Spark集群搭建【Spark+Hadoop+Scala+Zookeeper】
一.安装Linux
需要:3台CentOS7虚拟机

注意:
虚拟机的网络设置为NAT模式,NAT模式可以在断网的情况下连接上虚拟机而桥架模式不行!
二.设置静态IP
跳转目录到:

修改IP设置:
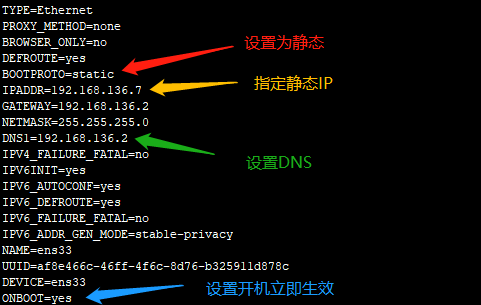
备注:执行scp命令拷贝设置文件到另外两个节点,修改IP分别为192.168.136.8和192.168.136.9
三.安装JDK
参考我的博客:https://www.cnblogs.com/yszd/p/10140327.html
四.运行Spark预编译包中的实例
1.测试Scala代码实例
执行:
运行Scala版本计算Pi的代码实例结果:
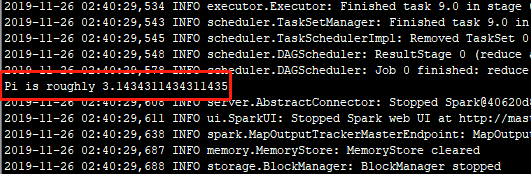
表示运行成功!
2.测试python代码实例
执行:

运行python版本计算Pi的代码实例,注意,若要是遇到下面的异常:
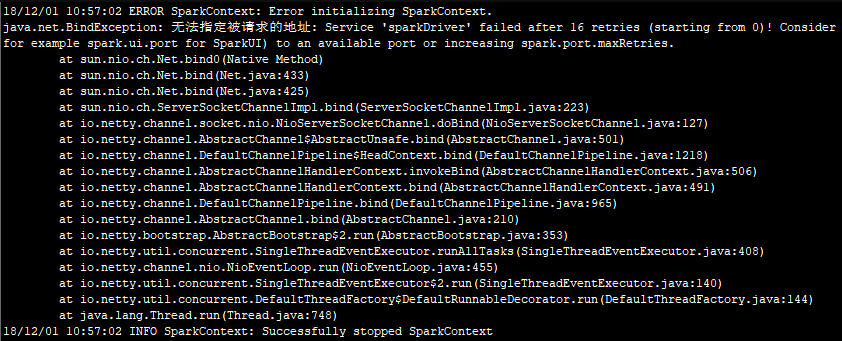
表示没有指定ip,这是需要修改配置文件spark-env.sh,前往conf目录下执行

拷贝配置模板文件,并修改为spark-env.sh,执行

打开配置文件,添加,指定默认ip。

然后继续执行计算Pi代码命令:

结果如下:
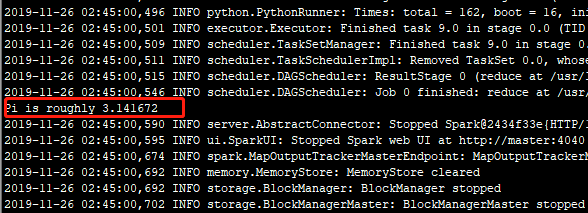
表示执行成功!
五.本地体验Spark
1.执行命令进入Spark交互模式

2.编写简单代码实例
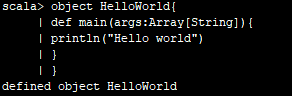
执行结果:

六.免密码登录
参考我的博客:https://www.cnblogs.com/yszd/p/10123911.html
备注:如果是使用root或高权限的账号操作的,那么authorized_keys文件本身权限就够,无需追加权限,否则可以使用chmod添加权限。另外,各个节点首次访问时需要输入密码!
七.Zookeeper集群部署
1.上传zookeeper到集群的各个节点

2.修改配置,指定datadir和集群节点配置
initLimit=
syncLimit=
dataDir=/hadoop/zookeeper
dataLogDir=/usr/local/soft/zookeeper-3.4./log
clientPort=
#maxClientCnxns=
server. = master::
server. = slave01::
server. = slave02::
3.配置myid

