Hive语法及其进阶(二)
1、使用JDBC连接Hive
1 import java.sql.Connection;
2 import java.sql.DriverManager;
3 import java.sql.PreparedStatement;
4 import java.sql.ResultSet;
5
6 public class HiveDemo {
7 public static void main(String[] args) throws Exception {
8 Class.forName("org.apache.hive.jdbc.HiveDriver");
9 //"jdbc:hive2://master:10000/test3"
10 Connection connection = DriverManager.getConnection("jdbc:hive2://master:10000/myhive");
11 String sql="select * from students";
12 PreparedStatement ps = connection.prepareStatement(sql);
13 ResultSet rs = ps.executeQuery();
14 while (rs.next()){
15 int id = rs.getInt(1);
16 String name = rs.getString(2);
17 int age = rs.getInt(3);
18 String gender = rs.getString(4);
19 String clazz = rs.getString(5);
20 System.out.println(id + "," + name + "," + age + "," + gender + "," + clazz);
21 }
22 rs.close();
23 ps.close();
24 connection.close();
25 }
26 }
2、Hive常用函数
1.关系运算
// 等值比较 = == <=>
// 不等值比较 != <>
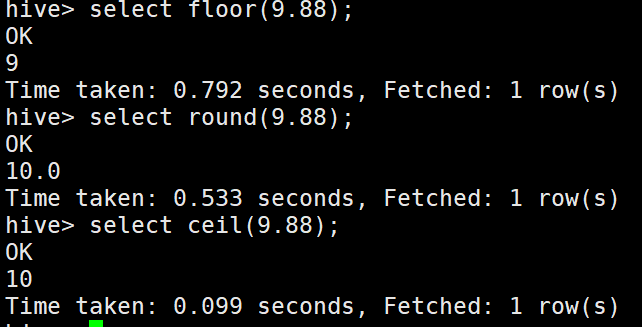
// 区间比较: select * from default.students where id between 1500100001 and 1500100010;
// 空值/非空值判断:is null、is not null、nvl()、isnull()
|
操作符 |
支持的数据类型 |
描述 |
|
A=B |
基本数据类型 |
如果A等于B则返回TRUE,反之返回FALSE |
|
A<=>B |
基本数据类型 |
如果A和B都为NULL,则返回TRUE,如果一边为NULL,返回False |
|
A<>B, A!=B |
基本数据类型 |
A或者B为NULL则返回NULL;如果A不等于B,则返回TRUE,反之返回FALSE |
|
A<B |
基本数据类型 |
A或者B为NULL,则返回NULL;如果A小于B,则返回TRUE,反之返回FALSE |
|
A<=B |
基本数据类型 |
A或者B为NULL,则返回NULL;如果A小于等于B,则返回TRUE,反之返回FALSE |
|
A>B |
基本数据类型 |
