python爬取数据分析
一.python爬虫使用的模块
1.import requests
2.from bs4 import BeautifulSoup
3.pandas 数据分析高级接口模块
二. 爬取数据在第一个请求中时, 使用BeautifulSoup
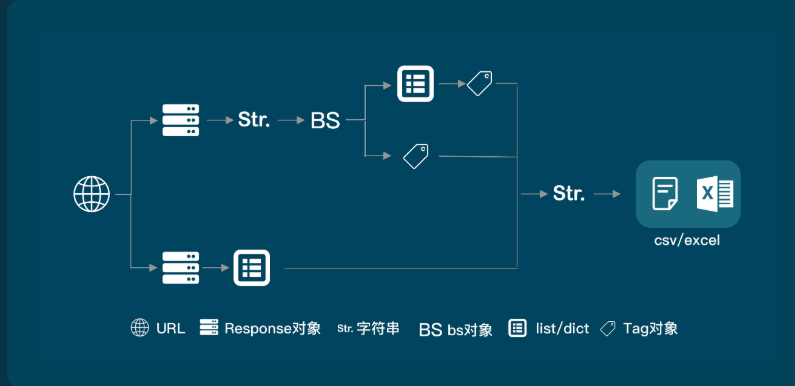
import requests
# 引用requests库
from bs4 import BeautifulSoup
# 引用BeautifulSoup库
res_movies = requests.get('https://movie.douban.com/chart')
# 获取数据
bs_movies = BeautifulSoup(res_movies.text,'html.parser')
# 解析数据
list_movies= bs_movies.find_all('div',class_='pl2')
# 查找最小父级标签
list_all = []
# 创建一个空列表,用于存储信息
for movie in list_movies:
tag_a = movie.find('a')
# 提取第0个父级标签中的<a>标签
name = tag_a.text.replace(' ', '').replace('\n', '')
# 电影名,使用replace方法去掉多余的空格及换行符
url = tag_a['href']
