5.4 RDD编程---综合案例
一、求top值
任务描述:求出多个文件中数值的最大、最小值



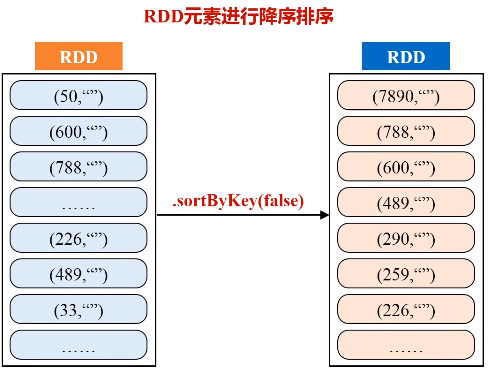
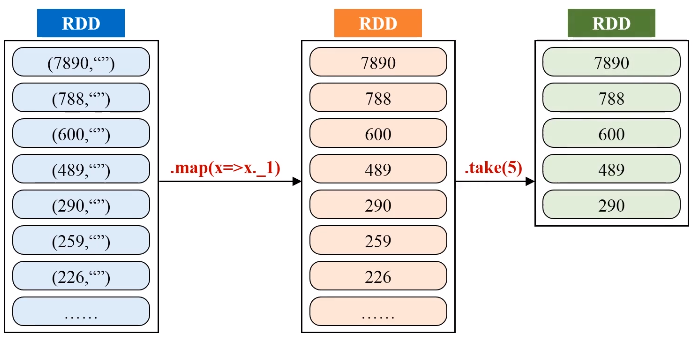

二、求最大最小值
任务描述:求出多个文件中数值的最大、最小值

解题思路:通过一个人造的key,让所有的值都成为“key”的value-list,然后对value-list进行遍历,用两个变量求出最大最小值。
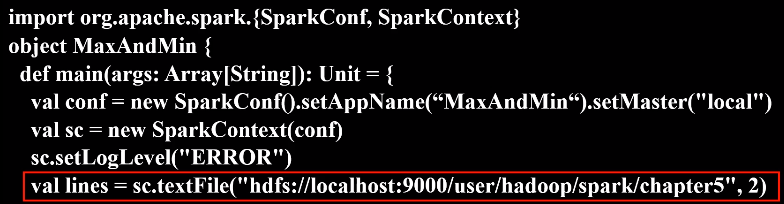


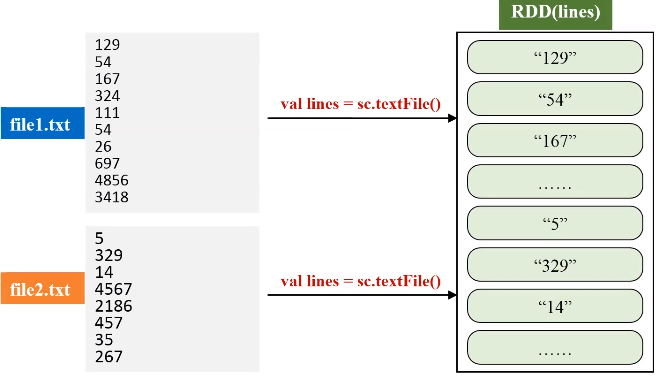
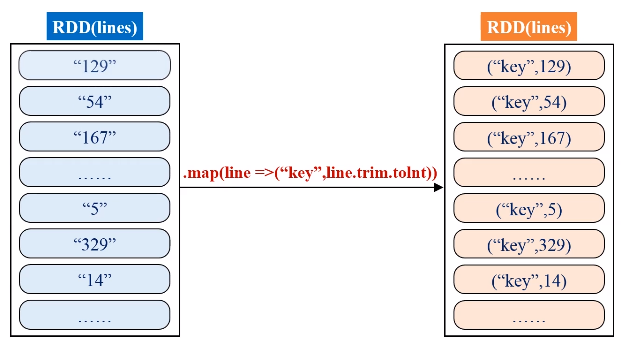
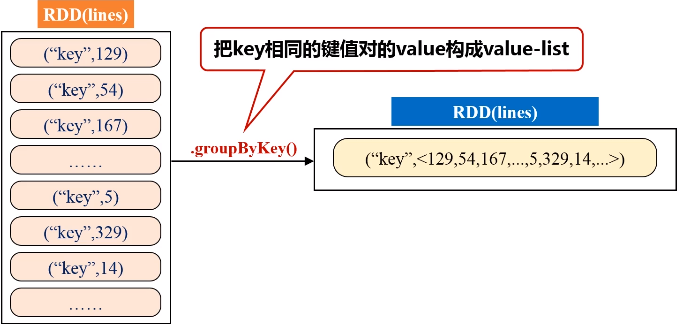
代码如下:
import org.apache.spark.{SparkConf, SparkContext}
object MaxAndMin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(“MaxAndMin“).setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/spark/chapter5", 2)
val result = lines.filter(_.trim().length>0).map(line => ("key",line.trim.toInt)).groupByKey().map(x => {
var min = Integer.MAX_VALUE
var max = Integer.MIN_VALUE
for(num <- x._2){
if(num>max){
max = num
}
if(num<min){
min = num
}
}
(max,min)
}).collect.foreach(x => {
println("max\t"+x._1)
println("min\t"+x._2)
