Spark Streaming反压机制
反压(Back Pressure)机制主要用来解决流处理系统中,处理速度比摄入速度慢的情况。是控制流处理中批次流量过载的有效手段。
1 反压机制原理
Spark Streaming中的反压机制是Spark 1.5.0推出的新特性,可以根据处理效率动态调整摄入速率。
1.1 反压定义
当批处理时间(Batch Processing Time)大于批次间隔(Batch Interval,即 BatchDuration)时,说明处理数据的速度小于数据摄入的速度,持续时间过长或源头数据暴增,容易造成数据在内存中堆积,最终导致Executor OOM或任务奔溃。
1.2 反压的数据源方式及限流处理
spark streaming的数据源方式有两种:
- 若是基于Receiver的数据源,可以通过设置spark.streaming.receiver.maxRate来控制最大输入速率;
- 若是基于Direct的数据源(如Kafka Direct Stream),则可以通过设置spark.streaming.kafka.maxRatePerPartition来控制最大输入速率。
当然,在事先经过压测,且流量高峰不会超过预期的情况下,设置这些参数一般没什么问题。但最大值,不代表是最优值,最好还能根据每个批次处理情况来动态预估下个批次最优速率。
在Spark 1.5.0以上,就可通过背压机制来实现。开启反压机制,即设置spark.streaming.backpressure.enabled为true,Spark Streaming会自动根据处理能力来调整输入速率,从而在流量高峰时仍能保证最大的吞吐和性能。
1.3 反压的实现原理
Spark Streaming的反压机制中,有以下几个重要的组件:
- RateController
- RateEstimator
- RateLimiter
主要是通过RateController组件来实现。RateController继承自接口StreamingListener,并实现了onBatchCompleted方法。每一个Batch处理完成后都会调用此方法,具体如下:
override def onBatchCompleted(batchCompleted: StreamingListenerBatchCompleted) {
val elements = batchCompleted.batchInfo.streamIdToInputInfo
for {
// 处理结束时间
processingEnd <- batchCompleted.batchInfo.processingEndTime
// 处理时间,即`processingEndTime` - `processingStartTime`
workDelay <- batchCompleted.batchInfo.processingDelay
// 在调度队列中的等待时间,即`processingStartTime` - `submissionTime`
waitDelay <- batchCompleted.batchInfo.schedulingDelay
// 当前批次处理的记录数
elems <- elements.get(streamUID).map(_.numRecords)
} computeAndPublish(processingEnd, elems, workDelay, waitDelay)
}
可以看到,接着又调用的是computeAndPublish方法,如下:
private def computeAndPublish(time: Long, elems: Long, workDelay: Long, waitDelay: Long): Unit =
Future[Unit] {
// 根据处理时间、调度时间、当前Batch记录数,预估新速率
val newRate = rateEstimator.compute(time, elems, workDelay, waitDelay)
newRate.foreach { s =>
// 设置新速率
rateLimit.set(s.toLong)
// 发布新速率
publish(getLatestRate())
}
}
更深一层,具体调用的是rateEstimator.compute方法来预估新速率,
