NetApp存储方案及巡检命令
一、MCC概述
Clustered Metro Cluster(简称MCC)是Netapp Data Ontap提供的存储双活解决方案,当初的方案是把1个FAS/ V系列双控在数据中心之间拉远形成异地HA Pair,每站点只有单控制器节点,数据中心两站点之间通过额外的FC/VI集群适配器相连,数据中心间SAS磁盘框通过SAS转FC的FibreBridge相连。在500米以内、同一个机房采用直接光纤通道交换机连接;在500米以上(最远100km)采用光纤通道和DWDM交换机相连。
MetroCluster在此架构上也进行了演变。通过在站点A、B两个站点分别放置两套FAS/ V双控阵列,阵列A的A控和阵列B的A控,阵列A的B控和阵列B的B控分别形成集群,这样可以充分把A、B站点数据中心资源充分利用,同时对外提供存储服务;但阵列内的A、B不是集群。如果站点间形成集群Pair的任意一个控制器节点故障,故障站点的主机都需要远程访问远端控制器节点;如何站点间形成集群Pair的两个节点同时故障,就会发生业务中断。
Netapp Data Ontap8.3版本推出了4控双活解决方案,最远支持200公里距离,4控Metro Cluster方案首先由2个HA Pair组成2个本地集群,然后再从2个集群上做4节点集群。集群控制器之间内存日志通过存放在NVRAM里面,NVRAM对没有下盘的日志做了镜像,保证节点故障以后,HA Pair集群的Partner节点能够接管业务;或者站点故障以后,远端HA Pair集群能够接管业务。当日志到达一定水位或者发生系统操作刷盘时,下盘数据同步通过SyncMirror实现主从站点双写,从而确保一个站点磁盘故障以后,另外一个站点磁盘还能提供系统访问,实现站点故障切换,保证业务不中断。
MetroCluster使用两个不同地点的镜像和集群来保护数据,每个集群把数据和Storage Virtual Machine (SVM) 配置都镜像同步另一个集群。当某个站点发生灾难时,管理员可以激活远端SVM并在另一站点接管业务。此外,每个集群在本地节点均配置为HA Pair,从而提供了本地故障转移能力。
NetApp MetroCluster是以NetApp SyncMirror是配合Cluster_remote和控制器Cluster Failover的功能实现的。
Clustered Failover – 在主存储和容灾存储间提供高可用性失败恢复能力,故障接管的决策是由管理员通过单一命令行决定的。
SyncMirror – 为远端存储提供即时的数据拷贝,当故障接管时,数据可以仅通过远端的存储进行访问。
ClusterRemote – 提供管理机制用以判断灾难的发生并初始远端存储进行接管。
二、MCC巡检常用命令
1、系统健康状态检查
cluster1::> system health status show
Status
---------------
ok
2、集群状态检查
cluster1::> cluster show
Node Health Eligibility
--------------------- ------- ------------
cluster1- true true
cluster1- true true
entries were displayed.
3、集群统计状态检查
cluster1::> cluster statistics show
Counter Value Delta
---------------- ----------------- -------------
CPU Busy: % -
Operations:
Total: -
NFS: -
CIFS: -
Data Network:
Busy: % -
Received: .78GB -
Sent: .7GB -
Cluster Network:
Busy: % -
Received: 967KB -
Sent: 979KB -
Storage Disk:
Read: .38PB -
Write: .26PB -
4、查看RAID组信息
cluster1::> aggr show Aggregate Size Available Used% State #Vols Nodes RAID Status
--------- -------- --------- ----- ------- ------ ---------------- ------------
aggr0_A1 .8GB .3GB % online cluster1- raid4,
mirrored,
normal
aggr0_A2 .8GB .3GB % online cluster1- raid4,
mirrored,
normal
aggr_data_A1
.93TB .04TB % online cluster1- mixed_raid_
type,
mirrored,
hybrid,
normal
aggr_data_A2
.93TB .77TB % online cluster1- mixed_raid_
type,
mirrored,
hybrid,
normal
entries were displayed.
5、查看节点信息
cluster1::> node show
Node Health Eligibility Uptime Model Owner Location
--------- ------ ----------- ------------- ----------- -------- ---------------
cluster1-
true true
days : FAS8040 gz_idc
cluster1-
true true
days : FAS8040 gz_idc
entries were displayed.
