RDD





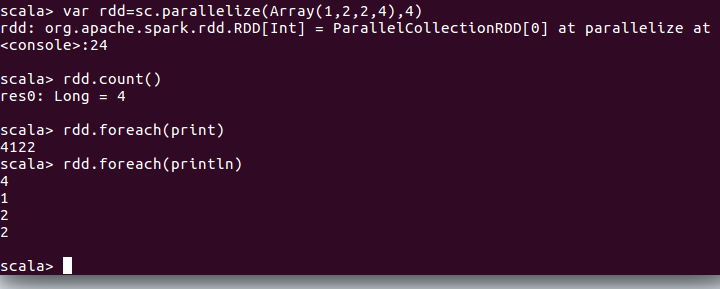




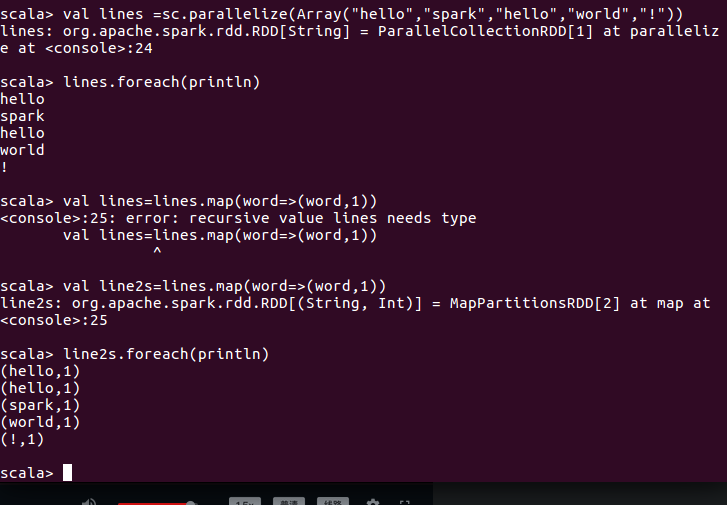

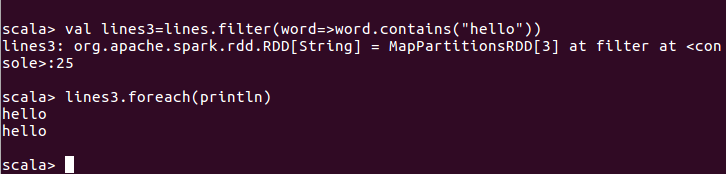

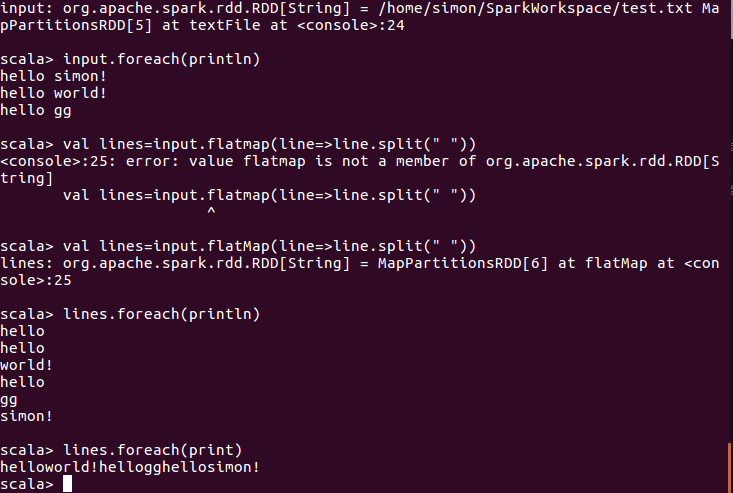
scala> val rdd1=sc.parallelize(Array("coffe","coffe","hellp","hellp","pandas","mokey") )
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[8] at parallelize at <console>:24
scala> val rdd1=sc.parallelize(Array("coffe","coffe","hellp","hellp","pandas","mokey"))
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[9] at parallelize at <console>:24
scala> val rdd2=sc.parallelize(Array("coe","coe","help","help","pandas","mokey"))
rdd2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[10] at parallelize at <console>:24
scala> val rdd1_distinct=rdd1.distinct()
rdd1_distinct: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[13] at distinct at <console>:25
scala> rdd1_distinct.foreach(println)
hellp
mokey
pandas
coffe
scala> val rdd_union=rdd1.union(rdd2)
rdd_union: org.apache.spark.rdd.RDD[String] = UnionRDD[14] at union at <console>:27
scala> rdd1_union.foreach(println)
<console>:24: error: not found: value rdd1_union
rdd1_union.foreach(println)
^
scala> rdd_union.foreach(println)
pandas
mokey
coffe
hellp
coffe
hellp
pandas
mokey
coe
help
help
coe
scala> val rdd_intersection=rdd1.intersession(rdd2)
<console>:27: error: value intersession is not a member of org.apache.spark.rdd.RDD[String]
val rdd_intersection=rdd1.intersession(rdd2)
^
scala> val rdd_intersection=rdd1.intersection(rdd2)
rdd_intersection: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[20] at intersection at <console>:27
scala> rdd_intersection.foreach(println)
mokey
pandas
scala> val rdd_sub=rdd1.subtract(rdd2)
rdd_sub: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[24] at subtract at <console>:27
scala> rdd_sub.foreach(prinln)
<console>:26: error: not found: value prinln
rdd_sub.foreach(prinln)
^
scala> rdd_sub.foreach(println)
coffe
coffe
hellp
hellp
scala>



scala> val rdd=sc.parallelize(Array(1,2,2,3))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[25] at parallelize at <console>:24
scala> rdd.collect()
res16: Array[Int] = Array(1, 2, 2, 3)
scala> rdd.reduce((x,y)=>x+y)
res18: Int = 8

scala> rdd.take(2)
res19: Array[Int] = Array(1, 2)
scala> rdd.take(3)
res20: Array[Int] = Array(1, 2, 2)
scala>

scala> rdd.top(1)
res21: Array[Int] = Array(3)
scala> rdd.top(2)
res22: Array[Int] = Array(3, 2)
scala> rdd.top(3)
res23: Array[Int] = Array(3, 2, 2)

