一款好用的数据血缘关系在线工具--SQLFlow
l 数据血缘关系(data lineage)
数据血缘属于数据治理中的一个概念,是在数据溯源的过程中找到相关数据之间的联系,它是一个逻辑概念。数据治理中经常提到血缘分析,血缘分析是保证数据融合的一个手段,通过血缘分析实现数据融合处理的可追溯。数据血缘是指数据产生的链路,直白点说,就是我们这个数据是怎么来的,经过了哪些过程和阶段。
l SQLFlow是什么?
SQLFlow 通过分析各种数据库对象定义(DDL)语句、数据操作(DML) 语句、ETL/ELT中使用的存储过程(Proceudre,Function)、 触发器(Trigger)和其他 SQL 脚本,给出完整的数据血缘关系。它不仅可以展现对象间的关系,也可以帮你提取表的字段。
参考链接:https://sqlflow.gudusoft.com/?utm_source=cnblogs&utm_medium=blog&utm_campaign=my-nick-name#/
l 示例说明
新建表
CREATE TABLE Test1(ID INT,NAME VARCHAR(36));
CREATE TABLE Test2(ID INT,NAME VARCHAR(36));
新建视图
CREATE VIEW v_test1 AS SELECT A.NAME FROM Test1 A;
CREATE VIEW v_test2 AS SELECT A.* FROM Test1 A,Test2 B WHERE A.ID=B.ID;
CREATE VIEW v_test3 AS SELECT A.*,b.* FROM Test1 A,Test2 B WHERE A.ID=B.ID;
默认情况下仅显示Dataflow,即数据流,可以从图中清晰的看到每个视图中的具体列是由哪里流过来的。

l 视图v_test1仅包含来源于Test1的name列;
l 视图v_test2包含来源于Test1的ID,name列,虽在视图定义中和Test2进行了关联,但是由于数据全部来源于Test1,所以在Dataflow中并不体现;
l 视图v_test3包含来源于Test1和Test2中所有列。
看到此处,您可能疑惑,视图v_test2展现的虽然只是来源于Test1的数据,但是如果您想了解Test1和Test2是否有关联逻辑,该如何做?
打开【Setting】-【impact】选项,可以看到具体的表间的逻辑关系。
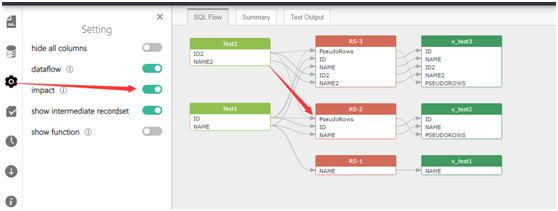
说明:
l SQLFlow数据流使用【实线】显示,逻辑关系使用【虚线】显示;
l 此时的关系集合中多了一个伪列(PseudoRows),用于表示该数据集合是由多表关联而来。
此时您能够更加清晰的看到数据血缘关系以及各原表间的关联关系。
一款好用的数据血缘关系在线工具--SQLFlow的更多相关文章
- 血缘关系分析工具SQLFLOW--实践指南
SQLFlow 是用于追溯数据血缘关系的工具,它自诞生以来以帮助成千上万的工程师即用户解决了困扰许久的数据血缘梳理工作. 数据库中视图(View)的数据来自表(Table)或其他视图,视图中字段(Co ...
- 使用grabit分析mysql数据库中的数据血缘关系
使用grabit分析mysql数据库中的数据血缘关系 Grabit 是一个辅助工具,用于从数据库.GitHub 等修订系统.bitbucket 和文件系统等各种来源收集 SQL 脚本和存储过程,然后将 ...
- 马哈鱼数据血缘分析器分析case-when语句
马哈鱼数据血缘分析器是一个分析数据血缘关系的平台,可以在线直接递交 SQL 语句进行分析,也可以选择连接指定数据库获取 metadata.从本地上传文件目录.或从指定 git 仓库获取脚本进行分析. ...
- 数据治理中Oracle SQL和存储过程的数据血缘分析
数据治理中Oracle SQL和存储过程的数据血缘分析 数据治理中的一个重要基础工作是分析组织中数据的血缘关系.有了完整的数据血缘关系,我们可以用它进行数据溯源.表和字段变更的影响分析.数据合规性 ...