6、查看版本信息
cluster1::> version
NetApp Release 8.3.2P9: Fri Jan :: UTC
7、查看序列号
cluster1::> system license show Serial Number: --
Owner: cluster1
Package Type Description Expiration
----------------- ------- --------------------- --------------------
Base license Cluster Base License - Serial Number: --******
Package Type Description Expiration
----------------- ------- --------------------- --------------------
NFS license NFS License -
iSCSI license iSCSI License - Serial Number: --******
Owner: cluster1-
Package Type Description Expiration
----------------- ------- --------------------- --------------------
NFS license NFS License -
iSCSI license iSCSI License -
entries were displayed.
8、查看子系统健康状态
cluster1::> system health subsystem show
Subsystem Health
----------------- ------------------
SAS-connect ok
Environment ok
Memory ok
Service-Processor ok
Switch-Health ok
CIFS-NDO ok
Motherboard ok
IO ok
MetroCluster ok
MetroCluster_Node ok
FHM-Switch ok
FHM-Bridge ok
entries were displayed.
9、查看MCC集群信息状态及节点信息状态
cluster1::> metrocluster show Configuration: fabric Cluster Configuration State Mode
------------------------------ ---------------------- ------------------------
Local: cluster1 configured normal
Remote: cluster1_dr configured normal cluster1::> metrocluster node show
DR Configuration DR
Group Cluster Node State Mirroring Mode
----- ------- ------------------ -------------- --------- --------------------
cluster1
cluster1- configured enabled normal
cluster1- configured enabled normal
cluster1_dr
cluster1_dr- configured enabled normal
cluster1_dr- configured enabled normal
entries were displayed.
10、查看控制器状态
cluster1::> system controller show
Controller Name System ID Serial Number Model Status
------------------------- ------------- ----------------- -------- -----------
cluster1- ****** FAS8040 ok
cluster1- ****** FAS8040 ok
entries were displayed.
11、查看故障硬盘
cluster1::> storage disk show -broken
There are no entries matching your query.
12、查看spare硬盘
cluster1::> storage disk show -spare
Original Owner: cluster1-
Checksum Compatibility: block
Usable Physical
Disk HA Shelf Bay Chan Pool Type RPM Size Size Owner
--------------- ------------ ---- ------ ----- ------ -------- -------- --------
1.30. 3a A Pool0 SAS .09TB .09TB cluster1-
1.30. 3a A Pool0 SAS .09TB .09TB cluster1-
1.31. 3a A Pool0 SAS .09TB .09TB cluster1-
1.32. 4b B Pool0 SAS .09TB .09TB cluster1-
1.32. 3a A Pool0 SAS .09TB .09TB cluster1-
1.33. 3a A Pool0 SAS .09TB .09TB cluster1-
1.33. 3a A Pool0 SAS .09TB .09TB cluster1-
1.33. 4b B Pool0 SAS .09TB .09TB cluster1-
2.42. 3a A Pool1 SAS .09TB .09TB cluster1-
2.42. 4b B Pool1 SAS .09TB .09TB cluster1-
2.43. 4b B Pool1 SAS .09TB .09TB cluster1-
2.43. 3b A Pool1 SAS .09TB .09TB cluster1-
2.43. 4b B Pool1 SAS .09TB .09TB cluster1-
3.11. 4b B Pool0 SSD - .4GB .6GB cluster1-
4.20. 3a A Pool1 SSD - .4GB .6GB cluster1-
4.21. 3a A Pool1 SAS .09TB .09TB cluster1-
Original Owner: cluster1-
Checksum Compatibility: block
Usable Physical
Disk HA Shelf Bay Chan Pool Type RPM Size Size Owner
--------------- ------------ ---- ------ ----- ------ -------- -------- --------
2.44. 3b A Pool1 SAS .09TB .09TB cluster1-
3.12. 4a B Pool0 SSD - .4GB .6GB cluster1-
4.23. 3b A Pool1 SSD - .4GB .6GB cluster1-
5.60. 3b B Pool1 SAS .09TB .09TB cluster1-
entries were displayed.