RDD的更多相关文章
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- Spark笔记:复杂RDD的API的理解(下)
本篇接着谈谈那些稍微复杂的API. 1) flatMapValues:针对Pair RDD中的每个值应用一个返回迭代器的函数,然后对返回的每个元素都生成一个对应原键的键值对记录 这个方法我最开始接 ...
- Spark笔记:复杂RDD的API的理解(上)
本篇接着讲解RDD的API,讲解那些不是很容易理解的API,同时本篇文章还将展示如何将外部的函数引入到RDD的API里使用,最后通过对RDD的API深入学习,我们还讲讲一些和RDD开发相关的scala ...
- Spark笔记:RDD基本操作(下)
上一篇里我提到可以把RDD当作一个数组,这样我们在学习spark的API时候很多问题就能很好理解了.上篇文章里的API也都是基于RDD是数组的数据模型而进行操作的. Spark是一个计算框架,是对ma ...
- Spark笔记:RDD基本操作(上)
本文主要是讲解spark里RDD的基础操作.RDD是spark特有的数据模型,谈到RDD就会提到什么弹性分布式数据集,什么有向无环图,本文暂时不去展开这些高深概念,在阅读本文时候,大家可以就把RDD当 ...
- Spark核心——RDD
Spark中最核心的概念为RDD(Resilient Distributed DataSets)中文为:弹性分布式数据集,RDD为对分布式内存对象的 抽象它表示一个被分区不可变且能并行操作的数据集:R ...
- 【原】Learning Spark (Python版) 学习笔记(一)----RDD 基本概念与命令
<Learning Spark>这本书算是Spark入门的必读书了,中文版是<Spark快速大数据分析>,不过豆瓣书评很有意思的是,英文原版评分7.4,评论都说入门而已深入不足 ...
- Spark Rdd coalesce()方法和repartition()方法
在Spark的Rdd中,Rdd是分区的. 有时候需要重新设置Rdd的分区数量,比如Rdd的分区中,Rdd分区比较多,但是每个Rdd的数据量比较小,需要设置一个比较合理的分区.或者需要把Rdd的分区数量 ...
- RDD/Dataset/DataFrame互转
1.RDD -> Dataset val ds = rdd.toDS() 2.RDD -> DataFrame val df = spark.read.json(rdd) 3.Datase ...
- 深入理解Spark(一):Spark核心概念RDD
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
随机推荐
- Jmeter插件安装及使用
1 安装Plugins Manager插件 1.1 下载Plugins Manager插件 插件下载官方地址:https://jmeter-plugins.org/downloads/all/ 将下载 ...
- UVA1354-Mobile Computing(二进制枚举子集)
Problem UVA1354-Mobile Computing Accept:267 Submit:2232 Time Limit: 3000 mSec Problem Description ...
- jenkins使用1----初始化设置
####一.基本设置 1.首先找到系统管理 2.再找到全局配置一把黄色的锁头 3.新增JDK.Maven等 别名随便 下面的值添加jdk在jenkins这台机器上的位置,如果没找到可以点击自动安装,并 ...
- 摒弃FORM表单上传图片,异步批量上传照片
之前作图像处理一直在用form表单做图片数据传输, 个人感觉low到爆炸而且用户体验极差,现在介绍一个一部批量上传图片的小技巧,忘帮助他人的同时也警醒自己在代码的编写时不要只顾着方便,也要考虑代码的健 ...
- i春秋-百度杯十月场-EXEC
进入网站,查看源代码,发现是用vim编辑,而抓包没有有效信息,加参数也无果.百度查了一下vim能形成什么文件.找到答案说,用vim编辑文本xxx.php中途退出,会自动创建一个文件.xxx.php.s ...
- Python+自动化测试框架的设计编写
Python之一个简单的自动化测试框架:https://baijiahao.baidu.com/s?id=1578211870226409536&wfr=spider&for=pc h ...
- WPF效果(GIS二维篇)
距离上次发东西已经过去了貌似不知多少天了,突然发现自己懒得总结了.这毛病感觉不好,还得写点东西来充实一下自己,不然这样整天浑浑噩噩的过日子,也太平淡了,不管怎么说,起码得给自己的经历留下点东西吧.闲话 ...
- 深入理解Redis Cluster
Redis Cluster采用虚拟槽分区,所有的key根据哈希函数映射到0~16383槽内,计算公式: slot = CRC16(key) & 16383 每个节点负责维护一部分槽以及槽所映射 ...
- Item 16: 让const成员函数做到线程安全
本文翻译自modern effective C++,由于水平有限,故无法保证翻译完全正确,欢迎指出错误.谢谢! 博客已经迁移到这里啦 如果我们在数学领域里工作,我们可能会发现用一个类来表示多项式会很方 ...
- shell 小工具
1.打印进度条(待完善) #!/bin/sh printf -- 'Performing asynchronous action..'; DONE=; printf -- '............. ...