Logstash 安装配置使用
一、Windows下安装运行
官网下载,下载与elasticSearch同一个版本,zip格式。Logstash占用内存较大,我在使用的时候cpu一般都是冲到90%
1、CMD直接运行
创建一个基本的Logstash管道来测试Logstash设置。
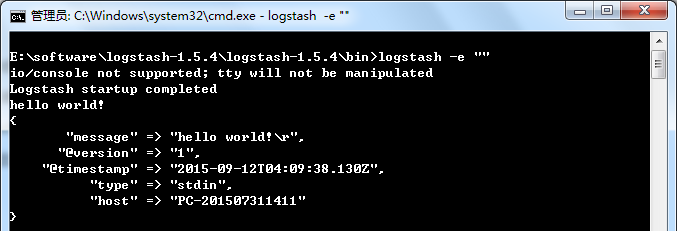
解压logstash ,并且在bin目录下运行命令(参考下面命令):加入 -e 标志可以在命令行直接指定配置文件。
logstash -e ""
或者:
logstash -e "input { stdin {} } output { stdout {} }"
注意:双引号不能改成单引号否则可能会报:ERROR: Unknown command '{'
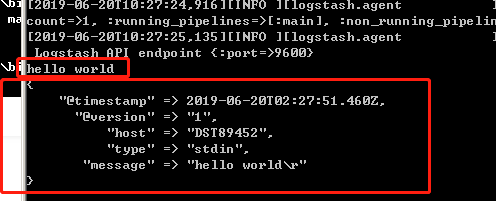
然后你会发现终端在等待你的输入。没问题,敲入 Hello World,回车,Logstash会将时间戳和IP地址信息加入输出的消息。按下ctrl+C可以从命令行退出Logstash。
2、配置文件运行,并用bat文件
进入bin目录,新建文件 logstash_default.conf 内容如下:
input {
stdin{}
}
output {
stdout{}
elasticsearch {hosts=>"127.0.0.1:9200"}
}
配置文件中定义了stdout和elasticsearch作为output,这样的“多重输出”即保证输出结果显示到屏幕上,同时也输出到elastisearch中。
在bin目录,新文件文件 run_default.bat 内容如下:
logstash -f logstash_default.conf
启动 run_default.bat 启动logstash。 等待cmd中出现:logstash api endpoint {:port=>9600 } 浏览器访问:http://localhost:9600/
在CMD中输入任何你想输入的字符串。然后看下es中是否有了数据。

3、使用NSSM将Logstash安装为Windows服务
- 下载NSSM:http://www.nssm.cc/download
将
NSSM解压,eg:E盘,进入到E:\nssm-2.24\win64 ,执行cmdnssm install logstash,【nssm install <服务名> 例如:nssm install Elasticsearch(自定义服务名)】弹出如下界面
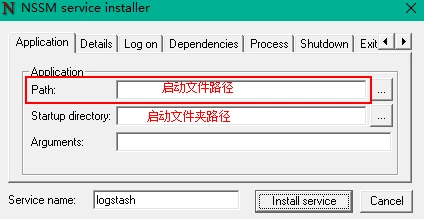
Path: 填写启动文件路径(${LOGSTASH_HOME}\bin\xxx.bat)Startup directory : 填写启动文件目录(${LOGSTASH_HOME}\bin)Detail : 填写服务名称Dependencies : 填写此服务启动需要依赖哪个服务(一般配置为要先启动elasticsearch,再启动logstash)
二、工作原理
在logstash中,包括了三个阶段:输入input --> 处理filter(不是必须的) --> 输出output
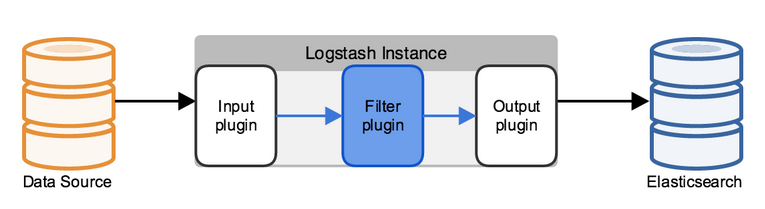
1、输入:采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
2、过滤器:实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
3、输出:选择你的存储,导出你的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
每个阶段都由很多的插件配合工作,比如file、elasticsearch、Redis等等。
每个阶段也可以指定多种方式,比如输出既可以输出到elasticsearch中,也可以指定到标准输出stdout在控制台打印。