})
}
}
三、文件排序
任务描述:有多个输入文件,每个文件中的每一行内容均为一个整数。要求读取所有文件中的整数,进行排序后,输出到一个新的文件中,输出的内容个数为每行两个整数,第一个整数为第二个整数的排序位次,第二个整数为原待排序的整数。
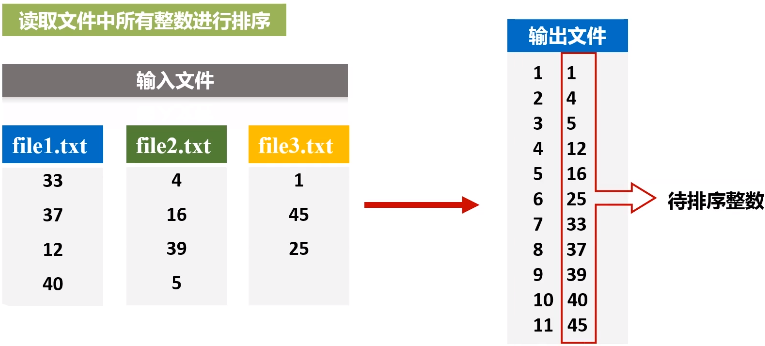
由于输入文件有多个,产生不同的分区,为了生成序号,使用HashPartitioner将中间的RDD归约到一起


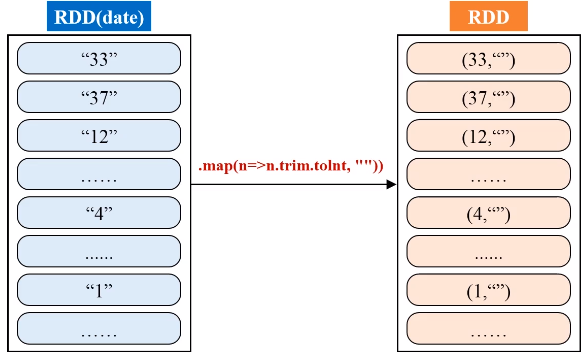
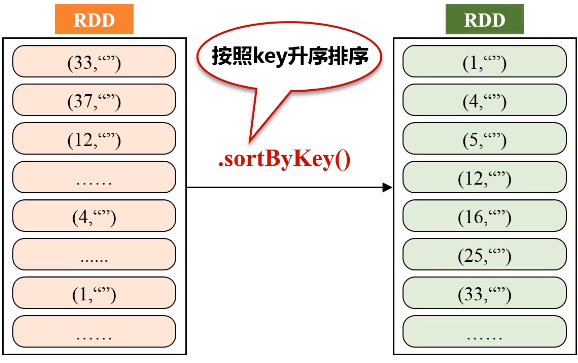


代码如下:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
object FileSort {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("FileSort")
val sc = new SparkContext(conf)
val dataFile = "file:///usr/local/spark/mycode/rdd/data"
val lines = sc.textFile(dataFile,3)
var index = 0
val result = lines.filter(_.trim().length>0).map(n=>(n.trim.toInt,"")).partitionBy(new HashPartitioner(1)).sortByKey().map(t => {
index += 1
(index,t._1)
})
result.saveAsTextFile("file:///usrl/local/spark/mycode/rdd/examples/result")
}
}
四、二次排序
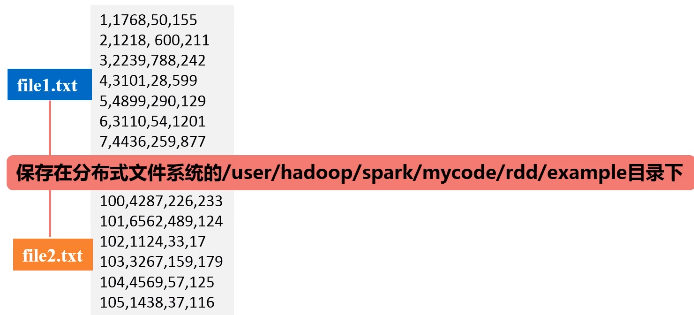
任务要求:对于一个给定的文件(数据如file1.txt所示),请对数据进行排序,首先根据第1列数据降序排序,如果第1列数据相等,则根据第2列数据降序排序。