def compute(
time: Long,
elements: Long,
processingDelay: Long,
schedulingDelay: Long): Option[Double]
RateEstimator是速率估算器,主要用来估算最大处理速率,默认的在2.2之前版本中只支持PIDRateEstimator,在以后的版本可能会支持使用其他插件,其源码如下:
def create(conf: SparkConf, batchInterval: Duration): RateEstimator =
conf.get("spark.streaming.backpressure.rateEstimator", "pid") match {
case "pid" =>
val proportional = conf.getDouble("spark.streaming.backpressure.pid.proportional", 1.0)
val integral = conf.getDouble("spark.streaming.backpressure.pid.integral", 0.2)
val derived = conf.getDouble("spark.streaming.backpressure.pid.derived", 0.0)
val minRate = conf.getDouble("spark.streaming.backpressure.pid.minRate", 100)
new PIDRateEstimator(batchInterval.milliseconds, proportional, integral, derived, minRate)
//默认的只支持pid,其他的配置抛出异常
case estimator =>
throw new IllegalArgumentException(s"Unknown rate estimator: $estimator")
}
以上这两个组件都是在Driver端用于更新最大速度的,而RateLimiter是用于接收到Driver的更新通知之后更新Executor的最大处理速率的组件。RateLimiter是一个抽象类,它并不是Spark本身实现的,而是借助了第三方Google的GuavaRateLimiter来产生的。
它实质上是一个限流器,也可以叫做令牌,如果Executor中task每秒计算的速度大于该值则阻塞,如果小于该值则通过,将流数据加入缓存中进行计算。这种机制也可以叫做令牌桶机制,图示如下: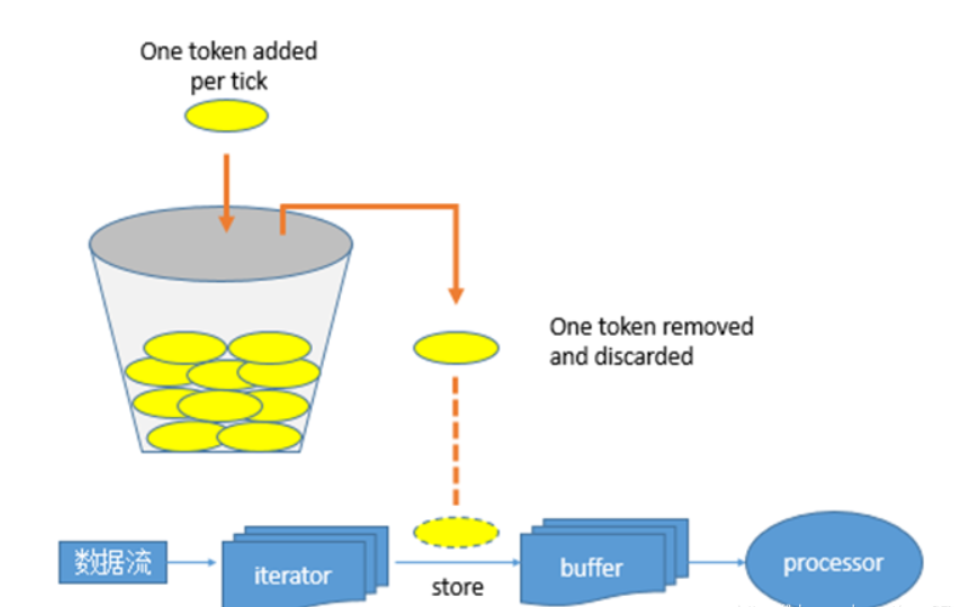
接收到的newRate进行比较,取两者中的最小值来作为最大处理速率,如果没有设置,直接设置为newRate。源码如下:
private[receiver] def updateRate(newRate: Long): Unit =
if (newRate > 0) {
if (maxRateLimit > 0) {
//如果设置了maxRateLimit则取两者中的最小值
rateLimiter.setRate(newRate.min(maxRateLimit))
} else {
rateLimiter.setRate(newRate)
}
}
spark 1.5引入的反压机制架构图如下:
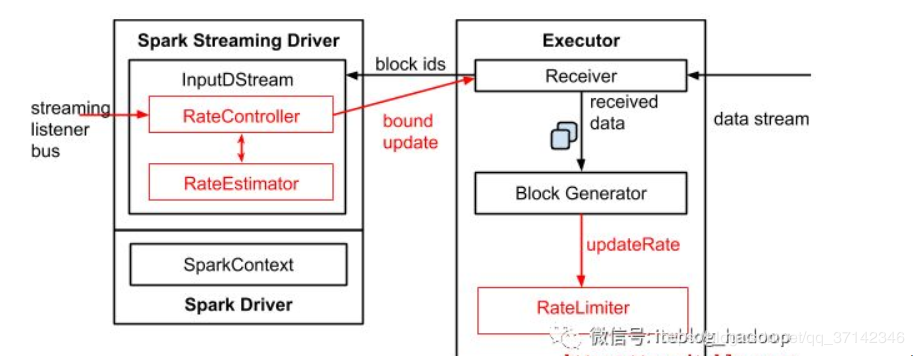
2. 反压机制相关参数
| 参数名称 | 默认值 | 说明 |
| spark.streaming.backpressure.enabled | false | 是否启用反压机制 |
| spark.streaming.backpressure.initialRate | 无 | 初始最大接收速率。只适用于Receiver Stream,不适用于Direct Stream。 |
| spark.streaming.backpressure.rateEstimator | pid | 速率控制器,Spark 默认只支持此控制器,可自定义。 |
| spark.streaming.backpressure.pid.proportional | 1.0 | 只能为非负值。当前速率与最后一批速率之间的差值对总控制信号贡献的权重。用默认值即可。 |
