基于MaxCompute InformationSchema进行血缘关系分析
一、需求场景分析
在实际的数据平台运营管理过程中,数据表的规模往往随着更多业务数据的接入以及数据应用的建设而逐渐增长到非常大的规模,数据管理人员往往希望能够利用元数据的分析来更好地掌握不同数据表的血缘关系,从而分析出数据的上下游依赖关系。
本文将介绍如何去根据MaxCompute InformationSchema中作业ID的输入输出表来分析出某张表的血缘关系。
二、方案设计思路
MaxCompute Information_Schema提供了访问表的作业明细数据tasks_history,该表中有作业ID、input_tables、output_tables字段记录表的上下游依赖关系。根据这三个字段统计分析出表的血缘关系
1、根据某1天的作业历史,通过获取tasks_history表里的input_tables、output_tables、作业ID字段的详细信息,然后分析统计一定时间内的各个表的上下游依赖关系。
2、根据表上下游依赖推测出血缘关系。
三、方案实现方法
参考示例一:
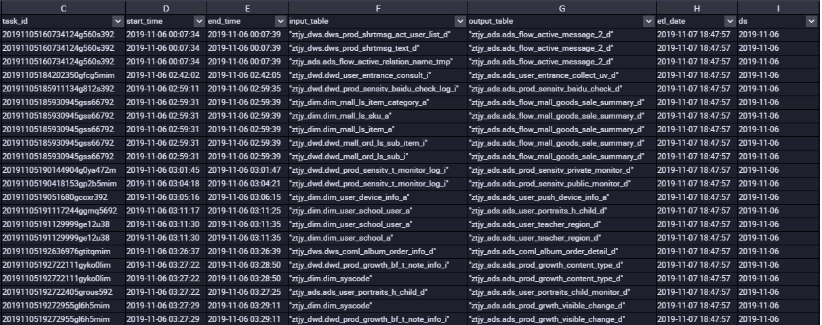
(1)根据作业ID查询某表上下游依赖SQL处理如下:

结果如下图所示:

(2)根据结果可以分析得出每张表张表的输入表输出表以及连接的作业ID,即每张表的血缘关系。
血缘关系位图如下图所示:

中间连线为作业ID,连线起始为输入表,箭头所指方向为输出表。
参考示例二:
以下方式是通过设置分区,结合DataWorks去分析血缘关系:
(1)设计存储结果表Schema

