试类中注入这个接口的实现类之后对每个方法进行单独测试. 比如下 ...
- spring注解-组件注册
一.@Configuration+@Bean @Configuration:配置类==配置文件 @Bean:给容器中注册一个Bean:类型为返回值的类型,默认是用方法名作为id @Bean(" ...
- 【编程思想】【设计模式】【创建模式creational】原形模式Prototype
Python版 https://github.com/faif/python-patterns/blob/master/creational/prototype.py #!/usr/bin/env p ...
- Appium获取toast消息(二)
刚接触appium进行移动端设备的UI自动化,在遇到toast消息的时候很是苦恼了一阵,最后通过强大的搜索引擎找到了个相对解决方法,废话不多说,直接贴代码↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ ...
- 一个超简单的Microsoft Edge Extension
这个比微软官网上的例子简单很多,适合入门.总共4个文件: https://files.cnblogs.com/files/blogs/714801/cet6wordpicker.zip 36KB 1. ...
- 模板方法模式(Template Method Pattern)——复杂流程步骤的设计
模式概述 在现实生活中,很多事情都包含几个实现步骤,例如请客吃饭,无论吃什么,一般都包含点单.吃东西.买单等几个步骤,通常情况下这几个步骤的次序是:点单 --> 吃东西 --> 买单. 在 ...
- 【C++】使用VS2022开发可以在线远程编译部署的C++程序
前言: 今天没有前言. 一.先来一点C++的资源分享,意思一下. 1.c++类库源码以及其他有关资源.站点是英文的,英文不好的话可以谷歌浏览器在线翻译.http://www.cplusplus.com ...