A或者B为NULL,则返回NULL;如果A大于B,则返回TRUE,反之返回FALSE |
|
A>=B |
基本数据类型 |
A或者B为NULL,则返回NULL;如果A大于等于B,则返回TRUE,反之返回FALSE |
|
A [NOT] BETWEEN B AND C |
基本数据类型 |
如果A,B或者C任一为NULL,则结果为NULL。如果A的值大于等于B而且小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可达到相反的效果。 |
|
A IS NULL |
所有数据类型 |
如果A等于NULL,则返回TRUE,反之返回FALSE |
|
A IS NOT NULL |
所有数据类型 |
如果A不等于NULL,则返回TRUE,反之返回FALSE |
|
IN(数值1, 数值2) |
所有数据类型 |
使用 IN运算显示列表中的值 |
|
A [NOT] LIKE B |
STRING 类型 |
B是一个SQL下的简单正则表达式,也叫通配符模式,如果A与其匹配的话,则返回TRUE;反之返回FALSE。B的表达式说明如下:‘x%’表示A必须以字母‘x’开头,‘%x’表示A必须以字母’x’结尾,而‘%x%’表示A包含有字母’x’,可以位于开头,结尾或者字符串中间。如果使用NOT关键字则可达到相反的效果。 |
|
A RLIKE B, A REGEXP B |
STRING 类型 |
B是基于java的正则表达式,如果A与其匹配,则返回TRUE;反之返回FALSE。匹配使用的是JDK中的正则表达式接口实现的,因为正则也依据其中的规则。例如,正则表达式必须和整个字符串A相匹配,而不是只需与其字符串匹配。 |
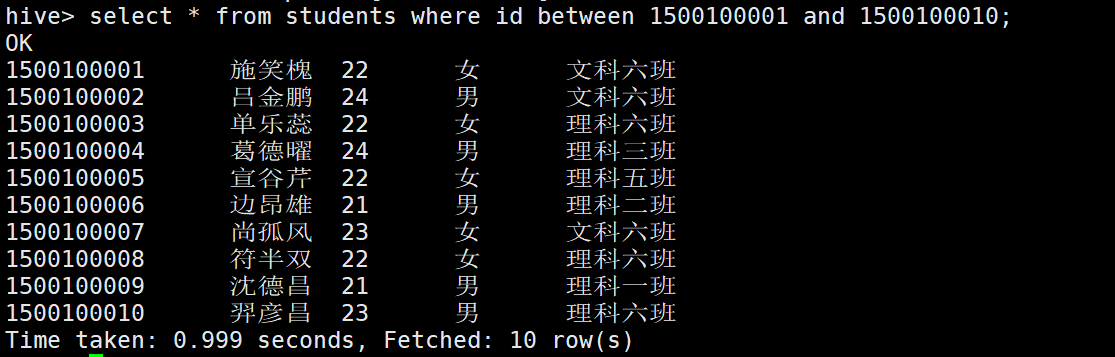
2 .数值计算
取整函数(四舍五入):round
向上取整:ceil
向下取整:floor
like、rlike、
(1)查找名字以A开头的员工信息
hive (default)> select * from emp where ename LIKE 'A%';
(2)查找名字中第二个字母为A的员工信息
hive (default)> select * from emp where ename LIKE '_A%';
(3)查找名字中带有A的员工信息
hive (default)> select * from emp where ename RLIKE '[A]';
.
3.日期函数
1 select from_unixtime(1610611142,'YYYY/MM/dd HH:mm:ss');
2unix_timestamp(),获取当前时间的时间戳
3 select from_unixtime(unix_timestamp(),'YYYY/MM/dd HH:mm:ss');
4 // '2021年01月14日' -> '2021-01-14'
6 select from_unixtime(unix_timestamp('2021年01月14日','yyyy年MM月dd日'),'yyyy-MM-dd');
8 select from_unixtime(unix_timestamp("04-2021-16","MM-yyyy-dd"),"yyyy/MM/dd");
4.字符串函数
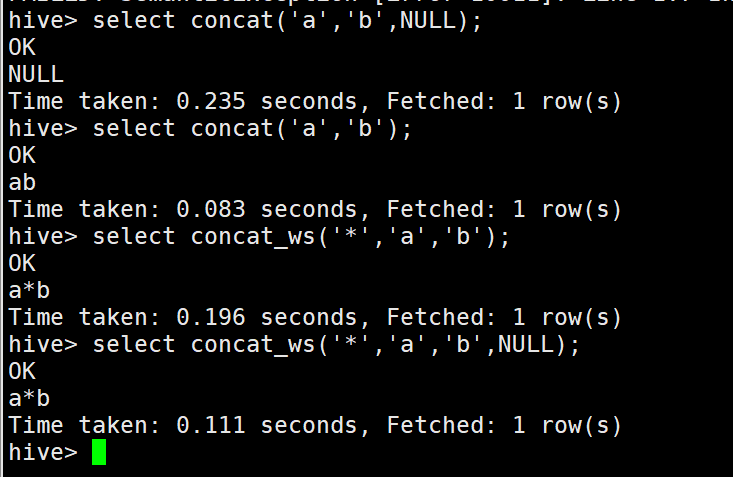