注意:内容为上面server.x中的x
4.启动zookeeper节点,查看节点运行状态
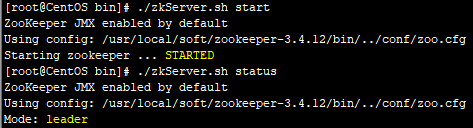

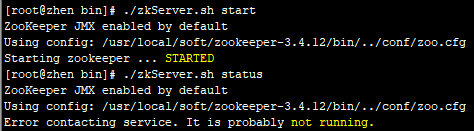
注意:节点zhen启动异常,查看zoo.cfg配置是否正确及防火墙是否已经关闭,确定无误后等待zookeeper自启!
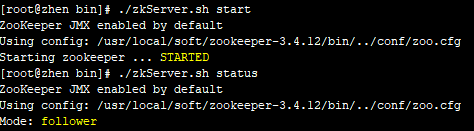
异常节点zhen启动成功,zookeeper集群搭建完成!
八.Spark Standalone集群搭建
安装scala环境
下载地址:https://www.scala-lang.org/download/2.11.12.html
下拉到最下面,选择scala-2.11.12.rpm使用rpm安装:
上传到集群:
执行命令:rpm -ivh scala-2.11.12.rpm安装scala环境,输入scala -version检测是否安装成功

表示安装成功!
配置环境变量,编辑etc/profile,添加:

九.Hadoop3.2.1完全分布式搭建
1.下载文件
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
2.上传并解压Hadoop文件

3.修改相应配置文件
3.1 etc/profile:

3.2 HADOOP_HOME/etc/hadoop/hadoop-env.sh

3.3 HADOOP_HOME/etc/hadoop/slaves,注意:在Hadoop3.1之后,slaves改为workers
3.4 HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-3.2.1/tmp</value>
</property>
</configuration>
3.5 HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/soft/hadoop-3.2.1/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/soft/hadoop-3.2.1/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
</configuration>
3.6 HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
注意:在Hadoop3.1之后,为了避免在执行任务时报一下错误:
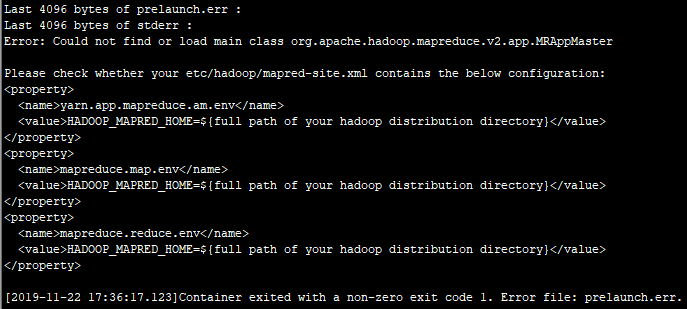
要额外添加一下配置(也就是上面报错信息提到的配置):
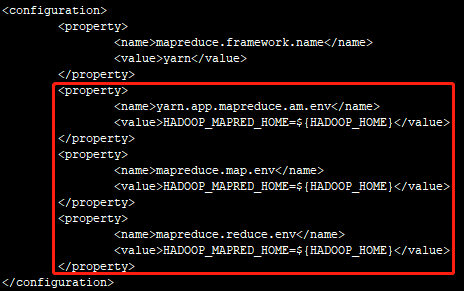
3.7 HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
3.8 格式化Hadoop
执行:hdfs namenode -format
4.拷贝Hadoop到Worker节点
执行命令:scp -r /usr/local/soft/hadoop-3.2.1 root@worker1:/usr/local/soft
执行命令:scp -r /usr/local/soft/hadoop-3.2.1 root@worker2:/usr/local/soft
5.在浏览器上输入:master:50070查看,注意:在Hadoop3.1之后,端口修改为9870
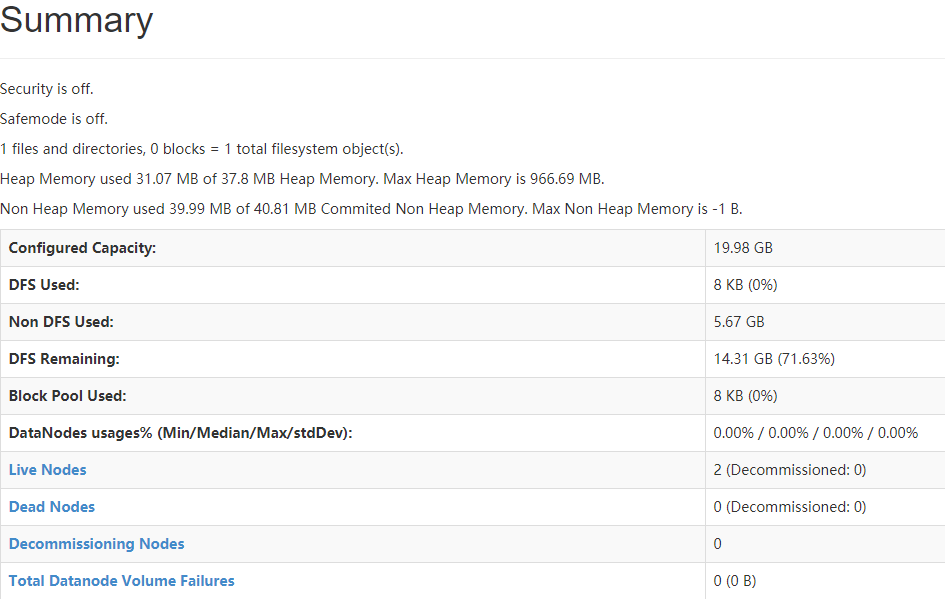
表示安装成功!
十.Spark-2.4.4完全分布式搭建
1.下载安装文件
https://www.apache.org/dyn/closer.lua/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
2.上传并解压安装文件