二次排序,具体的实现步骤:
- 按照Ordered(继承排序的功能)和Serializable(继承可序列化的功能)接口实现自定义排序的key;
- 将要进行二次排序的文件加载进来生成<key,value>类型的RDD;
- 使用sortByKey基于自定义的Key进行二次排序;
- 去除掉排序的Key,只保留排序的结果
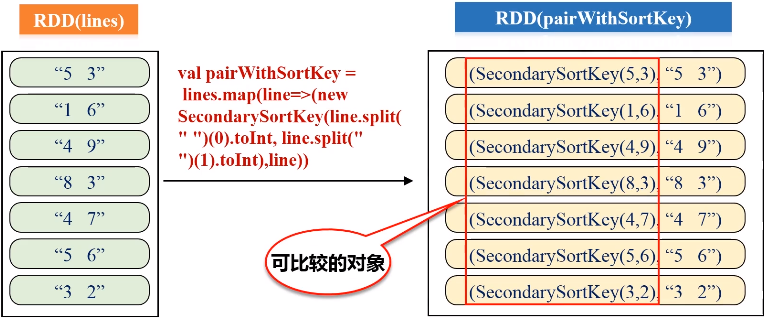
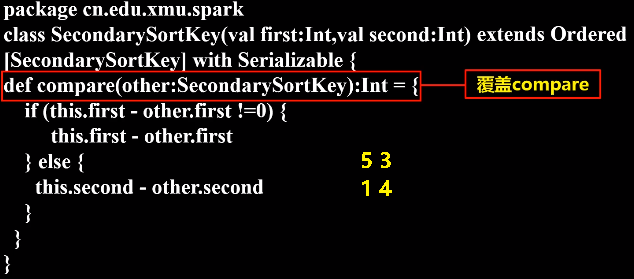
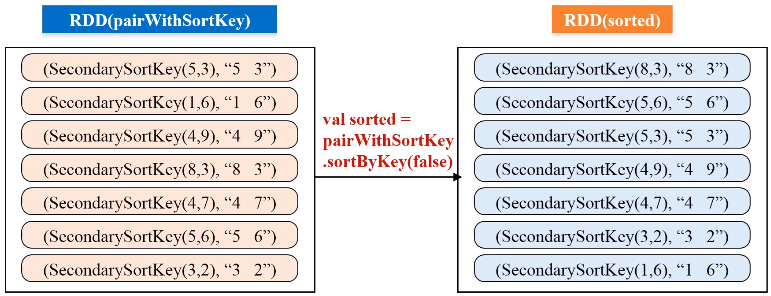
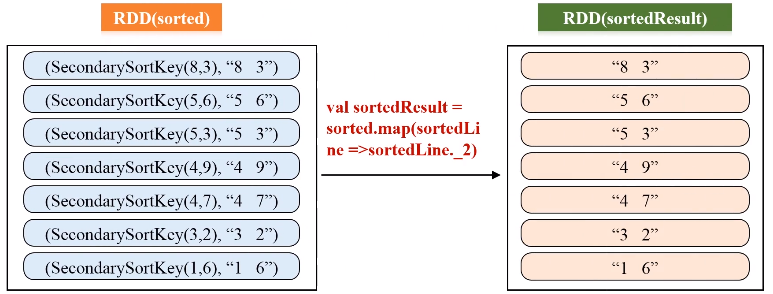
SecondarySortKey.scala代码如下:
package sparkDemo
class SecondarySortKey(val first:Int,val second:Int) extends Ordered [SecondarySortKey] with Serializable {
def compare(other:SecondarySortKey):Int = {
if (this.first - other.first !=0) {
this.first - other.first
} else {
this.second - other.second
}
}
} package cn.edu.xmu.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object SecondarySortApp {
def main(args:Array[String]){
val conf = new SparkConf().setAppName("SecondarySortApp").setMaster("local")
val sc = new SparkContext(conf)
