PubMed数据下载
目标站点分析
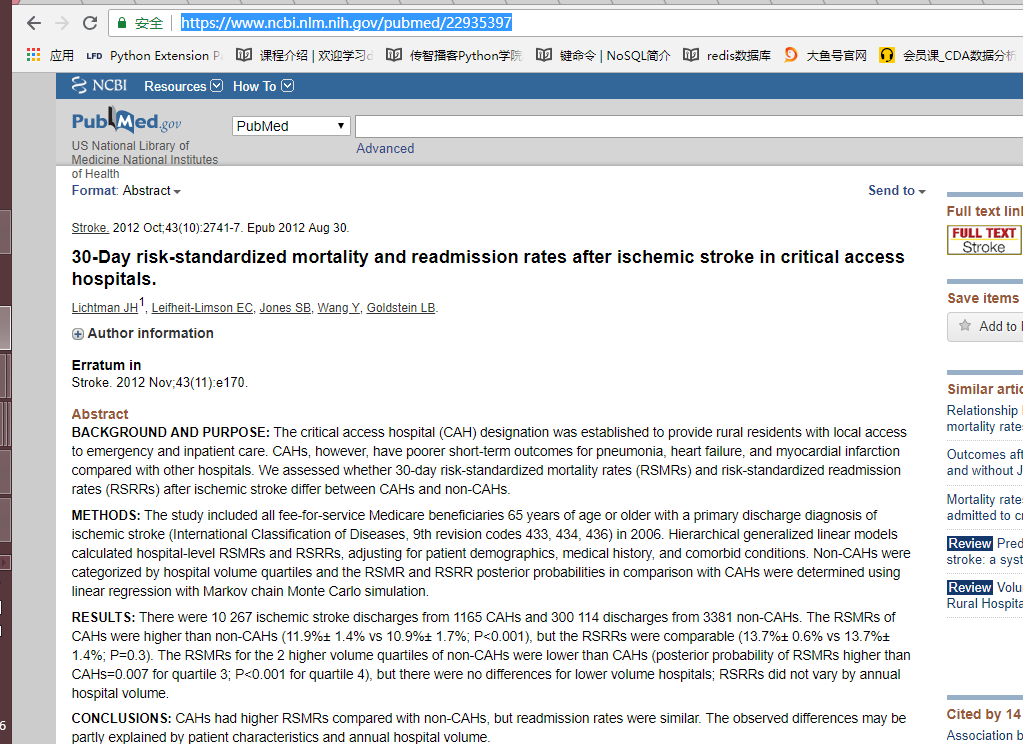
目标:抓取页面中的机构名称,日期,标题,作者, 作者信息, 摘要
程序实现
# -*- coding: utf-8 -*- """
@Datetime: 2019/3/6
@Author: Zhang Yafei
"""
import os
import re
import time
from concurrent.futures import ThreadPoolExecutor
import traceback import pandas as pd
import requests
from pyquery import PyQuery as pq headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'} BASE_DIR = 'html' if not os.path.exists(BASE_DIR):
os.mkdir(BASE_DIR) class PubMed(object):
def __init__(self, url):
self.url = url
# self.url = 'https://www.ncbi.nlm.nih.gov/pubmed/{}'.format(id)
self.retry = 0 def download(self):
try:
response = requests.get(self.url, headers=headers, timeout=20)
if response.status_code == 200:
self.parse(response.content)
except Exception as e:
traceback.print_exc()
print('error:' + self.url)
while True:
self.retry += 1
if self.retry < 5:
try:
response = requests.get(self.url, headers=headers, timeout=15)
if response.status_code == 200:
self.parse(response.content)
return
except Exception as e:
print(e)
time.sleep(10)
else:
print(self.url + '下载失败')
return def parse(self, response):
doc = pq(response, parser='html')
periodical_item = doc('.cit')
periodical = periodical_item.children().text()
try:
periodical_datetime = re.search('</a>(.*?);', periodical_item.__str__()).group(1)
except AttributeError:
periodical_datetime = re.search('</a>(.*?).', periodical_item.__str__()).group(1)
title = doc('.rprt_all h1').text()
authors_items = doc('.auths a').items()
authors = ','.join(list(map(lambda x: x.text(), authors_items)))
author_info = doc('.ui-ncbi-toggler-slave dd').text()
abstract = doc('.abstr').text()
data_dict = {'url': [self.url], 'periodical': [periodical], 'periodical_datetime': [periodical_datetime],
'title': [title], 'authors': [authors], 'author_info': [author_info], 'abstract': [abstract]}
self.write_csv(filename='pubmed_result.csv', data=data_dict)
print(self.url + '下载完成') @staticmethod
def write_csv(filename, data=None, columns=None, header=False):
""" 写入 """
if header:
df = pd.DataFrame(columns=columns)
df.to_csv(filename, index=False, mode='w')
else:
df = pd.DataFrame(data=data)
df.to_csv(filename, index=False, header=False, mode='a+') def filter_url_list(urls_list):
df = pd.read_csv('pubmed_result.csv')
has_urls = df.url.tolist()
url_list = set(urls_list) - set(has_urls)
print('共:{} 完成:{} 还剩:{}'.format(len(urls_list), len(has_urls), len(url_list)))
return list(url_list) def read_data():
df = pd.read_excel('data.xlsx', header=None)
return df[0].tolist() def main(url):
""" 主函数 """
pubmed = PubMed(url=url)
pubmed.download() if __name__ == '__main__':
url_list = read_data()
if not os.path.exists('pubmed_result.csv'):
columns = ['url', 'periodical', 'periodical_datetime', 'title', 'authors', 'author_info', 'abstract']
PubMed.write_csv(filename='pubmed_result.csv', columns=columns, header=True)
else:
url_list = filter_url_list(url_list) pool = ThreadPoolExecutor()
pool.map(main, url_list)
pool.shutdown() # 写入excel
df = pd.read_csv('pubmed_result.csv')
writer = pd.ExcelWriter('pubmed_result.xlsx')
df.to_excel(writer, 'table', index=False)
writer.save()
PubMed数据下载的更多相关文章
- tensorflow学习笔记三:实例数据下载与读取
一.mnist数据 深度学习的入门实例,一般就是mnist手写数字分类识别,因此我们应该先下载这个数据集. tensorflow提供一个input_data.py文件,专门用于下载mnist数据,我们 ...