13、查看SAS桥故障
cluster1::> storage bridge show
Is Monitor
Bridge Symbolic Name Monitored Status Vendor Model Bridge WWN
------------------------ ------------- --------- ------- ------ --------------------- ----------------
ATTO_10.0.15. BRIDGE_B_1
true ok Atto FibreBridge 6500N 2000001086627bc0
ATTO_10.0.15. BRIDGE_B_2
true ok Atto FibreBridge 6500N 2000001086630f0e
ATTO_10.0.15. BRIDGE_B_3
true ok Atto FibreBridge 6500N 2000001086630edc
ATTO_10.0.15. BRIDGE_B_4
true ok Atto FibreBridge 6500N 2000001086630ed2
ATTO_10.0.15. BRIDGE_A_1
true ok Atto FibreBridge 6500N 2000001086630eb4
ATTO_10.0.15. BRIDGE_A_2
true ok Atto FibreBridge 6500N 2000001086630efa
ATTO_10.0.15. BRIDGE_A_3
true ok Atto FibreBridge 6500N 2000001086630f18
ATTO_10.0.15. BRIDGE_A_4
true ok Atto FibreBridge 6500N 2000001086630ef0
ATTO_FibreBridge6500N_10 -
false - Atto FibreBridge6500N 200000108663e514
ATTO_FibreBridge6500N_11 -
false - Atto FibreBridge6500N 200000108663e3f2
ATTO_FibreBridge6500N_12 -
false - Atto FibreBridge6500N 200000108663e488
ATTO_FibreBridge6500N_13 -
false - Atto FibreBridge6500N 20000010866114ec
ATTO_FibreBridge6500N_14 -
false - Atto FibreBridge6500N 2000001086627bc0
ATTO_FibreBridge6500N_7 -
false - Atto FibreBridge6500N 2000001086630e96
ATTO_FibreBridge6500N_9 -
false - Atto FibreBridge6500N 200000108663e4c4
entries were displayed.
14、查看纤交换机故障
cluster1::> storage switch show
Symbolic Is Monitor
Switch Name Vendor Model Switch WWN Monitored Status
--------------------- -------- ------- ----- ---------------- --------- -------
Brocade_10.0.15.
SW_A_1
Brocade Brocade6505
100050eb1a88327f true ok
Brocade_10.0.15.
SW_A_2
Brocade Brocade6505
100050eb1a881582 true ok
Brocade_10.0.15.
SW_B_3
Brocade Brocade6505
100050eb1a882f69 true ok
Brocade_10.0.15.
SW_B_4
Brocade Brocade6505
100050eb1a881522 true ok
entries were displayed.
15、查看failover状态
cluster1::> storage failover show
Takeover
Node Partner Possible State Description
-------------- -------------- -------- -------------------------------------
cluster1- cluster1- true Connected to cluster1-
cluster1- cluster1- true Connected to cluster1-
entries were displayed.
16、查看严重告警日志及错误告警日志
cluster1::> event log show -severity critical
There are no entries matching your query. cluster1::> event log show -severity error
Time Node Severity Event
------------------- ---------------- ------------- ---------------------------
// :: cluster1- ERROR asup.post.drop: AutoSupport message (HA Group Notification from cluster1- (MANAGEMENT_LOG) INFO) for host () was not posted to NetApp. The system will drop the message.
// :: cluster1- ERROR asup.post.drop: AutoSupport message (HA Group Notification from cluster1- (PERFORMANCE DATA) INFO) for host () was not posted to NetApp. The system will drop the message.
// :: cluster1- ERROR mgmtgwd.certificate.expired: A digital certificate with Fully Qualified Domain Name (FQDN) cluster1, Serial Number 5589765F, Certificate Authority 'cluster1' and type server for Vserver cluster1 has expired.
// :: cluster1- ERROR mgmtgwd.certificate.expired: A digital certificate with Fully Qualified Domain Name (FQDN) UC_SVM2, Serial Number 55A03966, Certificate Authority 'SVM2' and type server for Vserver SVM2 has expired.
// :: cluster1- ERROR mgmtgwd.certificate.expired: A digital certificate with Fully Qualified Domain Name (FQDN) UC_SVM, Serial Number 559FFD76, Certificate Authority 'SVM' and type server for Vserver SVM has expired.
// :: cluster1- ERROR mgmtgwd.certificate.expired: A digital certificate with Fully Qualified Domain Name (FQDN) UCS_SVM_DR, Serial Number 545845C16E278, Certificate Authority 'SVM_DR' and type server for Vserver SVM_DR-mc has expired.
// :: cluster1- ERROR mgmtgwd.certificate.expired: A digital certificate with Fully Qualified Domain Name (FQDN) UCS_SVM2_DR, Serial Number 545845A7B01FA, Certificate Authority 'SVM2_DR' and type server for Vserver SVM2_DR-mc has expired.
entries were displayed.