三、命令行中常用的命令
-f:通过这个命令可以指定Logstash的配置文件,根据配置文件配置logstash
-e:后面跟着字符串,该字符串可以被当做logstash的配置(如果是“” 则默认使用stdin作为输入,stdout作为输出)
-l:日志输出的地址(默认就是stdout直接在控制台中输出)
-t:测试配置文件是否正确,然后退出。
logstash -f stdin.conf -t
四、用Logstash解析日志
在现实世界中,一个Logstash管理会稍微复杂一些:它通常有一个或多个input,filter 和 output 插件。
在这一小节中,创建一个Logstash管道,并且使用Filebeat将Apache Web日志作为input,解析这些日志,然后将解析的数据写到一个Elasticsearch集群中。你将在配置文件中定义管道,而不是在命令行中定义管道配置。
在开始之前,请先下载示例数据。
1、配置Filebeat来发送日志行到Logstash
在你创建Logstash管道之前,你需要先配置Filebeat来发送日志行到Logstash。Filebeat客户端是一个轻量级的、资源友好的工具,它从服务器上的文件中收集日志,并将这些日志转发到你的Logstash实例以进行处理。Filebeat设计就是为了可靠性和低延迟。Filebeat在主机上占用的资源很少,而且Beats input插件将对Logstash实例的资源需求降到最低。
(画外音:注意,在一个典型的用例中,Filebeat和Logstash实例是分开的,它们分别运行在不同的机器上。在本教程中,Logstash和Filebeat在同一台机器上运行。)
第1步:配置filebeat.yml
filebeat.inputs:
- type: log
paths:
- /usr/local/programs/logstash/logstash-tutorial.log output.logstash:
hosts: ["localhost:5044"]
第2步:在logstash安装目录下新建一个文件first-pipeline.conf
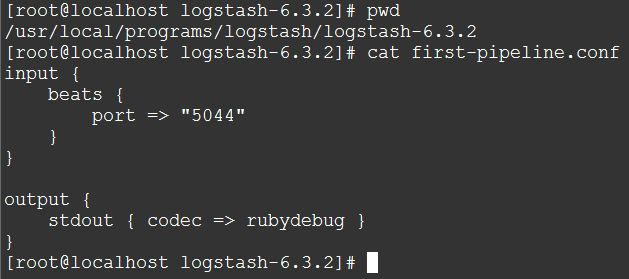
(画外音:刚才说过了通常Logstash管理有三部分(输入、过滤器、输出),这里input下面beats { port => "5044" }的意思是用Beats输入插件,而stdout { codec => rubydebug }的意思是输出到控制台)
第3步:检查配置并启动Logstash
logstash -f first-pipeline.conf --config.test_and_exit
(画外音:--config.test_and_exit选项的意思是解析配置文件并报告任何错误)
logstash -f first-pipeline.conf --config.reload.automatic
(画外音:--config.reload.automatic选项的意思是启用自动配置加载,以至于每次你修改完配置文件以后无需停止然后重启Logstash)
第4步:启动filebeat
filebeat -e -c filebeat.yml -d "publish"
如果一切正常,你将会在Logstash控制台下看到类似这样的输出:

更多参考:Logstash
Logstash 安装配置使用的更多相关文章
- logstash 安装 配置
1.Logstash 安装:在产生日志的服务器上安装 Logstash1.安装java环境 # yum install java-1.8.0-openjdk.x86_642.安装logstash(使用 ...
- 第三篇:Logstash 安装配置
Logstash 简介: Logstash 是一个实时数据收集引擎,可收集各类型数据并对其进行分析,过滤和归纳.按照自己条件分析过滤出符合数据导入到可视化界面.Logstash 建议使用java1.8 ...