# 电影详情页的链接
tag_p = movie.find('p', class_='pl')
# 提取父级标签中的<p>标签
information = tag_p.text.replace(' ', '').replace('\n', '')
# 电影基本信息,使用replace方法去掉多余的空格及换行符
tag_div = movie.find('div', class_='star clearfix')
# 提取父级标签中的<div>标签
rating = tag_div.text.replace(' ', '').replace('\n', '')
# 电影评分信息,使用replace方法去掉多余的空格及换行符
list_all.append([name,url,information,rating])
# 将电影名、URL、电影基本信息和电影评分信息,封装为列表,用append方法添加进list_all
print(list_all)
# 打印
三.当数据不在第一个请求中时, 使用network获取数据
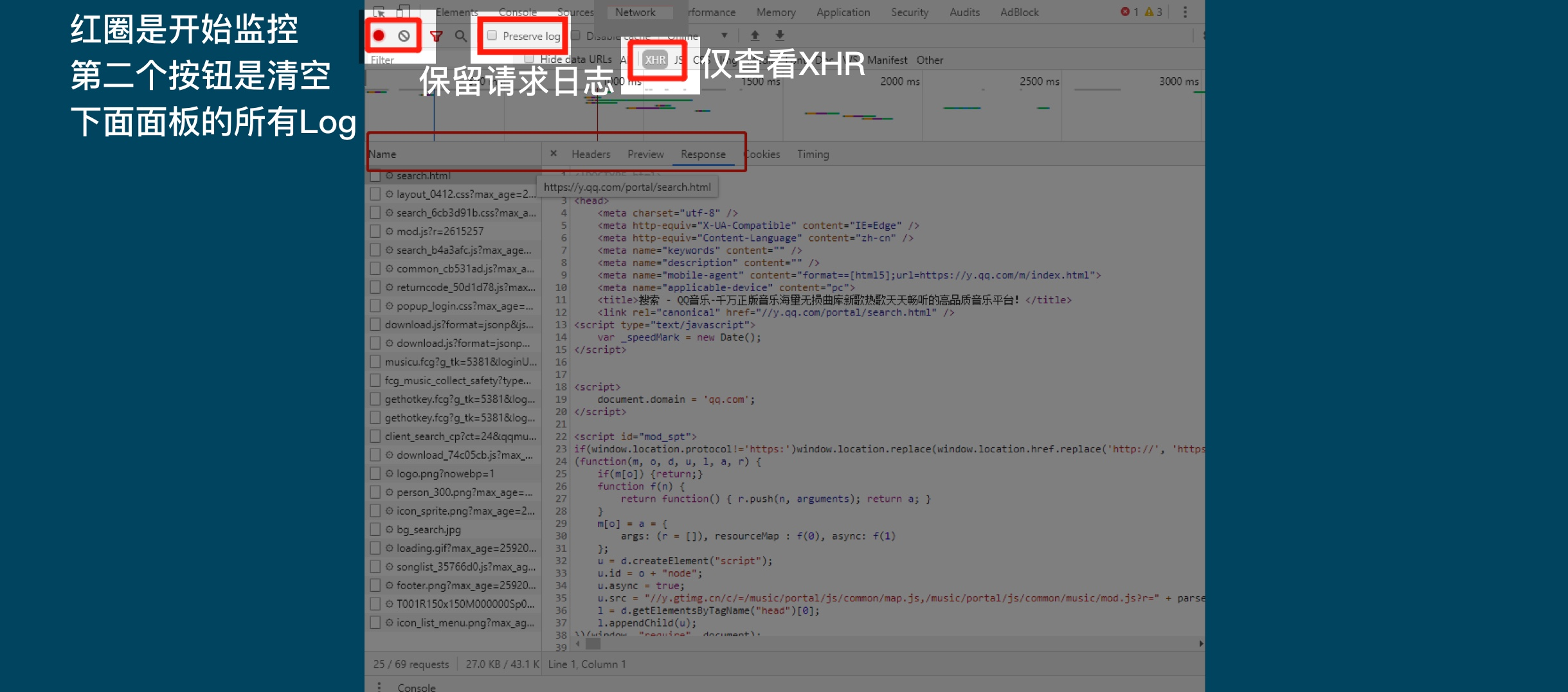

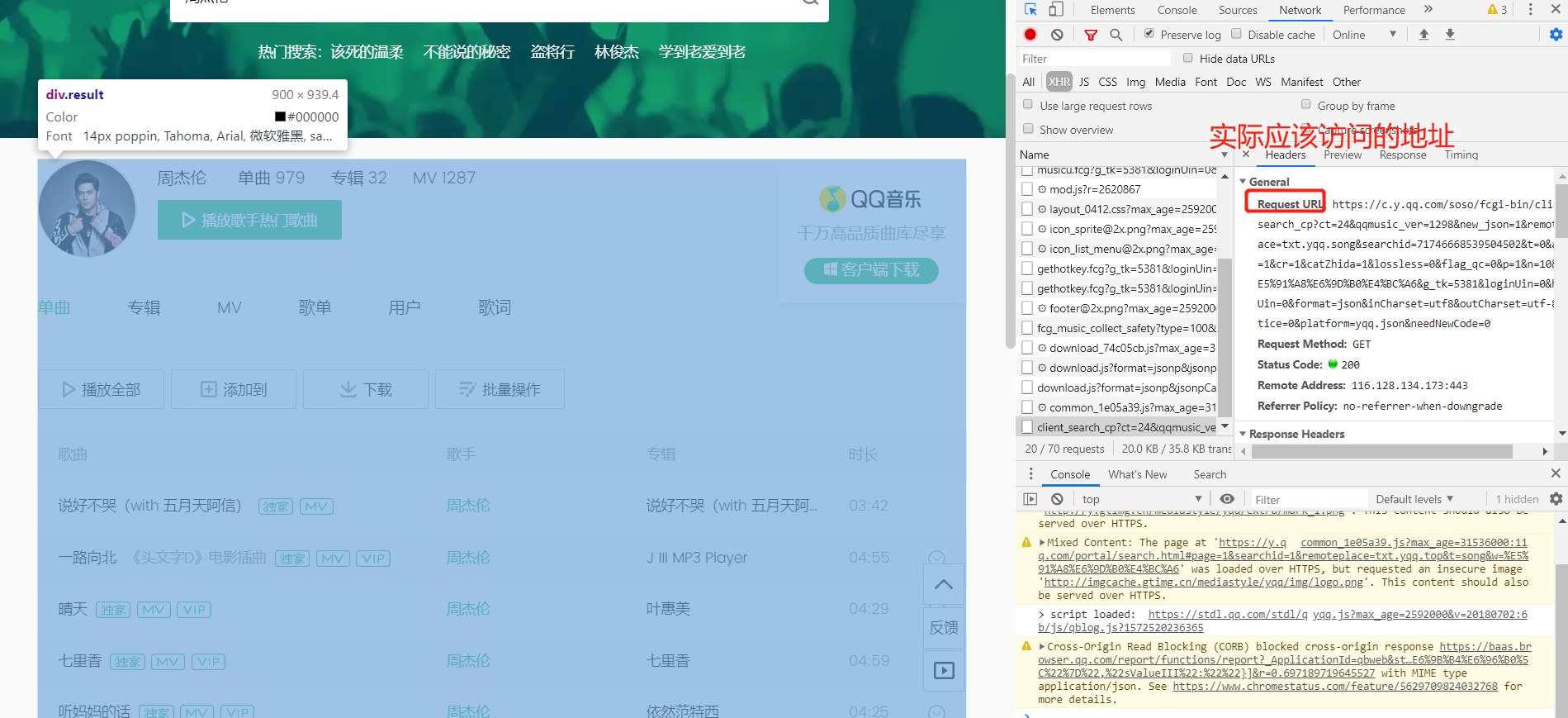
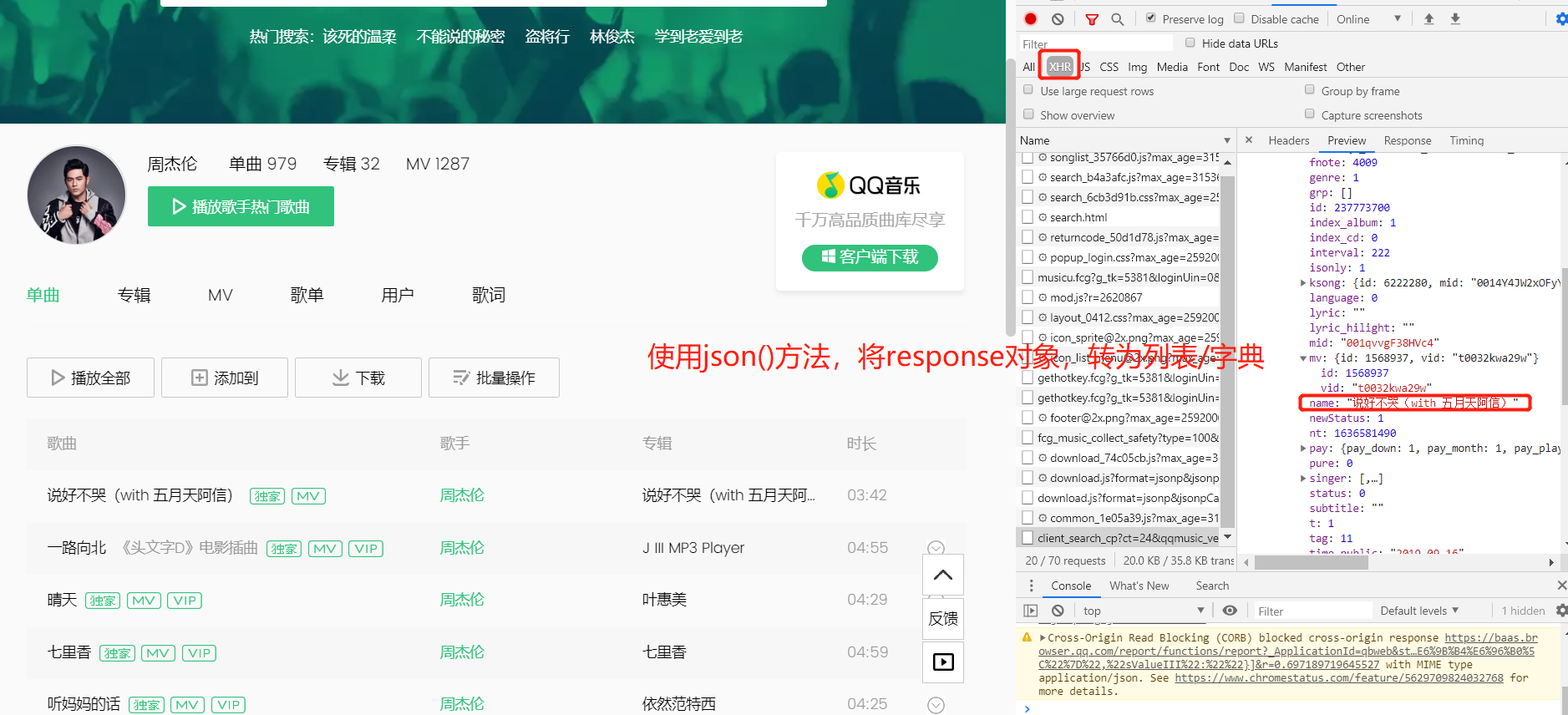
例如:
import requests