- 基于spark logicplan的表血缘关系解析实现
随着公司平台用户数量与表数量的不断增多,各种表之间的数据流向也变得更加复杂,特别是某个任务中会对源表读取并进行一系列复杂的变换后又生成新的数据表,因此需要一套表血缘关系解析机制能清晰地解析出每个任务所 ...
- 基于MaxCompute InformationSchema进行血缘关系分析
一.需求场景分析 在实际的数据平台运营管理过程中,数据表的规模往往随着更多业务数据的接入以及数据应用的建设而逐渐增长到非常大的规模,数据管理人员往往希望能够利用元数据的分析来更好地掌握不同数据表的血缘 ...
- 利用job提升马哈鱼数据血缘分析效率
利用job提升马哈鱼数据血缘分析效率 一.Job基本知识 前面文章中已介绍马哈鱼的基本功能,其中一个是job,job其实是一个任务集合处理的概念,就是让用户通过job,可以一次递交所有需要处理的 SQ ...
- Web中树形数据(层级关系数据)的实现—以行政区树为例
在Web开发中常常遇到树形数据的操作,如菜单.组织机构.行政区(省.市.县)等具有层级关系的数据. 以下以行政区为例说明树形数据(层级关系数据)的存储以及实现,效果如图所看到的. 1 数据库表结构设计 ...
- 使用neo4j-import导入数据及关系
背景 上节我们了解了什么是图数据库,作为研究对象的neo4j的特点,优缺点以及基本的环境搭建. 现在我们要讲存储在csv中的通话记录数据导入到neo4j中去,并且可以通过cql去查询导入的数据及关系 ...
随机推荐
- 从RocketMQ的Broker源码层面验证一下这两个点
本篇博客会从源码层面,验证在RocketMQ基础概念剖析,并分析一下Producer的底层源码中提到的结论,分别是: Broker在启动时,会将自己注册到所有的NameServer上 Broker在启 ...
- 《逆向工程核心原理》Windows消息钩取
DLL注入--使用SetWindowsHookEx函数实现消息钩取 MSDN: SetWindowsHookEx Function The SetWindowsHookEx function inst ...
- 文件连接--ln
ln -n file1 file2 将文件2设置为文件1的软连接:file1和file2 任何一个改动都会反馈到另一方,删除源文件, 软连接文件不可用 ln -s file1 file2 将文件2 ...
- [源码解析] 并行分布式任务队列 Celery 之 Task是什么
[源码解析] 并行分布式任务队列 Celery 之 Task是什么 目录 [源码解析] 并行分布式任务队列 Celery 之 Task是什么 0x00 摘要 0x01 思考出发点 0x02 示例代码 ...
- Ray Tracing in one Weekend 阅读笔记
目录 一.创建Ray类,实现背景 二.加入一个球 三.让球的颜色和其法线信息相关 四.多种形状,多个碰撞体 五.封装相机类 六.抗锯齿 七.漫发射 八.抽象出材料类(编写metal类) 九.介质材料( ...
- libnet的使用详解
最近搬砖需要对libnet进行介绍在这里对知识进行汇总. 1.libnet简介 在libnet出现以前,如果要构造数据包并发送到网络中,程序员要通过一些复杂的接口来处理.libnet的出现,为程序员提 ...
- Parentheses Balance UVA - 673
You are given a string consisting of parentheses () and []. A string of this type is said to be corr ...
- 【Spring】循环依赖
@ 目录 循环依赖 是什么? Spring是如何解决的? 源码分析 细节 循环依赖 是什么? 简单的来说就是对象a的属性中引用了对象b,对象b的属性中引用了对象c......最后引用到a. < ...
- Word 查找和替换字符串方法
因为项目需要通过word模板替换字符串 ,来让用户下载word, 就在网上找了找word查找替换字符串的库或方法,基本上不是收费,就是无实现,或者方法局限性太大 .docx 是通过xml来存储文字和其 ...
- 1016 Phone Bills
A long-distance telephone company charges its customers by the following rules: Making a long-distan ...