val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/examples/file1.txt", 1)
val pairWithSortKey = lines.map(line=>(new SecondarySortKey(line.split(" ")(0).toInt, line.split(" ")(1).toInt),line))
val sorted = pairWithSortKey.sortByKey(false)
val sortedResult = sorted.map(sortedLine =>sortedLine._2)
sortedResult.collect().foreach (println)
}
}
五、连接操作
任务描述:在推荐领域有一个著名的开放测试集,下载链接,该测试集包含三个文件,分别是ratings.dat、sers.dat、movies.dat,具体介绍可阅读:README.txt。请编程实现:通过连接ratings.dat和movies.dat两个文件得到平均得分超过4.0的电影列表,采用的数据集是:ml-1m
文件1:movies.dat(MovieID::Title::Genres)

文件2:ratings.dat(UserID::MovieID::Rating::Timestamp)

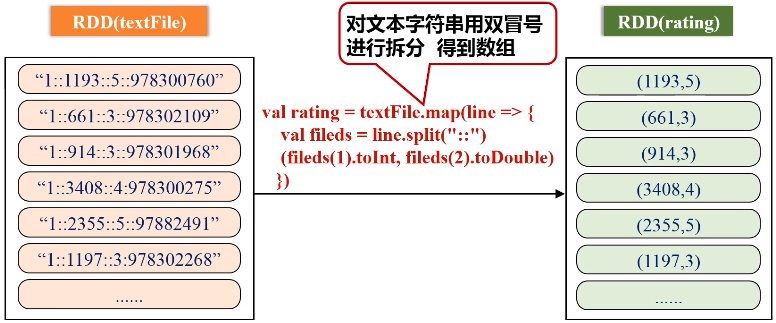
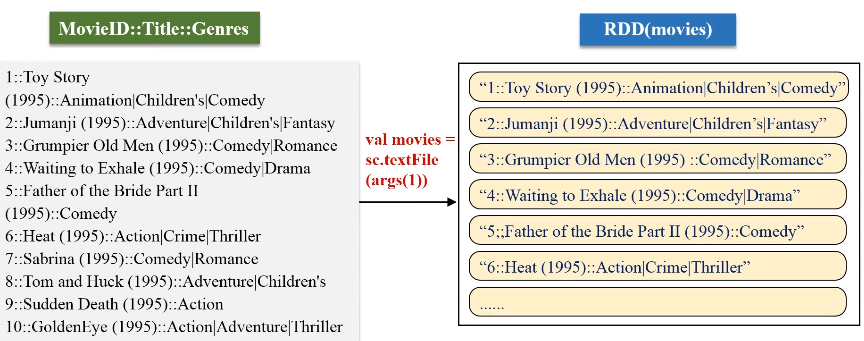
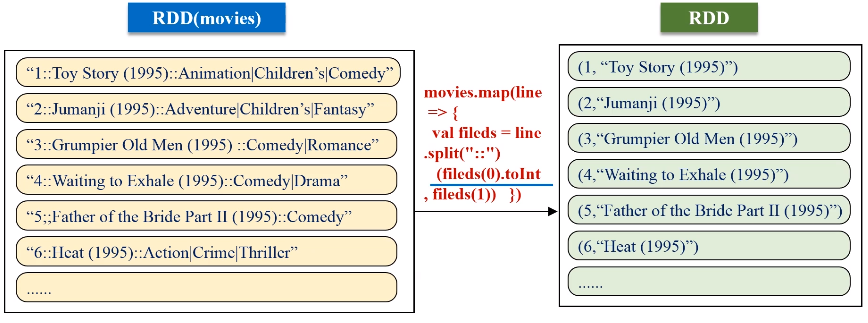
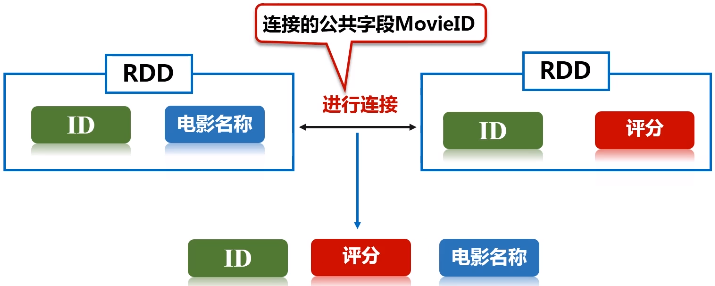
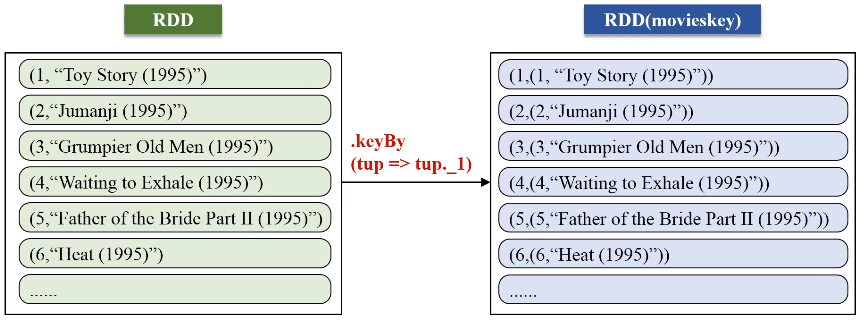

keyBy的key保持不变,value是把原来一整串的元素的值,整个作为新的RDD元素的一个value。
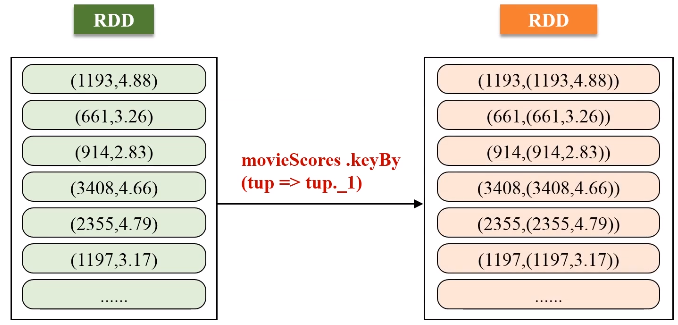

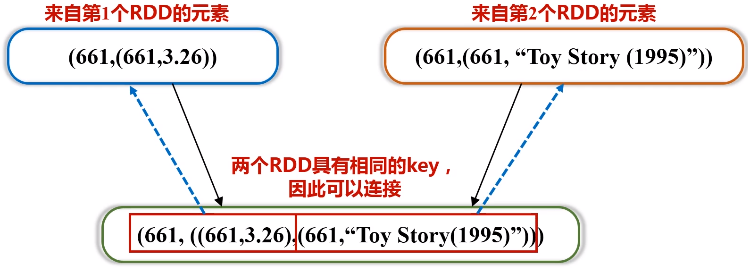