3.修改相应的配置文件
3.1 etc/profile

3.2 SPARK_HOME/conf/spark-env.sh
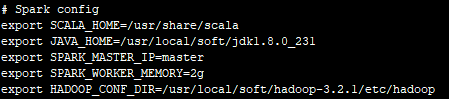
3.3 SPARK_HOME/conf/slaves
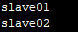
十一.编辑集群的脚本
1.启动脚本
#!/bin/bash
echo -e "=========================Start spark cluster=================================="
echo -e "Starting Hadoop..."
/usr/local/soft/hadoop-3.2.1/sbin/start-all.sh
echo -e "Starting Spark..."
/usr/local/soft/spark-2.4.4-bin-hadoop2.7/sbin/start-all.sh
echo -e "The Result of the Command \"jps\""
jps
echo -e "=================================End=========================================="
注意:如果jps没有namenode,则说明namenode元数据损坏,这时需要前往bin目录下,执行:hadoop namenode -format重建一下
2.关闭脚本
#!/bin/bash
echo -e "=========================Stop spark cluster=================================="
echo -e "Stoping Hadoop..."
/usr/local/soft/hadoop-3.2.1/sbin/stop-all.sh
echo -e "Stoping Spark..."
/usr/local/soft/spark-2.4.4-bin-hadoop2.7/sbin/stop-all.sh
echo -e "The Result of the Command \"jps\""
jps
echo -e "=================================End=========================================="
十二.测试
1.测试Hadoop
1.1 创建测试文件

1.2 编辑内容
spark scala hadoop spark hadoop java redis hbase hive kafka flume
1.3 创建Hadoop文件夹,用于保存测试文件
hadoop fs -mkdir -p /hadoop/data
1.4 把创建好的测试文件导入到Hadoop中
hadoop fs -put /wordcount.txt /hadoop/data/
1.5 运行程序
hadoop jar /usr/local/soft/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /hadoop/data /hadoop/output
1.6 执行结果

2.测试Spark
执行Spark提交命令:./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.4.4.jar 1000
部分执行日志:

执行结果:
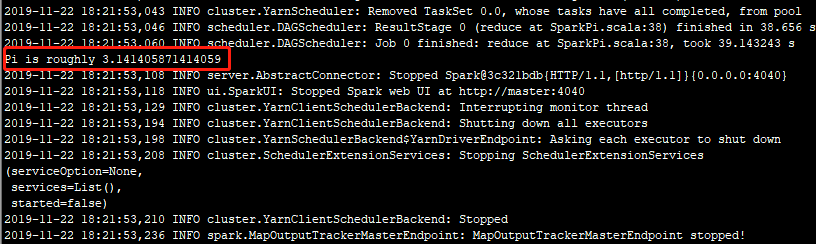
完成!!
Spark集群搭建【Spark+Hadoop+Scala+Zookeeper】的更多相关文章
- Spark集群搭建简要
Spark集群搭建 1 Spark编译 1.1 下载源代码 git clone git://github.com/apache/spark.git -b branch-1.6 1.2 修改pom文件 ...
- Spark集群搭建简配+它到底有多快?【单挑纯C/CPP/HADOOP】
最近耳闻Spark风生水起,这两天利用休息时间研究了一下,果然还是给人不少惊喜.可惜,笔者不善JAVA,只有PYTHON和SCALA接口.花了不少时间从零开始认识PYTHON和SCALA,不少时间答了 ...
- hadoop+spark集群搭建入门
忽略元数据末尾 回到原数据开始处 Hadoop+spark集群搭建 说明: 本文档主要讲述hadoop+spark的集群搭建,linux环境是centos,本文档集群搭建使用两个节点作为集群环境:一个 ...
- 十、scala、spark集群搭建
spark集群搭建: 1.上传scala-2.10.6.tgz到master 2.解压scala-2.10.6.tgz 3.配置环境变量 export SCALA_HOME=/mnt/scala-2. ...
- spark集群搭建整理之解决亿级人群标签问题
最近在做一个人群标签的项目,也就是根据客户的一些交易行为自动给客户打标签,而这些标签更有利于我们做商品推荐,目前打上标签的数据已达5亿+, 用户量大概1亿+,项目需求就是根据各种组合条件寻找标签和人群 ...
- spark集群搭建
文中的所有操作都是在之前的文章scala的安装及使用文章基础上建立的,重复操作已经简写: 配置中使用了master01.slave01.slave02.slave03: 一.虚拟机中操作(启动网卡)s ...
- Spark集群搭建(local、standalone、yarn)
Spark集群搭建 local本地模式 下载安装包解压即可使用,测试(2.2版本)./bin/spark-submit --class org.apache.spark.examples.SparkP ...
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- Spark 集群搭建
0. 说明 Spark 集群搭建 [集群规划] 服务器主机名 ip 节点配置 s101 192.168.23.101 Master s102 192.168.23.102 Worker s103 19 ...
- Spark集群搭建中的问题
参照<Spark实战高手之路>学习的,书籍电子版在51CTO网站 资料链接 Hadoop下载[链接](http://archive.apache.org/dist/hadoop/core/ ...
随机推荐
- HttpContextAccessor不会出现线程同步问题?
我有一段比较常规的.net core mvc代码,就是StartUp函数中注册HttpContextAccessor到系统DI工厂中,如图: 然后调用方是service层,这个service层是使用a ...
- 自动化测试 | UI Automator 进阶指南
UI Automator 相关介绍: 跨应用的用户界面自动化测试 包含在 AndroidX Test(https://developer.android.com/training/testing) 中 ...
- 【干货】利用MVC5+EF6搭建博客系统(四)(下)前后台布局实现、发布博客以及展示
二.博客系统后台布局实现 2.1.这里所用的是MVC的布局页来实现的,后台主要分为三部分:导航.菜单.主要内容 代码实现: 这里把后台单独放在一个区域里面,所以我这里建立一个admin的区域 在布局页 ...
- linux 命令 — sort、uniq
sort uniq sort:对行或者文本文件排序 uniq:去除重复的行 常用 sort -n file.txt 按数字进行排序 sort -r file.txt 按逆序进行排序 sort -M f ...
- 【原创】STM32工程新建步骤
1. 新建文件夹 DOC文件夹: 可以存放readme.txt等项目文档 Library文件夹: 可以存放ST库源码,直接复制ST库的源代码到Librar ...
- noteless的博客导航页 所有文章的导航页面
导航 <spring springmvc mybatis maven 项目整合示例系列-导航页> <JAVA 基础知识点拾遗系列 JAVA学习 -1层 导航页> <计 ...
- Spring基础系列-AOP源码分析
原创作品,可以转载,但是请标注出处地址:https://www.cnblogs.com/V1haoge/p/9560803.html 一.概述 Spring的两大特性:IOC和AOP. AOP是面向切 ...
- 【leet-code】135. 加油站
题目描述 在一条环路上有 N 个加油站,其中第 i 个加油站有汽油 gas[i] 升. 你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升.你从其 ...
- rsync+inotify实现全网自动化数据备份-技术流ken
rsync简介 “rsync是linux系统下的数据镜像备份工具.使用快速增量备份工具Remote Sync可以远程同步,支持本地复制,或者与其他SSH.rsync主机同步” rsync的功能和特点 ...
- 安装并使用Jupyter Notebook
Jupyter Notebook是一个交互式笔记本,支持运行 40 多种编程语言.笔者在写博客文章时,常常需要贴代码,一贴就是一大堆代码,这样不便于读者阅读,而使用Jupyter Notebook ...