from bs4 import BeautifulSoup res = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=71746668539504502&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
res_json = res.json()
songs = res_json['data']['song']['list']
for i in range(len(songs)):
print(songs[i]['name'])
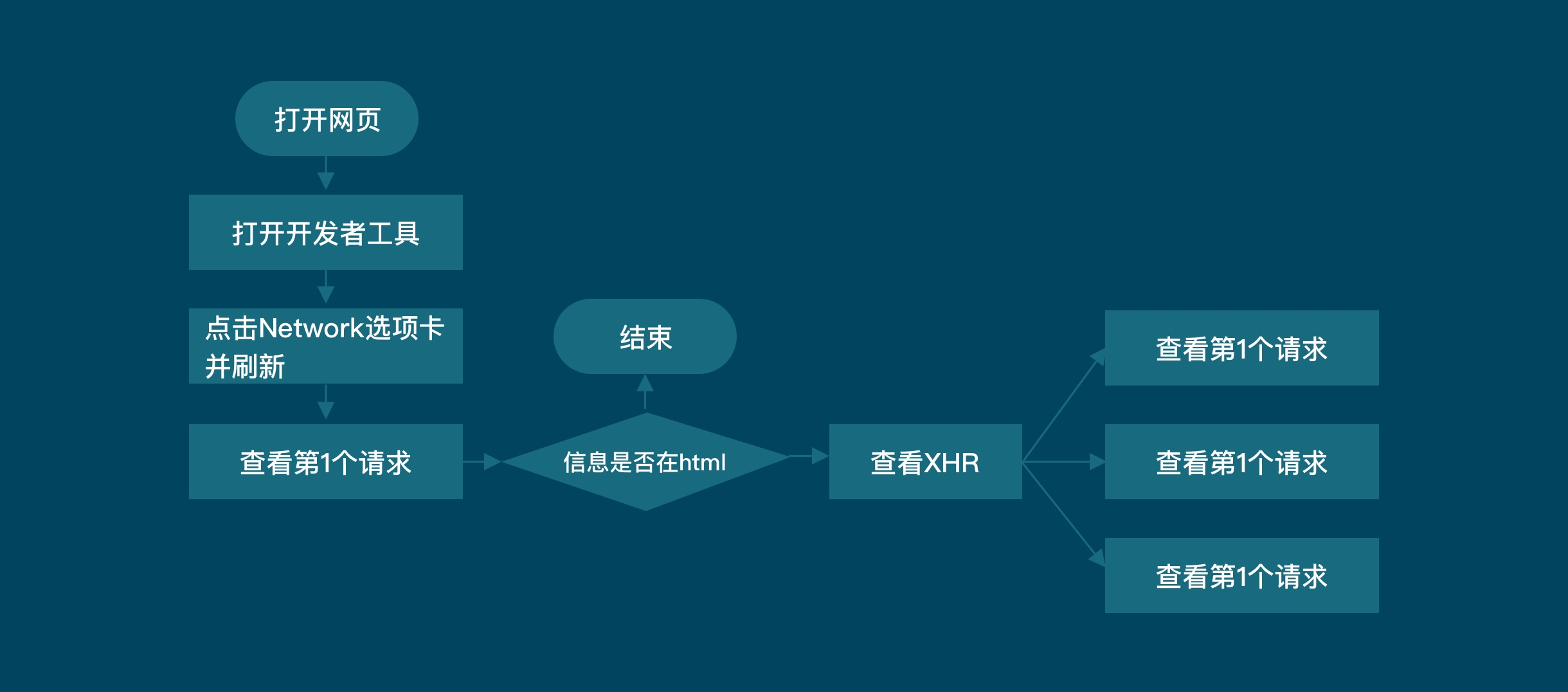
四. 带参数param可以请求不同数据, 带header可以伪装为浏览器
import requests
# 引用requests模块
for i in range(0,3):
url = 'https://movie.douban.com/j/search_subjects'
header = {
'Origin': 'https://y.qq.com',
'Referer': 'https://y.qq.com/portal/search.html',
'Sec-Fetch-Mode': 'cors',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
}
param = {'type': 'movie',
'tag': '热门',
'sort': 'recommend',
'page_limit': '20',
'page_start': i*20}
# print(param)
res_movie = requests.get(url,params=param, headers=header)
# 调用get方法,下载电影列表
json_movie = res_movie.json()
# 使用json()方法,将response对象,转为列表/字典
# print(json_movie)
list_movies = json_movie['subjects']
# 一层一层地取字典,获取电影名称
for comment in list_movies:
# list_movies,comment是它里面的元素
print(comment['title'])
# 输出电影名名称
五.保存数据


python爬取数据分析的更多相关文章
- Python 爬取 热词并进行分类数据分析-[解释修复+热词引用]
日期:2020.02.02 博客期:141 星期日 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- 利用Python爬取朋友圈数据,爬到你开始怀疑人生
人生最难的事是自我认知,用Python爬取朋友圈数据,让我们重新审视自己,审视我们周围的圈子. 文:朱元禄(@数据分析-jacky) 哲学的两大问题:1.我是谁?2.我们从哪里来? 本文 jacky试 ...