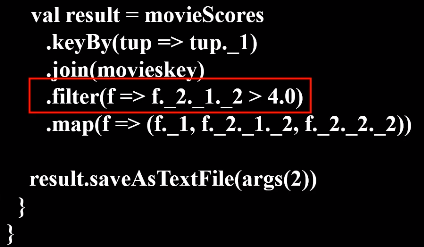
代码如下:
import org.apache.spark._
import SparkContext._
object SparkJoin {
def main(args: Array[String]) {
if (args.length != 3 ){
println("usage is WordCount <rating> <movie> <output>")
return
}
val conf = new SparkConf().setAppName("SparkJoin").setMaster("local")
val sc = new SparkContext(conf)
// Read rating from HDFS file
val textFile = sc.textFile(args(0)) //extract (movieid, rating)
val rating = textFile.map(line => {
val fileds = line.split("::")
(fileds(1).toInt, fileds(2).toDouble)
})
//get (movieid,ave_rating)
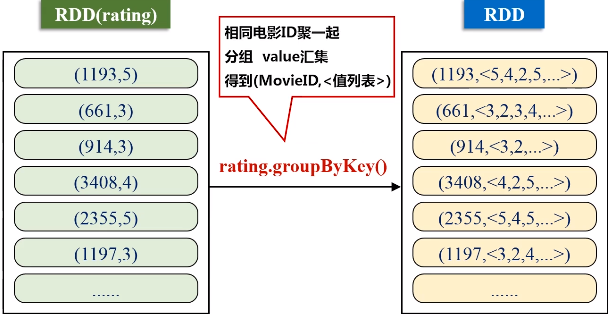
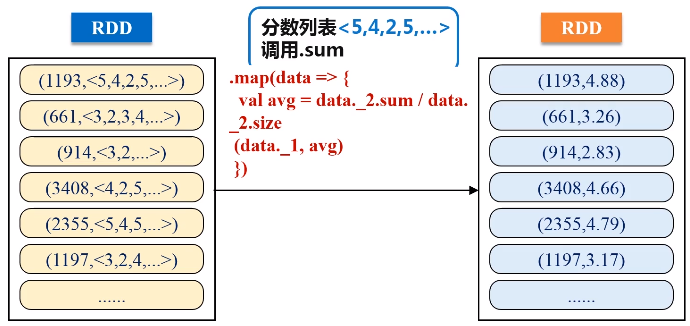
val movieScores = rating
.groupByKey()
.map(data => {
val avg = data._2.sum / data._2.size
(data._1, avg)
}) // Read movie from HDFS file
val movies = sc.textFile(args(1))
val movieskey = movies.map(line => {
val fileds = line.split("::")
(fileds(0).toInt, fileds(1)) //(MovieID,MovieName)