| spark.streaming.backpressure.pid.integral | 0.2 | 只能为非负值。比例误差累积对总控制信号贡献的权重。用默认值即可 |
| spark.streaming.backpressure.pid.derived | 0 | 只能为非负值。比例误差变化对总控制信号贡献的权重。用默认值即可 |
| spark.streaming.backpressure.pid.minRate | 100 | 只能为正数,最小速率 |
3. 反压机制的使用
//启用反压
conf.set("spark.streaming.backpressure.enabled","true")
//最小摄入条数控制
conf.set("spark.streaming.backpressure.pid.minRate","1")
//最大摄入条数控制
conf.set("spark.streaming.kafka.maxRatePerPartition","12")
注意:
- 反压机制真正起作用时需要至少处理一个批:由于反压机制需要根据当前批的速率,预估新批的速率,所以反压机制真正起作用前,应至少保证处理一个批。
- 如何保证反压机制真正起作用前应用不会崩溃:要保证反压机制真正起作用前应用不会崩溃,需要控制每个批次最大摄入速率。若为Direct Stream,如Kafka Direct Stream,则可以通过spark.streaming.kafka.maxRatePerPartition参数来控制。此参数代表了 每秒每个分区最大摄入的数据条数。假设BatchDuration为10秒,spark.streaming.kafka.maxRatePerPartition为12条,kafka topic 分区数为3个,则一个批(Batch)最大读取的数据条数为360条(3*12*10=360)。同时,需要注意,该参数也代表了整个应用生命周期中的最大速率,即使是背压调整的最大值也不会超过该参数。
4. 查看日志
创建速率控制器
INFO PIDRateEstimator: Created PIDRateEstimator with proportional = 1.0, integral = 0.2, derivative = 0.0, min rate = 1.0
计算当前批次速率
// records 记录数(对应WebUI: Input Size)
// processing time 处理时间,毫秒(对应WebUI: Processing Time)
// scheduling delay 调度时间,毫秒(对应WebUI: Scheduling Delay)
TRACE PIDRateEstimator:
time = , # records = , processing time = , scheduling delay =
预估新批次速率
TRACE PIDRateEstimator:
latestRate = -1.0, error = -2.344305035033404
latestError = -1.0, historicalError = 0.0010754440280267231
delaySinceUpdate = 1.558888897225E9, dError = -8.623482003280801E-10
第一次计算跳过速率估计
TRACE PIDRateEstimator: First run, rate estimation skipped
当前批次没有记录或没有延迟则跳过速率估计
TRACE PIDRateEstimator: Rate estimation skipped
以新的预估速率运行
TRACE PIDRateEstimator: New rate = 1.0
WebUI
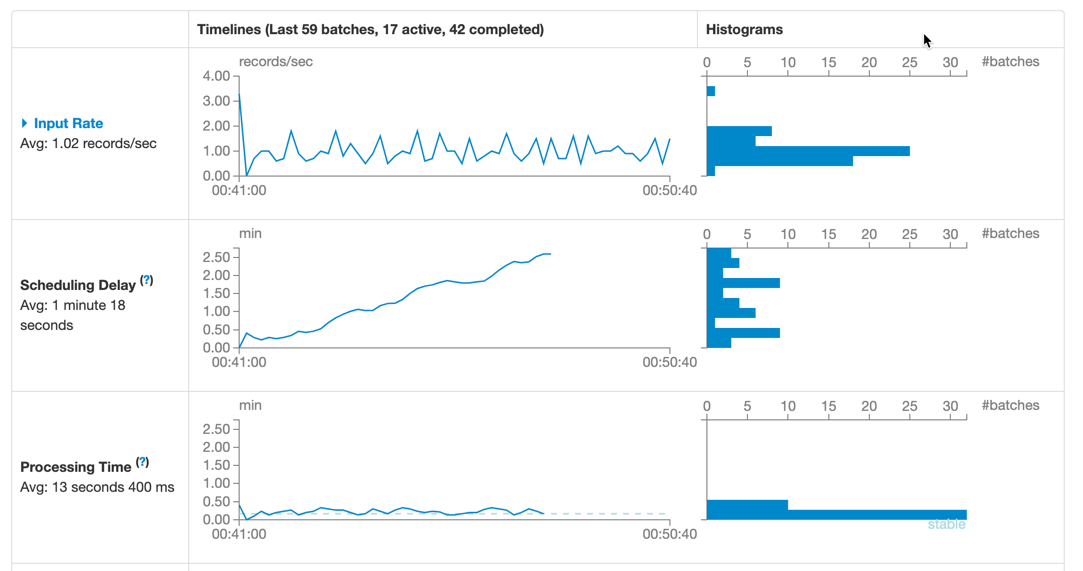
可以看到,开启反压后,摄入速率Input Rate可以根据处理时间Processing Time来调整,从而保证应用的稳定性。
Spark Streaming反压机制的更多相关文章
- SparkStreaming反压机制
一.背景 在默认情况下,Spark Streaming 通过 receivers (或者是 Direct 方式) 以生产者生产数据的速率接收数据.当 batch processing time > ...
