爬虫学习一系列:urllib2抓取网页内容
爬虫学习一系列:urllib2抓取网页内容
所谓网页抓取,就是把URL地址中指定的网络资源从网络中读取出来,保存到本地。我们平时在浏览器中通过网址浏览网页,只不过我们看到的是解析过的页面效果,而通过程序获取的则是程序源代码。我们通过使用Python中urllib2来获取网页的URL资源,最简单方法就是调用urlopen 方法。
# coding : utf-8
import urllib2
import urllib url = 'http://www.baidu.com'
res = urllib2.urlopen(url)
print res.read()
HTTP是基于请求和应答机制—客户端提出请求,服务端提供应答。
urllib2用一个Request对象来映射你提出的HTTP请求,通过调用urlopen来传入Request对象,将返回一个相关请求response对象,这个应答对象如同一个文件对象,所以我们可以在Response对象中调用read()方法来读取。
# coding : utf-8
import urllib2
import urllib url = 'http://www.baidu.com'
request = urllib2.Request(url)
res = urllib2.urlopen(request)
print res.read()
在HTTP请求时,我们还可以发送data表单数据。一般的HTML表单,data需要编码成标准形成,然后作为data参数传到Request对象。而相应的编码工作就不能用urllib2来完成了,而是我们urllib组件。
import urllib
import urllib2 url = 'http://www.someserver.com/register.cgi' values = {'name' : 'BaiYiShaoNian',
'localtion' : 'ChongQing',
'language' : 'Python',
} data = urllib.urlencode(values)
req = urllib2.Request(url,data)
response = urllib2.urlopen(req)
the_page = response.read() print the_page
但是我有一个疑问:就是这一份代码并不能运行,我还不知道传入数据表单的作用是什么,或者我们在抓cnblogs页面时,传入登录的信息,是不是我们就可以登录博客园了啊,所以在这里请教一下大牛,先感谢了。
通过正则表达式来获取网页部分信息
正则表达式,又称为正则表示法、常规表示法。正则表达式使用单个字符串来描述、匹配一系列符号某个句法规则的字符串。通俗的说,正则表达式就是在程序中定义了字符串的某种规则,然后我们在网页源代码中找出符合这种规则的所有代码语句,不符合的就淘汰不要。
关于正则表达式的很多具体用法,我后面会边学边为大家讲解的,这里先略过。
我们可以通过Python爬虫来获取以下网页中新闻标题和新闻的ID。
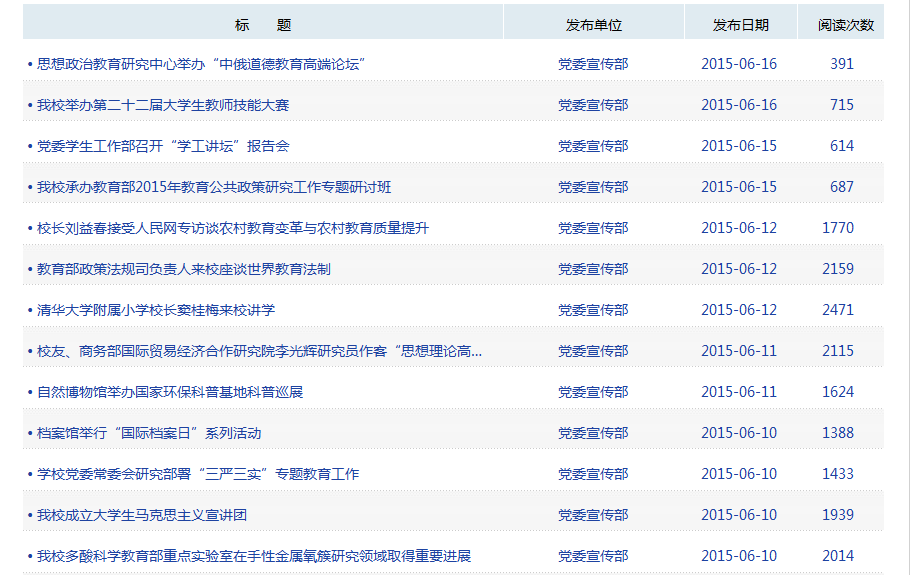
# -*- coding: utf-8 -*-
import urllib2
import re # 1.获取访问页面的HMTL
url = "http://www.nenu.edu.cn/newslist.php?cid=1" response = urllib2.urlopen(url)
html = response.read()
# 2.根据正则表达式抓取特定内容
r = re.compile(r'<a href="intramural/content/news/(?P<ID>.{5}).*" target="_blank">(?P<Title>.+)</a>')
news = r.findall(html)
for i in range(len(news)):
ID = news[i][0]
title = news[i][1]
# data = data.decode('utf-8')
# title = title.decode('utf-8')
print title + " " + ID + " "
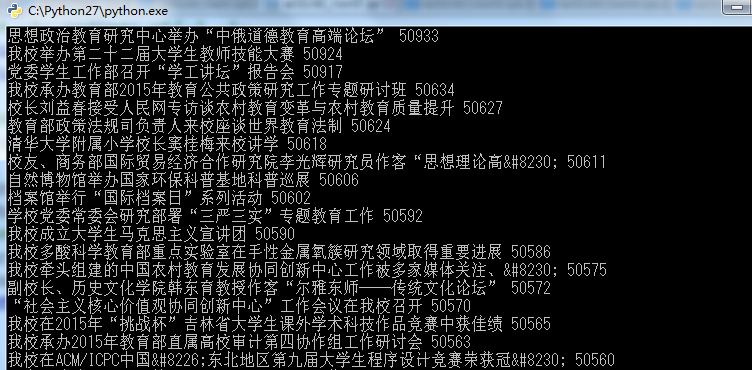
我们运行这一份代码看看结果是什么样的,是否已经成功获取。
爬虫学习一系列:urllib2抓取网页内容的更多相关文章
- python爬虫学习:分布式抓取
前面的文章都是基于在单机操作,正常情况下,一台机器无论配置多么高,线程开得再多,也总会有一个上限,或者说成本过于巨大.因此,本文将提及分布式的爬虫,让爬虫的效率提高得更快. 构建分布式爬虫首先需要有多 ...