}).keyBy(tup => tup._1)
// by join, we get <movie, averageRating, movieName>
val result = movieScores
.keyBy(tup => tup._1)
.join(movieskey)
.filter(f => f._2._1._2 > 4.0)
.map(f => (f._1, f._2._1._2, f._2._2._2))
result.saveAsTextFile(args(2))
}
}
参考文献:
5.4 RDD编程---综合案例的更多相关文章
- Shell 编程综合案例
Shell编程综合案例 Shell也学习了大概的知识,现在这篇文章就大概讲述下如何使用shell编写一个脚本呢?下面就展示一个大家常用的数据库备份案例来进行展示. 需求分析 1)每天凌晨2:10分备份 ...
- 大数据学习day20-----spark03-----RDD编程实战案例(1 计算订单分类成交金额,2 将订单信息关联分类信息,并将这些数据存入Hbase中,3 使用Spark读取日志文件,根据Ip地址,查询地址对应的位置信息
1 RDD编程实战案例一 数据样例 字段说明: 其中cid中1代表手机,2代表家具,3代表服装 1.1 计算订单分类成交金额 需求:在给定的订单数据,根据订单的分类ID进行聚合,然后管理订单分类名称, ...
- 编程中易犯错误汇总:一个综合案例.md
# 11编程中易犯错误汇总:一个综合案例 在上一篇文章中,我们学习了如何区分好的代码与坏的代码,如何写好代码.所谓光说不练假把式,在这篇文章中,我们就做一件事——一起来写代码.首先,我会先列出问题,然 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- 02、体验Spark shell下RDD编程
02.体验Spark shell下RDD编程 1.Spark RDD介绍 RDD是Resilient Distributed Dataset,中文翻译是弹性分布式数据集.该类是Spark是核心类成员之 ...