17、查看某个聚合下的Volume状态信息
cluster1::> vol show -aggregate aggr_data_A1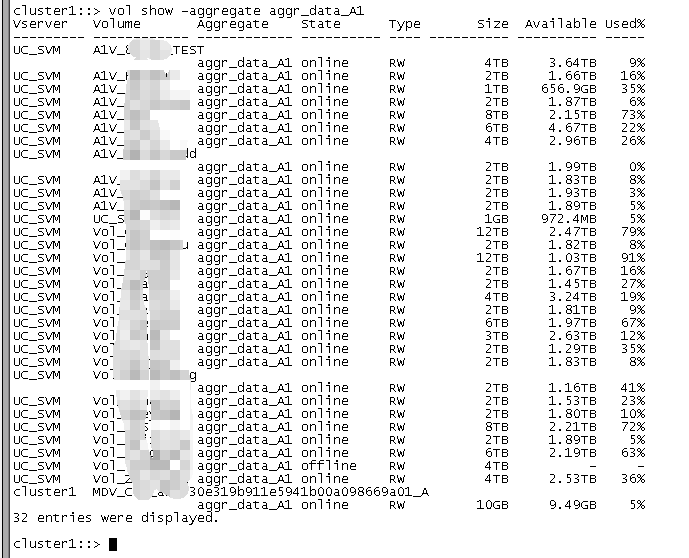
18、查看Lun信息及Lun详细信息
cluster1::> lun show
cluster1::> lun show -v
19、查看map信息及map详情
cluster1::> igroup show
cluster1::> igroup show -v
20、查看Lun的map情况
cluster1::> lun show -m
21、进入某一节点
cluster1::> run -node cluster1-
Type 'exit' or 'Ctrl-D' to return to the CLI
cluster1->
22、节点下查看spare disks
cluster1-> vol status -s Local spares Pool1 spare disks RAID Disk Device HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
--------- ------ ------------- ---- ---- ---- ----- -------------- --------------
Spare disks for block checksum
spare SW_B_3:.126L41 3a FC:A SAS / / (not zeroed)
spare SW_B_3:.126L75 3a FC:A SAS / /
spare SW_B_3:.126L101 3b FC:A SAS / /
spare SW_B_4:.126L76 4b FC:B SAS / /
spare SW_B_4:.126L29 4b FC:B SAS / /
spare SW_B_4:.126L50 4b FC:B SAS / /
spare SW_B_3:.126L22 3a FC:A SSD N/A / / Pool0 spare disks RAID Disk Device HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
--------- ------ ------------- ---- ---- ---- ----- -------------- --------------
Spare disks for block checksum
spare SW_A_1:.126L12 3a FC:A SAS / /
spare SW_A_1:.126L14 3a FC:A SAS / /
spare SW_A_1:.126L31 3a FC:A SAS / /
spare SW_A_1:.126L76 3a FC:A SAS / /
spare SW_A_1:.126L79 3a FC:A SAS / /
spare SW_A_1:.126L80 3a FC:A SAS / /
spare SW_A_2:.126L73 4b FC:B SAS / /
spare SW_A_2:.126L37 4b FC:B SAS / /
spare SW_A_2:.126L74 4b FC:B SSD N/A / /
23、节点下查看fail disk
cluster1-> vol status -f Broken disks (empty)
24、显示没有ownership(归属权)的硬盘
cluster1-> disk show -n disk show : No unassigned disks
25、分配硬盘的归属(硬盘更换常用)
cluster1-> disk assign all
26、查看所有硬盘位置信息
cluster1-> storage show disk -p
NetApp存储方案及巡检命令的更多相关文章
- MongoDb gridfs-ngnix文件存储方案
在各类系统应用服务端开发中,我们经常会遇到文件存储的问题. 常见的磁盘文件系统,DBMS传统文件流存储.今天我们看一下基于NoSQL数据库MongoDb的存储方案.笔者环境 以CentOS ...
- MongoDb gridfs-ngnix文件存储方案 - 图片
http://www.cnblogs.com/wintersun/p/4622205.html 在各类系统应用服务端开发中,我们经常会遇到文件存储的问题. 常见的磁盘文件系统,DBMS传统文件流存储. ...