1)cancat()字符串拼接 当有空值则为NULL
2)cancat_ws()指定可以指定分隔符,并且会自动忽略NULL
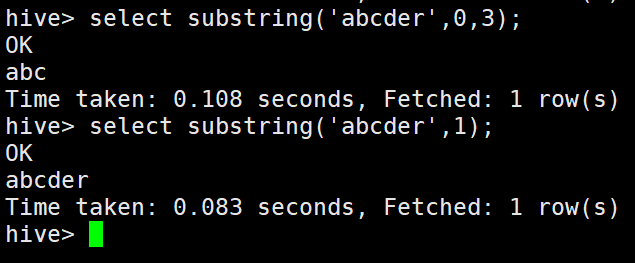
 3)substring字符串的截取
3)substring字符串的截取
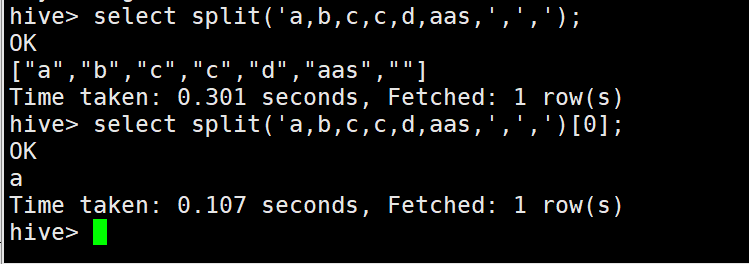
4)split字符串的切分
5)explode列转行

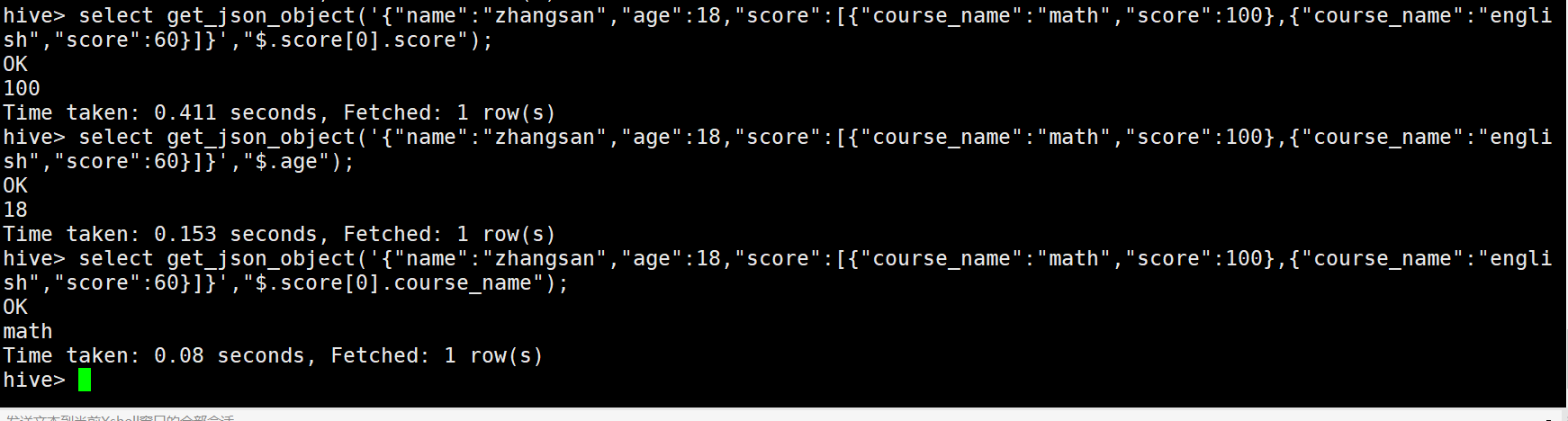
解析json格式的数据
select get_json_object
('{"name":"zhangsan",
"age":18,
"score":[{"course_name":"math","score":100},{"course_name":"english","score":60}]}',
"$.score[0].score");
6) Hive中的wordcount
create table words(
words string
)row format delimited fields terminated by '|'; // 数据
hello,java,hello,java,scala,python
hbase,hadoop,hadoop,hdfs,hive,hive
hbase,hadoop,hadoop,hdfs,hive,hive select word,count(*) from (select explode(split(words,',')) word from words) a group by a.word;
4.开窗函数
##### row_number:无并列排名
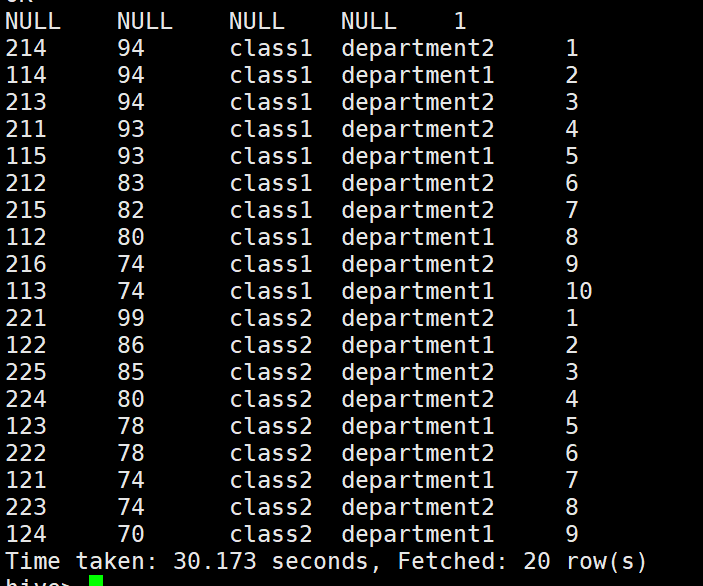
分组求TOPN
select * from (select *, row_number() over(partition by clazz order by score desc)as s from new_score)tt where tt.s<=3;
用法: select xxxx, row_number() over(partition by 分组字段 order by 排序字段 desc) as rn from tb group by xxxx
##### dense_rank:有并列排名,并且依次递增
hive> select *, row_number() over(partition by clazz order by score desc)as s,
> dense_rank() over(partition by clazz order by score desc)as s from new_score;
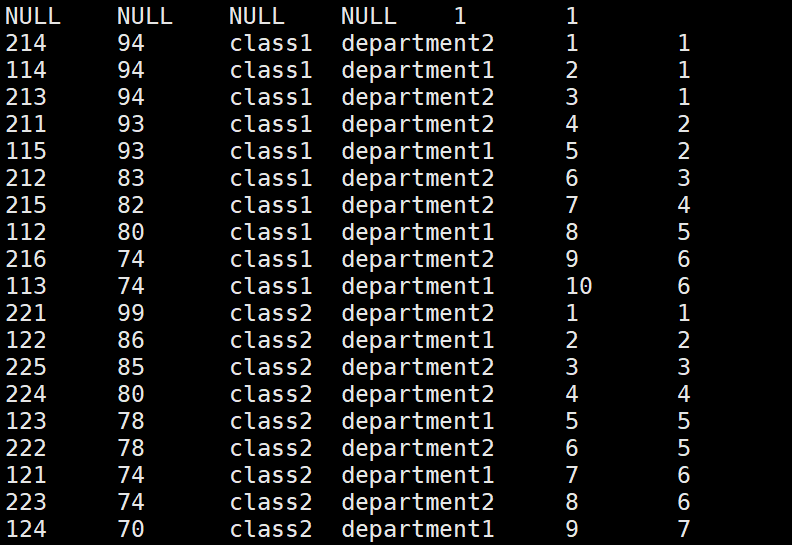
##### rank:有并列排名,不依次递增
hive> select *, row_number() over(partition by clazz order by score desc)as s,
> dense_rank() over(partition by clazz order by score desc),
> rank() over(partition by clazz order by score desc)from new_score;