- logstash安装配置
vim /usr/local/logstash/etc/hello_search.conf 输入下面: input { stdin { type => "human" }} ...
- Elasticsearch+Kibana+Logstash安装
安装环境: [root@node- src]# cat /etc/redhat-release CentOS Linux release (Core) 安装之前关闭防火墙 firewalld 和 se ...
- ELK 架构之 Logstash 和 Filebeat 安装配置
上一篇:ELK 架构之 Elasticsearch 和 Kibana 安装配置 阅读目录: 1. 环境准备 2. 安装 Logstash 3. 配置 Logstash 4. Logstash 采集的日 ...
- ELK 架构之 Elasticsearch、Kibana、Logstash 和 Filebeat 安装配置汇总(6.2.4 版本)
相关文章: ELK 架构之 Elasticsearch 和 Kibana 安装配置 ELK 架构之 Logstash 和 Filebeat 安装配置 ELK 架构之 Logstash 和 Filebe ...
- ELk(Elasticsearch, Logstash, Kibana)的安装配置
目录 ELk(Elasticsearch, Logstash, Kibana)的安装配置 1. Elasticsearch的安装-官网 2. Kibana的安装配置-官网 3. Logstash的安装 ...
- elk集成安装配置
三台虚拟机 193,194,195 本机 78 流程 pythonserver -> nginx -> logstash_shipper->kafka->logstash_in ...
- FileBeat安装配置
在ELK中因为logstash是在jvm上跑的,资源消耗比较大,对机器的要求比较高.而Filebeat是一个轻量级的logstash-forwarder,在服务器上安装后,Filebeat可以监控日志 ...
随机推荐
- ListModelSerializer模块
ListModelSerializer模块 一 .自定义反序列化字段 # 一些只参与反序列化的字段,但是不是与数据库关联的 # 在序列化类中规定,并在校验字段时从校验的参数字典中剔除 class Pu ...
- go 学习笔记(4) import
package main import ( f "fmt" ) const NAME string = "imooc" var a string = " ...
- 【1】BIO与NIO、AIO的区别
一.BIO 在JDK1.4出来之前,我们建立网络连接的时候采用BIO模式,需要先在服务端启动一个ServerSocket,然后在客户端启动Socket来对服务端进行通信,默认情况下服务端需要对每个请求 ...
- Docker学习笔记(一)—— 概述
1. Docker是个什么玩意 说Docker是什么之前,先来看一看Docker为什么会出现.我们知道,在学习过程中我们需要频繁地安装配置一些软件,不管是在Windows下还是在Linux,这些东西的 ...
- docker postgres 导出导入数据
导出 -s 选项用来只导出表结构,而不会导出表中的数据 -t 选项用来指定要导出的数据库表 格式:docker exec -ti 容器名 pg_dump -U 用户名 -s -t table_n ...
- 2.8_Database Interface ADO由来
OLE-DB,它无法广为流行,因为如下两点: 1.由于OLE-DB太底层化,使用上非常复杂,需要程序员拥有高潮的技巧. 2.OLEDB标准的API是C++API,只能供C++语言调用. 为了使得流行的 ...
- System.Data.Entity.Core.EntityException: 可能由于暂时性失败引发了异常。如果您在连接到 SQL Azure 数据库,请考虑使用 SqlAzureExecutionStrategy。
代码异常描述 ************** 异常文本 **************System.Data.Entity.Core.EntityException: 可能由于暂时性失败引发了异常.如果 ...
- 在有多个网卡,配置了多个IP的情况下,python 获取本地网卡的主IP
如图所示有多个网卡 本地网卡配置了多个IP class Public_IPOp: @staticmethod def GetLocalIP(): rt = [False] # 根节点 reg_root ...
- web项目服务器安装及配置(虚拟机centOS7)
一.安装VMware(如需) 1.首先下载VMware虚拟机,地址: https://www.vmware.com/products/workstation-pro/workstation-pro-e ...
- 【开发笔记】- Java读取properties文件的五种方式
原文地址:https://www.cnblogs.com/hafiz/p/5876243.html 一.背景 最近,在项目开发的过程中,遇到需要在properties文件中定义一些自定义的变量,以供j ...