- Python 爬取淘宝商品数据挖掘分析实战
Python 爬取淘宝商品数据挖掘分析实战 项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 爬取淘宝商品 ...
- steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 不知不觉,一年一度如火如荼的steam夏日促销悄然开始了.每年通过大大小小 ...
- 用Python爬取B站、腾讯视频、爱奇艺和芒果TV视频弹幕!
众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列.通过分析弹幕,我们可以快速洞察广大观众对于视频 ...
- 如何使用Python爬取基金数据,并可视化显示
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 以下文章来源于Will的大食堂,作者打饭大叔 前言 美国疫情越来越严峻,大选也进入 ...
- python爬取微信小程序(实战篇)
python爬取微信小程序(实战篇) 本文链接:https://blog.csdn.net/HeyShHeyou/article/details/90452656 展开 一.背景介绍 近期有需求需要抓 ...
- 用Python爬取分析【某东618】畅销商品销量数据,带你看看大家都喜欢买什么!
618购物节,辰哥准备分析一波购物节大家都喜欢买什么?本文以某东为例,Python爬取618活动的畅销商品数据,并进行数据清洗,最后以可视化的方式从不同角度去了解畅销商品中,名列前茅的商品是哪些?销售 ...
- 【Python爬虫案例】用Python爬取李子柒B站视频数据
一.视频数据结果 今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至: https://www.cnblogs.com/mashukui/p/1622025 ...
随机推荐
- Des加解密工具
import java.security.Key; import java.security.Security; import java.util.Date; import javax.crypto. ...
- Python爬取视频指南
摘自:https://www.jianshu.com/p/9ca86becd86d 前言 前两天尔羽说让我爬一下菜鸟窝的教程视频,这次就跟大家来说说Python爬取视频的经验 正文 https://w ...
- 123456123456----updateV#%#1%#%---pinLv###20%%%----com.zzj.ChildEnglis698---前show后广--儿童英语-111111111
com.zzj.ChildEnglis698---前show后广--儿童英语-111111111
- Session丢失的原因及解决办法
Asp.net 默认配置下,Session莫名丢失的原因及解决办法: 正常操作情况下Session会无故丢失.因为程序是在不停的被操作,排除Session超时的可能.另外,Session超时时间被设定 ...
- [PHP] dompdf 使用记录
# 安装字体,解决中文乱码参考: https://blog.51cto.com/lampzxr/1916038```首先下载composer curl -sS https://getcomposer. ...
- DNS与ARP协议
DNS(domain name system) DNS的作用:将域名(如baidu.com)转换为IP地址 DNS的本质是:分层的DNS服务器实现的分布式数据库: 根DNS服务器 - com DNS服 ...
- rfc 5280 X.509 PKI 解析
本文以博客园的证书为例讲解,不包含对CRL部分的翻译,如没有对第5章节以及6.3小节进行翻译 3.2. Certification Paths and Trust 下面简单介绍了Public-Key ...
- 将网页html文件离线下载保存到本地的方法
(1)复制想要离线的网页的网址: 范例:http://bbs.xyaz.cn/thread-52540-1-1.html (2)将网址放入迅雷中,让其将html文件下载下来. (3)下载结果
- WSAEventSelect模型
WSAEventSelect模型 EventSelect WSAEventSelect function The WSAEventSelect function specifies an event ...
- TCP Socket 套接字 和 粘包问题
一.Scoket 套接字 Scoket是应用层(应用程序)与TCP/IP协议通信的中间软件抽象层,它是一组接口.也可以理解为总共就三层:应用层,scoket抽象层,复杂的TCP/IP协议 基于TCP协 ...