- ios的网络数据下载和json解析
ios的网络数据下载和json解析 简介 在本文中,笔者将要给大家介绍如何使用nsurlconnection 从网上下载数据,以及解析json数据格式,以及如何显示数据和图片的异步下载显示. 涉及的知 ...
- 腾讯QQ群数据下载方法(7000万个qq群资料全泄漏)
仔细读完一定能找到自己需要的东西 据新华网报道,国内知名安全漏洞监测平台乌云20日公布报告称,腾讯QQ群关系数据被泄露,网上可以轻易就能找到数据下载链接,根据这些数据,通过QQ号可以查询到备注姓名.年 ...
- ios 网络数据下载和JSON解析
ios 网络数据下载和JSON解析 简介 在本文中笔者将要给大家介绍ios中如何利用NSURLConnection从网络上下载数据,如何解析下载下来的JSON数据格式,以及如何显示数据和图片的异步下载 ...
- iOS之网络数据下载和JSON解析
iOS之网络数据下载和JSON解析 简介 在本文中笔者将要给大家介绍IOS中如何利用NSURLconnection从网络上下载数据以及如何解析下载下来的JSON数据格式,以及如何显示数据和托图片的异步 ...
- Asp.Net MVC 实现将Easy-UI展示数据下载为Excel 文件
在一个项目中,需要做一个将Easy-UI界面展示数据下载为Excel文件的功能,经过一段时间努力,完成了一个小Demo.界面如下: 但按下导出Excel后,Excel文件将会下载到本地,在office ...
- OSM数据下载地址
1.OSM数据下载地址 官网下载: http://planet.openstreetmap.org/ GeoFabrik:http://www.geofabrik.de/ Metro Extracts ...
- 医学图像数据(三)——TCIA部分数据下载方式
前为止,本人还没有找到不需要账号的就可以部分下载的方式,因此这里讲的是需要注册账号下载部分数据的方法. 注意:下载部分数据需要注册账号 注册账号网址:https://public.cancerimag ...
- DEM数据及其他数据下载
GLCF大家都知道吧?http://glcf.umiacs.umd.edu/data/ +++++++++++++++去年12月份听遥感所一老师说TM08初将上网8万景,可是最近一直都没看到相关的网页 ...
随机推荐
- sed 收集
#删除倒数第二行的最后的逗号 一条命令 sed ':1;$b;N;/InnoDB/!b1;s/,\n)/\n)/'
- kubernetes 构架
- MySQL数据库实现分页查询的SQL语句写法!
一:分页需求: 客户端通过传递start(页码),limit(每页显示的条数)两个参数去分页查询数据库表中的数据,那我们知道MySql数据库提供了分页的函数limit m,n,但是该函数的用法和我们的 ...
- 【XSY2762】插线板 分块
题目大意 有\(n\)个插线板,每个插线板会在\(l_i\)时刻初插入到队列中(队列是按插线板的编号排序的),\(r_i\)时刻末移除. 插入一个插线板时会对当前所有接在队列中这个插线的下一个插线板上 ...
- 【XSY2679】修墙 最短路
题目描述 有一个\((n+1)\times (m+1)\)的网格,每条边都有一个边权.有一些格子是城市.你要用一个环圈住所有城市,要求环上所有边的边权和最小.重合的边边权算多次.保证左上角\((1,1 ...
- hdu 6253 (bfs打表)
链接:http://acm.hdu.edu.cn/showproblem.php?pid=6253 题意: 马可以往一个方向走两步,然后转个弯走一步,这样算一次动作,求问马n次动作后,能到达多少个点, ...
- Angular、React.js 和Node.js到底选谁?
为了工作,程序员选择正确的框架和库来构建应用程序是至关重要的,这也就是为什么Angular和React之间有着太多的争议.Node.js的出现,让这场战争变得更加复杂,虽然有选择权通常是一件很棒的事情 ...
- emwin之错误使用控件函数导致死机现象
@2018-10-15 导致死机的代码示例如下 /** * @brief widget ID define * @{ */ #define ID_WINDOW_0 (GUI_ID_USER + 0x0 ...
- https搭建实例
:(用的)https://www.coderecord.cn/lets-encrypt-wildcard-certificates.html :acme.shvim .acme.sh/account. ...
- http_proxy_module模块常用参数
Nginx的upstream模块相当于是建立一个函数库一样,把后端的服务器地址放在了一个池子里,而proxy模块则是从这个池子里调用了这些服务器. http_proxy_module模块常用参数: p ...