##### percent_rank:(rank的结果-1)/(分区内数据的个数-1)
select *, row_number() over(partition by clazz order by score desc)as s,
> rank() over(partition by clazz order by score desc),
> percent_rank() over(partition by clazz order by score desc)from new_score;

##### cume_dist:计算某个窗口或分区中某个值的累积分布。
select *, row_number() over(partition by clazz order by score desc)as s,
> rank() over(partition by clazz order by score desc),
> percent_rank() over(partition by clazz order by score desc),
> cume_dist() over(partition by clazz order by score desc) from new_score;

> 假定升序排序,则使用以下公式确定累积分布: 小于等于当前值x的行数 / 窗口或partition分区内的总行数。其中,x 等于 order by 子句中指定的列的当前行中的值。
##### NTILE(n):对分区内数据再分成n组,然后打上组号
##### max、min、avg、count、sum:基于每个partition分区内的数据做对应的计算
5.窗口帧格式
格式1:按照行的记录取值
ROWS BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
格式2:当前所指定值的范围取值
RANGE BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
注意:
UNBOUNDED:无界限
CURRENT ROW:当前行
rows格式1:前2行+当前行+后两行
sum(score) over (partition by clazz order by score desc rows between 2 PRECEDING and 2 FOLLOWING)
rows格式2:前记录到最末尾的总和
sum(score) over (partition by clazz order by score desc rows between CURRENT ROW and UNBOUNDED FOLLOWING)
range格式1: 如果当前值在80,取值就会落在范围在80-2=78和80+2=82组件之内的行
max(score) over (partition by clazz order by score desc range between 2 PRECEDING and 2 FOLLOWING)
Hive语法及其进阶(二)的更多相关文章
- Hive语法及其进阶(一)
1.Hive完整建表 1 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name( 2 [(col_name data_type [COMMENT col ...