- python3下scrapy爬虫(第二卷:初步抓取网页内容之直接抓取网页)
上一卷中介绍了安装过程,现在我们开始使用这个神奇的框架 跟很多博主一样我也先选择一个非常好爬取的网站作为最初案例,那么我先用屌丝必备网站http://www.shaimn.com/xinggan/作为 ...
- python3下scrapy爬虫(第四卷:初步抓取网页内容之抓取网页里的指定数据延展方法)
上卷中我运用创建HtmlXPathSelector 对象进行抓取数据: 现在咱们再试一下其他的方法,先试一下我得最爱XPATH 看下结果: 直接打印出结果了 我现在就正常拼下路径 只求打印结果: 现在 ...
- python爬虫学习(1)__抓取煎蛋图片
#coding=utf-8 #python_demo 爬取煎蛋妹子图在本地文件夹 import requests import threading import time import os from ...
- 通过urllib2抓取网页内容(1)
一.urllib2发送请求 import urllib2 url = 'http://www.baidu.com' req = urllib2.Request(url) response = urll ...
- python爬虫学习(2)__抓取糗百段子,与存入mysql数据库
import pymysql import requests from bs4 import BeautifulSoup#pymysql链接数据库 conn=pymysql.connect(host= ...
- Python爬虫学习笔记之抓取猫眼的排行榜
代码: import json import requests from requests.exceptions import RequestException import re import ti ...
- python3.4学习笔记(十四) 网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例
python3.4学习笔记(十四) 网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例 新浪爱彩双色球开奖数据URL:http://zst.aicai.com/ssq/openInfo/ 最终输出结果格 ...
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库
大家好,本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表 ...
随机推荐
- Android开发基础(java)14
Java语言与其他编程语言的最大不同之处在于:java有专门的异常处理机制,实现对各类异常情况进行有效控制. 一.基本概念:异常和错误的区别与联系: (1).定义形式不同:异常为exception:错 ...
- linux 通过MD5监控指定路径文件的变动
脚本须知: 1. 运行此脚本的用户必须是root,因为在某些文件所在路径普通用户没有访问权限 2. 源文件和其md5码只要有一方内容有改动,都会导致校验失败,所以校验码的保存就至关重要防止其他人修改, ...
- mysql 增加字段
alter table 表名 add 字段 varchar(500) comment '备注' default 0 after 字段;
- json.net(Json.NET - Newtonsoft)利用动态类解析json字符串
将对象转换为字符串很简单,唯一要注意的点就是为了避免循环要在需要的字段上添加jsonignore属性.可以参照这篇博文:http://www.mamicode.com/info-detail-1456 ...
- SQLite to Asp.net Entity Framework 部署问题
最近做了一个小应用,使用SQLite做数据库.开始用DBLINQ的时候,做一个LINQ查询出现不支持的问题.后来看到Entity Framework是可以支持SQLite的,于是很快转换过来.完成开发 ...
- 【ActiveMQ】消息生产者自动注入报错:Could not autowire. No beans of 'JmsMessagingTemplate' type found
使用ActiveMQ过程中,定义消息生产者: package com.sxd.jms.producer; import org.springframework.beans.factory.annota ...
- linux代理设置
http_proxy:http协议使用代理服务器地址:https_proxy:https协议使用安全代理地址:ftp_proxy:ftp协议使用代理服务器地址:user:代理使用的用户名:passwo ...
- windows搭建json-server快速方法
JSON-Server 是一个 Node 模块,运行 Express 服务器,你可以指定一个 json 文件作为 api 的数据源. 一.下载并安装node.js 安装完后输入 node --vers ...
- maven dubbo zookeeper 项目搭建(有效)jar包非war测试
zookeeper安装以及dubbo-admin.war(管理端)配置启动,本章省略,参考其他内容 这里主要说服务提供者和消费者 项目结构: 1)服务端 DemoServer.java package ...
- AngularJS的过滤器示例
代码下载:https://files.cnblogs.com/files/xiandedanteng/angularJSFilter.rar 显示效果: 页面代码: <!DOCTYPE HTML ...