- 一文搞懂 Flink 网络流控与反压机制
https://www.jianshu.com/p/2779e73abcb8 看完本文,你能get到以下知识 Flink 流处理为什么需要网络流控? Flink V1.5 版之前网络流控介绍 Flin ...
- [转帖]实时流处理系统反压机制(BackPressure)综述
实时流处理系统反压机制(BackPressure)综述 https://blog.csdn.net/qq_21125183/article/details/80708142 2018-06-15 19 ...
- spark storm 反压
因特殊业务场景,如大促.秒杀活动与突发热点事情等业务流量在短时间内剧增,形成巨大的流量毛刺,数据流入的速度远高于数据处理的速度,对流处理系统构成巨大的负载压力,如果不能正确处理,可能导致集群资源耗尽最 ...
- 62、Spark Streaming:容错机制以及事务语义
一. 容错机制 1.背景 要理解Spark Streaming提供的容错机制,先回忆一下Spark RDD的基础容错语义: 1.RDD,Ressilient Distributed Dataset,是 ...
- 咱们从头到尾讲一次 Flink 网络流控和反压剖析
本文根据 Apache Flink 系列直播整理而成,由 Apache Flink Contributor.OPPO 大数据平台研发负责人张俊老师分享.主要内容如下: 网络流控的概念与背景 TCP的流 ...
- Flink中接收端反压以及Credit机制 (源码分析)
先上一张图整体了解Flink中的反压 可以看到每个task都会有自己对应的IG(inputgate)对接上游发送过来的数据和RS(resultPatation)对接往下游发送数据, 整个反压机制通 ...
- Flink中发送端反压以及Credit机制(源码分析)
上一篇<Flink接收端反压机制>说到因为Flink每个Task的接收端和发送端是共享一个bufferPool的,形成了天然的反压机制,当Task接收数据的时候,接收端会根据积压的数据量以 ...
- Spark Streaming Backpressure分析
1.为什么引入Backpressure 默认情况下,Spark Streaming通过Receiver以生产者生产数据的速率接收数据,计算过程中会出现batch processing time > ...
随机推荐
- asp.net中的参数传递:Context.Handler 的用法
网上天天有人问怎么在webform页面之间传值,基本上来说,大家熟悉的是 (1)url字符串传值 (2)session传值 (3)直接读取server.transfer过来的页 ...
- dfs 全排列 使用交换——含重复元素和非重复元素
15. 全排列 中文 English 给定一个数字列表,返回其所有可能的排列. 样例 样例 1: 输入:[1] 输出: [ [1] ] 样例 2: 输入:[1,2,3] 输出: [ [1,2,3], ...
- Win10上的Docker应用:Kubernetes(容器集群)
阅读目录: Docker应用:Hello World Docker应用:Docker-compose(容器编排) Docker应用:Kubernetes(容器集群) 前言: 终于出第三篇了,上个月就已 ...
- Docker 中 MySQL 数据的导入导出
Creating database dumps Most of the normal tools will work, although their usage might be a little c ...
- LoadRunner中,File参数类型--文本参数显示问题
默认情况,File参数类型,参数数据量只能显示100(参数从0开始,99之后的不显示,但不影响正常取数据) 但是可以修改D:\Program Files (x86)\HP\LoadRunner\con ...
- [译] 2017 年比较 Angular、React、Vue 三剑客
原文地址:Angular vs. React vs. Vue: A 2017 comparison 原文作者:Jens Neuhaus 译文出自:掘金翻译计划 本文永久链接:github.com/xi ...
- Struct Socket详细分析(转)
原文地址:http://anders0913.iteye.com/blog/411986 用户使用socket系统调用编写应用程序时,通过一个数字来表示一个socket,所有的操作都在该数字上进行,这 ...
- AlexNet梳理
创新点 成功的使用relu函数替代了sigmoid函数,解决了使用sigmoid的梯度消散问题 成功的在全连接层使用dropout 成功的使用重叠最大池化 提出了LRN 利用GPU进行运算 数据增强2 ...
- vue的认识===下载
VUE:不建议直接操作DOM Vue.js是前端三大新框架:Angular.js.React.js.Vue.js之一,Vue.js目前的使用和关注程度在三大框架中稍微 胜出,并且它的热度还在递增 Vu ...
- 使用Windows事件查看器调试崩溃
本文讨论如何使用Windows事件查看器获取实际崩溃的模块以及代码中崩溃的位置.示例代码是用C++编写的,以生成不同类型的崩溃,例如访问冲突和堆栈溢出. 简介 我经常听同事和QA那里听说,一个特定的崩 ...