- mysql进阶(二十八)MySQL GRANT REVOKE用法
mysql进阶(二十八)MySQL GRANT REVOKE用法 MySQL的权限系统围绕着两个概念: 认证->确定用户是否允许连接数据库服务器: 授权->确定用户是否拥有足够的权限执 ...
- mysql进阶(二十六)MySQL 索引类型(初学者必看)
mysql进阶(二十六)MySQL 索引类型(初学者必看) 索引是快速搜索的关键.MySQL 索引的建立对于 MySQL 的高效运行是很重要的.下面介绍几种常见的 MySQL 索引类型. 在数 ...
- Java进阶(二十五)Java连接mysql数据库(底层实现)
Java进阶(二十五)Java连接mysql数据库(底层实现) 前言 很长时间没有系统的使用java做项目了.现在需要使用java完成一个实验,其中涉及到java连接数据库.让自己来写,记忆中已无从搜 ...
- Hive框架基础(二)
* Hive框架基础(二) 我们继续讨论hive框架 * Hive的外部表与内部表 内部表:hive默认创建的是内部表 例如: create table table001 (name string , ...
- Python进阶(二)----函数参数,作用域
Python进阶(二)----函数参数,作用域 一丶形参角度:*args,动态位置传参,**kwargs,动态关键字传参 *args: 动态位置参数. 在函数定义时, * 将实参角度的位置参数聚合 ...
- iOS开发——语法篇OC篇&高级语法精讲二
Objective高级语法精讲二 Objective-C是基于C语言加入了面向对象特性和消息转发机制的动态语言,这意味着它不仅需要一个编译器,还需要Runtime系统来动态创建类和对象,进行消息发送和 ...
- Swift语法基础入门二(数组, 字典, 字符串)
Swift语法基础入门二(数组, 字典, 字符串) 数组(有序数据的集) *格式 : [] / Int / Array() let 不可变数组 var 可变数组 注意: 不需要改变集合的时候创建不可变 ...
- mysql进阶(二十九)常用函数
mysql进阶(二十九)常用函数 一.数学函数 ABS(x) 返回x的绝对值 BIN(x) 返回x的二进制(OCT返回八进制,HEX返回十六进制) CEILING(x) 返回大于x的最小整数值 EXP ...
随机推荐
- new和delete关键字
new关键字创建出来的对象位于什么地方?很明显嘛,new关键字创建出来的对象一定位于堆空间,这种说法一定正确吗?本篇博客帮你揭开其神秘的面纱. 被忽略的事实new/delete的本质是C++预定义的操 ...
- 实现Comparable接口
1 import java.util.TreeSet; 2 3 4 /** 5 * PriorityQueue, TreeSet是排序集合,存储的对象必须实现Comparable接口. 6 * 原因是 ...
- Spark消费Kafka如何实现精准一次性消费?
1.定义 精确一次消费(Exactly-once) 是指消息一定会被处理且只会被处理一次.不多不少就一次处理. 如果达不到精确一次消费,可能会达到另外两种情况: 至少一次消费(at least onc ...
- python内置函数:sorted中的参数key
x.sort和sorted函数中参数key的使用 介绍 python中,列表自带了排序函数sort >>> l = [1, 3, 2] >>> l.sort() & ...
- Shell脚本逐行读取文本内容并拆分,根据条件筛选文件
时间:2018-11-13 整理:byzqy 需求: 最近帮朋友写了一段脚本,他的需求是根据一份产品清单,去服务器上捞取对应产品编号的测试Log,数量大概有9000~10000条左右.文本内容大致如下 ...
- AI 常见术语总结
BN(Batch-normalization)在一层的输出上计算所有特征映射的均值和标准差,并且使用这些值规范化它们的响应.因此使得所有神经图(neural maps)在同样范围有响应,而且是零均 ...
- Linux centos7 mysql 的安装配置
2021-07-21 1. 创建用户 # 创建用户useradd mysql# 修改密码 passwd mysql 2. 下载 wget 网址 3. 解压 # 创建安装文件夹mkdir app# 解压 ...
- vue element-ui 做分页功能之封装
在 vue 项目中的 components 中 创建一个 文件夹,文件夹里创建一个 name(这个名字你随意取).vue <template> <div class=" ...
- Mybatis(四)——
test https://www.cnblogs.com/chiaki/p/14529418.html
- noip模拟36
\(\color{white}{\mathbb{荷花映日,莲叶遮天,名之以:残荷}}\) 今天再次翻车掉出前十 开题看错 \(t1\) 以为操作2的值固定发现是个简单题,然后 \(t2\) 开始大力 ...