- Android Learning:数据存储方案归纳与总结
前言 最近在学习<第一行android代码>和<疯狂android讲义>,我的感触是Android应用的本质其实就是数据的处理,包括数据的接收,存储,处理以及显示,我想针对这几 ...
- mongoDB 大文件存储方案, JS 支持展示
文件存储 方式分类 传统方式 存储路径 仅存储文件路径, 本质为 字符串 优点: 节省空间 缺点: 不真实存储在数据库, 文件或者数据库发送变动需要修改数据库 存储文件本身 将文件转换成 二进制 存储 ...
- Hadoop小文件存储方案
原文地址:https://www.cnblogs.com/ballwql/p/8944025.html HDFS总体架构 在介绍文件存储方案之前,我觉得有必要先介绍下关于HDFS存储架构方面的一些知识 ...
- NetApp 存储的常用概念普及
NetApp 存储的常用概念和命令1. Volume 和qtree卷(volume)是filer 上的一个基本空间单位,它可以是基于aggr划出的灵活卷(flexvol),也可以是直接由物理盘组成的传 ...
- Github 29K Star的开源对象存储方案——Minio入门宝典
对象存储不是什么新技术了,但是从来都没有被替代掉.为什么?在这个大数据发展迅速地时代,数据已经不单单是简单的文本数据了,每天有大量的图片,视频数据产生,在短视频火爆的今天,这个数量还在增加.有数据表明 ...
- Redis百亿级Key存储方案(转)
1 需求背景 该应用场景为DMP缓存存储需求,DMP需要管理非常多的第三方id数据,其中包括各媒体cookie与自身cookie(以下统称supperid)的mapping关系,还包括了supperi ...
- HTML5的五种客户端离线存储方案
最近折腾HTML5游戏需要离线存储功能,便把目前可用的几种HTML5存储方式研究了下,基于HT for Web写了个综合的实例,分别利用了Cookie.WebStorage.IndexedDB以及Fi ...
随机推荐
- [Codeforces-911B] - Two Cakes
B. Two Cakestime limit per test 1 secondmemory limit per test 256 megabytesinput standard inputoutpu ...
- 工作小应用:EXCEL查找两列重复数据
工作案例:excel存在A列.B列,需要找出B列没有A列的数据,具体做法如下(以office2007做案例): 1.点击 公式-定义名称 ,选中A列,填写名称“AAA”,选中B列,填写名称“BBB”: ...
- pkill命令详解
基础命令学习目录首页 原文链接:http://www.mamicode.com/info-detail-2315063.html 一:含义: 是ps命令和kill命令的结合,按照进程名来杀死指定进程, ...
- 互评Beta版本——Thunder组爱阅app(探路者团队测评)
基于NABCD评论作品,及改进建议 每个小组评论其他小组beta发布的作品. 1.根据(不限于)NABCD评论作品的选题; N(Need,需求):在Beta中加入了书友QQ群,以及反馈建议,更好的 ...
- Task 6.2冲刺会议八 /2015-5-21
今天把主界面大体完成了,摄像头的拼接和语音以及麦克风的功能都已经基本上实现了.但是登录界面到主界面的跳转还是没有成功.过程中遇到的问题有登录协议的地方没有明确,一直出现跳转连接异常.明天准备把跳转的部 ...
- WebGL学习笔记四点二
前几章对图形图形内部多是 以纯色填充,但是现实中已经有许多好的图片了我们没必要一点点画,这一章第五章就是将图片以纹理的形式加载到片元中,主要过程如下,首先是定义点的坐标的attribute变量用于在j ...
- struts2返回List json
利用struts2-json-plugin 之前一直输出null.... 按网上的配也不行 后来不知道怎么突然可以了 赶紧记录一下 private List<Shop> moneyshop ...
- 重学 以太网的mac协议的CSMA/CD
之前上课一直模糊的CSMA/CD进行系统性整理. CSMA/CD (Carrier Sense Multiple Acess/Collision Detect)应用在OSI的 数据链路层 在以太网中, ...
- Scala入门系列(六):面向对象之object
object object相当于class的单个实例,类似于Java中的static,通常在里面放一些静态的field和method. 第一次调用object中的方法时,会执行object的con ...
- PROFIBUS-DP现场总线的结构及应用
PROFIBUS的最大优点在于具有稳定的国际标准EN50170作保证,并经实际应用验证具有普遍性.目前已广泛应用于制造业自动化.流程工业自动化和楼宇.交通电力等领域. PROFIBUS由3个兼容部分组 ...