python学习笔记——爬虫的抓取策略
1 深度优先算法
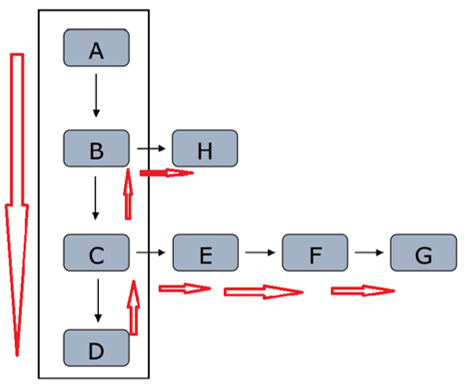
2 广度/宽度优先策略
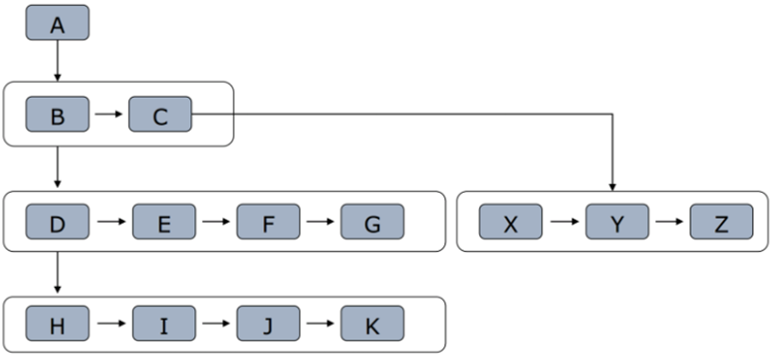
3 完全二叉树遍历结果
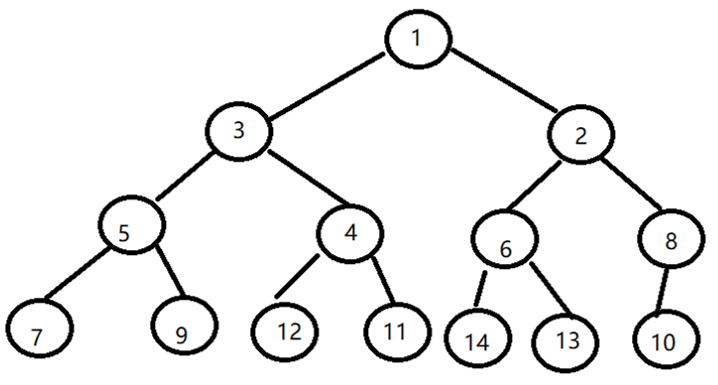
深度优先遍历的结果:[1, 3, 5, 7, 9, 4, 12, 11, 2, 6, 14, 13, 8, 10]
广度优先遍历的结果:[1, 3, 2, 5, 4, 6, 8, 7, 9, 12, 11, 14, 13, 10]
4 实践中怎么来组合爬取策略
(1)一般来说,重要的网页距离入口站点的距离很近;
(2)广度/宽度优先有利于多爬虫并行进行合作;
(3)可以考虑将深度与广度/宽度相结合的方式来实现抓取的策略:优先考虑广度优先,对深度进行限制最大深度。
5 一个通用爬虫的流程如下
(1)设置种子站点、宽度及深度
(2)一个已下载的队列来记录所有已经完成下载的url
(3)实现一个函数,取得当前url的内容以及所有的外链接
(4)递归调用这个函数,来遍历网站
(5)错误日志处理
python学习笔记——爬虫的抓取策略的更多相关文章
- python学习之爬虫(一) ——————爬取网易云歌词
接触python也有一段时间了,一提到python,可能大部分pythoner都会想到爬虫,没错,今天我们的话题就是爬虫!作为一个小学生,关于爬虫其实本人也只是略懂,怀着"Done is b ...
- Wireshark学习笔记——怎样高速抓取HTTP数据包
0.前言 在火狐浏览器和谷歌浏览器中能够很方便的调试network(抓取HTTP数据包),可是在360系列浏览器(兼容模式或IE标准模式)中抓取HTTP数据包就不那么那么方便了.尽管也可使用H ...
- [Python学习笔记]爬虫
要使用Python 抓取网页,首先我们要学习下面四个模块: 包 作用 webbrowser 打开浏览器获取指定页面: requests 从因特网下载文件和网页: Beautiful Soup 解析HT ...
