【机器学习】K均值算法(II)
k聚类算法中如何选择初始化聚类中心所在的位置。
在选择聚类中心时候,如果选择初始化位置不合适,可能不能得出我们想要的局部最优解。
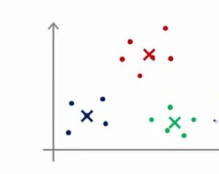
而是会出现一下情况:

为了解决这个问题,我们通常的做法是:
我们选取K<m个聚类中心。
然后随机选择K个训练样本的实例,之后令k个聚类中心分别与k个训练实例相等。
之后我们通常需要多次运行均值算法。每一次都重新初始化,然后在比较多次运行的k均值的结果,选择代价函数较小的结果。这种方法在k较小的时候可能会有效果,但是在K数量较多的时候不会有明显改善。
如何选取聚类数量
当我们研究聚类数量与畸变函数J的关系时候,发现“肘部法则”,也就是当k的数量逐渐增加时候,存在某一点成为J函数下降过程呢中的拐点。
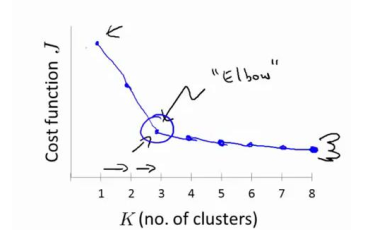
这个点之前,他的畸变的值迅速下降,在这个点之后,它的畸变值下变慢,那么看起来这个拐点通常会成为最合适的值。不过在实际情况中,我们会选择K值的数量取决于用聚类算法所需要解决的实际问题的目的出发。根据实际情况的需要选择K值的数量。
【机器学习】K均值算法(II)的更多相关文章
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 机器学习算法之Kmeans算法(K均值算法)
Kmeans算法(K均值算法) KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑 ...
- 秒懂机器学习---k临近算法(KNN)
秒懂机器学习---k临近算法(KNN) 一.总结 一句话总结: 弄懂原理,然后要运行实例,然后多解决问题,然后想出优化,分析优缺点,才算真的懂 1.KNN(K-Nearest Neighbor)算法的 ...
- 使用K均值算法进行图片压缩
K均值算法 上一期介绍了机器学习中的监督式学习,并用了离散回归与神经网络模型算法来解决手写数字的识别问题.今天我们介绍一种机器学习中的非监督式学习算法--K均值算法. 所谓非监督式学习,是一种 ...
- K 均值算法-如何让数据自动分组
公号:码农充电站pro 主页:https://codeshellme.github.io 之前介绍到的一些机器学习算法都是监督学习算法.所谓监督学习,就是既有特征数据,又有目标数据. 而本篇文章要介绍 ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
随机推荐
- VS连接数据库字符串
在App.config配置文件中的<Configuration>节点中添加如下代码 <connectionStrings> // SQL Server 数据库 ...
- Docker 多主机方案
利用OpenVSwitch构建多主机Docker网络 [编者的话]当你在一台主机上成功运行Docker容器后,信心满满地打算将其扩展到多台主机时,却发现前面的尝试只相当于写了个Hello World的 ...
- JMETER之socket接口性能测试
公司的**产品经过换代升级,终于要上线了,纯java编码,包括POS(PC/安卓平板)版.WEB版.微信版,各终端通过 Webservice服务共享数据资源,因此Webservice各接口的性能测试就 ...
- R语言输出高质量图片
Rstudio画图之后保存的 图片格式如下 上面的几种格式可以直接插入word文档中,但是图片质量很低,锯齿感很明显.若生成PDF,为矢量图(不懂),但是不可以插入word文档中. 最简便的方法就是对 ...
- ffplay流程分析
void main() { is = stream_open(input_filename, file_iformat); } static VideoState *stream_open(const ...
- mysql join优化原理
http://blog.itpub.net/22664653/viewspace-1692317/ http://itindex.net/detail/46772-%E4%BC%98%E5%8C%96 ...
- Selenium分布式自动化测试平台 Standalone Server 4.0 搭建
最新的selenium测试平台大概有这么几个组件 Selenium Standalone Server: 用来搭建远程测试平台以及分布式测试. Selenium WebDriver: 最基础的用来创建 ...
- CSS 图像高级 径向渐变
径向渐变 径向渐变使用 radial-gradient 函数语法. 这个语法和线性渐变很类似, 可以指定渐变结束时的形状 以及它的大小. 默认来说,结束形状是一个椭圆形并且和容器的大小比例保持一致. ...
- django的内置分页
本节内容 自定义一个简单的内置分页 Django内置分页 Django内置分页扩展(继承) 自定义内置组件 自定义一个简单的内置分页 先用django自己自定制一个简单的内置分页,大概掌握内置分页的底 ...
- 聚宽投资研究获取A股05年至今全部数据
#用中正全指'000985.XSHG'获取全部A股数据pool=get_index_stocks('000985.XSHG') #date存储05年开始全部交易时间 date=get_price('0 ...