- 40、JSON数据源综合案例实战
一.JSON数据源综合案例实战 1.概述 Spark SQL可以自动推断JSON文件的元数据,并且加载其数据,创建一个DataFrame.可以使用SQLContext.read.json()方法,针对 ...
- JQuery:JQuery基本语法,JQuery选择器,JQuery DOM,综合案例 复选框,综合案例 随机图片
知识点梳理 课堂讲义 1.JQuery快速入门 1.1.JQuery介绍 jQuery 是一个 JavaScript 库. 框架:Mybatis (jar包) 大工具 插件:PageHelper (j ...
- spring基础:什么是框架,框架优势,spring优势,耦合内聚,什么是Ioc,IOC配置,set注入,第三方资源配置,综合案例spring整合mybatis实现
知识点梳理 课堂讲义 1)Spring简介 1.1)什么是框架 源自于建筑学,隶属土木工程,后发展到软件工程领域 软件工程中框架的特点: 经过验证 具有一定功能 半成品 1.2)框架的优势 提高开发效 ...
- springAop:Aop(Xml)配置,Aop注解配置,spring_Aop综合案例,Aop底层原理分析
知识点梳理 课堂讲义 0)回顾Spring体系结构 Spring的两个核心:IoC和AOP 1)AOP简介 1.1)OOP开发思路 OOP规定程序开发以类为模型,一切围绕对象进行,OOP中完成某个任务 ...
随机推荐
- 【洛谷P1963】[NOI2009]变换序列(二分图匹配)
传送门 题意: 现有一个\(0\)到\(n-1\)的排列\(T\),定义距离\(D(x,y)=min\{|x-y|,N-|x-y|\}\). 现在给出\(D(i, T_i)\),输出字典序最小的符合条 ...
- 设计模式-单例模式(Singleton) (创建型模式)
//以下代码来源: 设计模式精解-GoF 23种设计模式解析附C++实现源码 //Singleton.h #pragma once #include<iostream> class Sin ...
- Avalon的小故事 (1)
我:这个游戏真没意思,我为什么要玩这种东西 A:你渡过了前期才能发现这个游戏的乐趣 我:那我为什么不换一个游戏玩呢?换一个开头就让人欲罢不能的游戏? B:你这是逃避!你个懦夫! 我:我连自己选择游戏的 ...
- 记一次Lua语言中死循环查错
前言 如果在Lua语言中某一处死循环了!你特么的怎么去查出这特么的该死的循环到底在特么的哪里!!! 重现步骤 一打开技能界面,整个游戏就卡死不动了 开始排查 查看一下cpu占用率,unity占用60% ...
- Kubernetes容器集群管理环境 - 完整部署(下篇)
在前一篇文章中详细介绍了Kubernetes容器集群管理环境 - 完整部署(中篇),这里继续记录下Kubernetes集群插件等部署过程: 十一.Kubernetes集群插件 插件是Kubernete ...
- 明解C语言 入门篇 第十三章答案
练习13-1 /* 打开与关闭文件 */ #include <stdio.h> int main(void) { ]; FILE* fp; printf("请输入你要打开的文件& ...
- 常见的几种 Normalization 算法
神经网络中有各种归一化算法:Batch Normalization (BN).Layer Normalization (LN).Instance Normalization (IN).Group No ...
- 图片与文本基础(html和css)
图片与文本基础 -----注释添加可以用/**/ 5.1图片 1.gif图片:最大颜色数256,保存时采用无损压缩 2.JPEG图片:可以包含1670万种颜色,保存时采用有损压缩,压缩率小的质量更高. ...
- Visual Studio 2019 (VS2019)正式版安装 VisualSVN Server 插件
VS2019 正式版最近刚刚推出来,目前 Ankhsvn 还不支持,它最高只支持 VS2017,全网搜索了一下,也没有找到.在 Stackoverflow 上看了一下,找到这篇问答: 自己按照这种方法 ...
- Redis 主从同步+哨兵
简介 通过使用 Redis 自带“主从同步+哨兵守护”功能提高Redis稳定性. 主从同步:保障数据主从数据实时同步. 哨兵:实时监控主redis如果故障,将从redis作为主使用. 环境: 系统:C ...