(2)关键解析sql

(3)任务依赖关系


(4)最终血缘关系
以上血缘关系的分析是根据自己的思路实践去完成。真实的业务场景需要大家一起去验证。所以希望大家有需要的可以根据自己的业务需求去做相应的sql修改。如果有发现处理不当的地方希望多多指教。我在做相应的调整。
本文作者:刘-建伟
本文为阿里云内容,未经允许不得转载。
基于MaxCompute InformationSchema进行血缘关系分析的更多相关文章
- 血缘关系分析工具SQLFLOW--实践指南
SQLFlow 是用于追溯数据血缘关系的工具,它自诞生以来以帮助成千上万的工程师即用户解决了困扰许久的数据血缘梳理工作. 数据库中视图(View)的数据来自表(Table)或其他视图,视图中字段(Co ...
- 基于MaxCompute InformationSchema进行冷门表热门表访问分析
一.需求场景分析 在实际的数据平台运营管理过程中,数据表的规模往往随着更多业务数据的接入以及数据应用的建设而逐渐增长到非常大的规模,数据管理人员往往希望能够利用元数据的分析来更好地掌握不同数据表的使用 ...
- 使用grabit分析mysql数据库中的数据血缘关系
使用grabit分析mysql数据库中的数据血缘关系 Grabit 是一个辅助工具,用于从数据库.GitHub 等修订系统.bitbucket 和文件系统等各种来源收集 SQL 脚本和存储过程,然后将 ...
- SQLFlow——一个强大的可视化SQL关系分析工具
SQLFlow 摘要 本文主要介绍SQLFlow是什么,以及它的功能及使用场景 SQLFlow是什么 SQLFlow是一个可视化的在线处理SQL对象依赖关系的工具,只需要上传你的SQL脚本,它可以自动 ...
- 马哈鱼数据血缘分析器分析case-when语句
马哈鱼数据血缘分析器是一个分析数据血缘关系的平台,可以在线直接递交 SQL 语句进行分析,也可以选择连接指定数据库获取 metadata.从本地上传文件目录.或从指定 git 仓库获取脚本进行分析. ...
- 基于spark logicplan的表血缘关系解析实现
随着公司平台用户数量与表数量的不断增多,各种表之间的数据流向也变得更加复杂,特别是某个任务中会对源表读取并进行一系列复杂的变换后又生成新的数据表,因此需要一套表血缘关系解析机制能清晰地解析出每个任务所 ...
- 基于MaxCompute打造轻盈的人人车移动端数据平台
摘要: 2019年1月18日,由阿里巴巴MaxCompute开发者社区和阿里云栖社区联合主办的“阿里云栖开发者沙龙大数据技术专场”走近北京联合大学,本次技术沙龙上,人人车大数据平台负责人吴水永从人人车 ...
- 基于MaxCompute的媒体大数据开放平台建设
摘要:随着自媒体的发展,传统媒体面临着巨大的压力和挑战,新华智云运用大数据和人工智能技术,致力于为媒体行业赋能.通过媒体大数据开放平台,将媒体行业全网数据汇总起来,借助平台数据处理能力和算法能力,将有 ...
- 基于MaxCompute的数仓数据质量管理
声明 本文中介绍的非功能性规范均为建议性规范,产品功能无强制,仅供指导. 参考文献 <大数据之路——阿里巴巴大数据实践>——阿里巴巴数据技术及产品部 著. 背景及目的 数据对一个企业来说已 ...
随机推荐
- 再谈MV*(MVVM MVP MVC)模式的设计原理—封装与解耦
精炼并增补于:界面之下:还原真实的MV*模式 图形界面的应用程序提供给用户可视化的操作界面,这个界面提供给数据和信息.用户输入行为(键盘,鼠标等)会执行一些应用逻辑,应用逻辑(application ...
- 瀑布布局(waterflall flow)实现
瀑布流,又称瀑布流式布局.是比较流行的一种网站页面布局,视觉表现为参差不齐的多栏布局,随着页面滚动条向下滚动.这种布局还会不断加载数据块并附加至当前尾部.最早采用此布局的网站是Pinterest,逐渐 ...
- spring5源码分析系列(一)——spring5框架模块
spring总共大约20个模块,这些模块被整合在核心容器(Core Container).AOP和设备支持.数据访问及集成.Web.报文发送.Test 6个模块集合. 组成Spring框架的每个模块集 ...
- Python 过滤HTML实体符号简易方法
html_tag = {' ': '\n', '"': '\"', '&': '', '<': '<', '>': '>', '' ...
- 小记----------lombok插件idea的安装&常见注解解释及小案例
Lombok安装插件 软件:idea 2018.3.6版本 1.打开settings
- 什么是云数据库POLARDB
POLARDB是阿里巴巴自主研发的下一代关系型分布式云原生数据库,目前兼容三种数据库引擎:MySQL.Oracle.PostgreSQL.计算能力最高可扩展至1000核以上,存储容量最高可达 100T ...
- C++多线程基础学习笔记(二)
先总结延申以下前面(一)所讲的内容. 主线程从main()函数开始执行,我们创建的线程也需要一个函数作为入口开始执行,所以第一步先初始化函数. 整个进程是否执行完毕的标志是主线程是否执行完毕,一般情况 ...
- 了解MyISAM与InnoDB的索引差异(转)
出处原文: 1分钟了解MyISAM与InnoDB的索引差异 数据库的索引分为主键索引(Primary Inkex)与普通索引(Secondary Index).InnoDB和MyISAM是怎么利用B+ ...
- JS基础_数据类型-Number类型
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- vm文件
<html> <head> <title>编队管理</title> </head> <style type="text/cs ...