- python学习笔记——爬虫中提取网页中的信息
1 数据类型 网页中的数据类型可分为结构化数据.半结构化数据.非结构化数据三种 1.1 结构化数据 常见的是MySQL,表现为二维形式的数据 1.2 半结构化数据 是结构化数据的一种形式,并不符合关系 ...
- python学习笔记——爬虫学习中的重要库urllib
1 urllib概述 1.1 urllib库中的模块类型 urllib是python内置的http请求库 其提供了如下功能: (1)error 异常处理模块 (2)parse url解析模块 (3)r ...
- Python学习笔记——与爬虫相关的网络知识
1 关于URL URL(Uniform / Universal Resource Locator):统一资源定位符,用于完整地描述Internet上网页和其他资源的地址的一种标识方法 URL是爬虫的入 ...
- Hibernate学习笔记(八) — 懒载入与抓取策略
懒载入(Load On Demand)是一种独特而又强大的数据获取方法,它可以在用户滚动页面的时候自己主动获取很多其它的数据,而新得到的数据不会影响原有数据的显示,同一时候最大程度上降低server端 ...
- python爬虫数据抓取方法汇总
概要:利用python进行web数据抓取方法和实现. 1.python进行网页数据抓取有两种方式:一种是直接依据url链接来拼接使用get方法得到内容,一种是构建post请求改变对应参数来获得web返 ...
- 爬虫学习一系列:urllib2抓取网页内容
爬虫学习一系列:urllib2抓取网页内容 所谓网页抓取,就是把URL地址中指定的网络资源从网络中读取出来,保存到本地.我们平时在浏览器中通过网址浏览网页,只不过我们看到的是解析过的页面效果,而通过程 ...
随机推荐
- XSS第四节,XSS攻击实例(一)
在开始实例的讲解之前,先看一下XSS的危害情况,第一张图中说明和XSS相关的CVE漏洞有7417个(http://web.nvd.nist.gov/view/vuln/search-results?q ...
- java之 22天 GUI 图形界面编程(一)
转自:http://takeme.iteye.com/blog/1876850 GUI(图形用户界面) import java.awt.Button; import java.awt.FlowLayo ...
- 全局安装 Vue cli3 和 继续使用 Vue-cli2.x
官方链接:https://cli.vuejs.org/zh/guide/installation.html 1.安装Vue cli3 关于旧版本 Vue CLI 的包名称由 vue-cli 改成了 @ ...
- 【Cocos2d-X开发学习笔记】第12期:动作类CCAction的详细讲解
一般对于游戏中的精灵而言,它们不仅仅是存在于场景中,而且是动态展现的,例如,精灵移动的动态效果.动 画效果.跳动效果.闪烁和旋转动态效果等.每一种效果都可以看成是精灵的一个动作. 一.动作类(CCAc ...
- Callable、Future&阻塞队列&阻塞栈
Callable.Future 简单应用 在Java5之前,线程是没有返回值的,常常为了“有”返回值,破费周折,而且代码很不好写.或者干脆绕过这道坎,走别的路了.现在Java终于有可返回值的任务( ...
- Back Track 5 之 Web踩点 && 网络漏洞
Web踩点 CMS程序版本探测 Blindelephant 针对WORDPRESS程序的踩点工具,通过比较插件等一系列的指纹,判断版本. 格式: Python Blindelephant.py [参数 ...
- HDU 2825 Wireless Password【AC自动机+DP】
给m个单词,由这m个单词组成的一个新单词(两个单词可以重叠包含)长度为n,且新单词中包含的基本单词数目不少于k个.问这样的新单词共有多少个? m很小,用二进制表示新单词中包含基本单词的情况. 用m个单 ...
- 应用程序在状态栏展示时间(C#)
private DispatcherTimer _timer; private void SetTimeElaspInStatusBar() { try { _timer = new Dispatch ...
- (转)[Unity3D]UI方案及制作细节(NGUI/EZGUI/原生UI系统) 内附unused-assets清除实例
转载请留下本文原始链接,谢谢.本文会不定期更新维护,最近更新于2013.09.17. http://blog.sina.com.cn/s/blog_5b6cb9500101bplv.html ...
- 11个实用的CSS学习工具
1. 盒子模型的幻灯片 通过3D转换效果产生的互动的幻灯片.按向左或向右箭头键切换,全屏观看会有更好的效果. 2. CSS Diner 通过一个简单的小游戏让你学习CSS selector,输入正确的 ...