Beautiful Soup库入门
1.安装:pip install beautifulsoup4
Beautiful Soup库是解析、遍历、维护“标签树”的功能库
2.引用:(1)from bs4 import BeautifulSoup (2)import bs4
BeautifulSoup对应一个HTML/XML文档的全部内容
3.解析器:(1)html.parser (2)lxml pip install lxml (3)html5lib pip install html5lib
4.BeautifulSoup类的基本元素: <p class = "title">...</p>
| Tag | 标签,最基本的信息组成单元,分别用<>和</>标明开头和结尾 |
| Name | 标签的名字,<p>...</p>的名字是'P',格式:<tag>.name |
| Attributes | 标签的属性,字典形式组织,格式:<tag>.attrs |
| NavigableString | 标签内非属性字符串,<>...</>中字符串,格式:<tag>.string |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
5.BeabutifulSoup类型是标签树的根节点
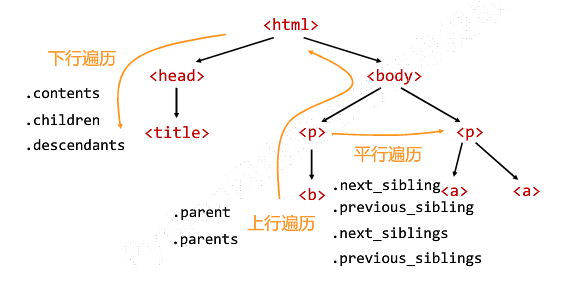
(1)标签树的下行遍历:
| .contents | 子节点的列表,将<tag>所有儿子节点存入列表 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
(2)标签树的上行遍历:
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
(3)标签树的平行遍历:
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
上行遍历需判断是否为本身(例下:)
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
6.bs4库的prettify()方法:
| .prettify()为HTML文本<>及其内容增加更加'\n' | |
| .prettify()可用于标签,方法:<tag>.prettify() |
bs4库将任何HTML输入都变成utf-8编码
7.信息标记的三种形式:XML JSON YAML
信息提取的一般方法:
方法一:完整解析信息的标记形式,再提取关键信息 方法二:无视标记形式,直接搜索关键信息
融合方法:结合形式解析与搜索方法,提取关键信息
8.HTML内容查找方法:<>.find_all(name, attrs, recursive, string, **kwargs)
| name | 对标签名称的检索字符串 |
| attrs | 对标签属性值的检索字符串,可标注属性检索 |
| recursive | 是否对子孙全部检索,默认True |
| string | <>...</>中字符串区域的检索字符串 |
<tag>(...) 等价于 <tag>.find_all(..) soup(..) 等价于 soup.find_all(..)
| <>.find() | 搜索且只返回一个结果,同.find_all()参数 |
| <>.find_parents() | 在先辈节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_parent() | 在先辈节点中返回一个结果,同.find()参数 |
| <>.find_next_siblings() | 在后续平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_next_sibling() | 在后续平行节点中返回一个结果,同.find()参数 |
| <>.find_previous_siblings() | 在前序平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_previous_sibling() | 在前序平行节点中返回一个结果,同.find()参数 |
Beautiful Soup库入门的更多相关文章
- python Beautiful Soup库入门
bs4库的HTML内容遍历方法 基于bs4库的HTML格式输出 显示:友好的显示 <tag>.prettify() 编码:bs4库将任何HTML输入都变成utf-8编码(python 3. ...
- 【转载】Beautiful Soup库(bs4)入门
转载自:Beautiful Soup库(bs4)入门 该库能够解析HTML和XML 使用Beautiful Soup库: from bs4 import BeautifulSoup impo ...
- Beautiful Soup库基础用法(爬虫)
初识Beautiful Soup 官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/# 中文文档:https://www.crumm ...
- Python Beautiful Soup库
Beautiful Soup库 Beautiful Soup库:https://www.crummy.com/software/BeautifulSoup/ 安装Beautiful Soup: 使用B ...
- python beautiful soup库的超详细用法
原文地址https://blog.csdn.net/love666666shen/article/details/77512353 参考文章https://cuiqingcai.com/1319.ht ...
- 【Python爬虫学习笔记(3)】Beautiful Soup库相关知识点总结
1. Beautiful Soup简介 Beautiful Soup是将数据从HTML和XML文件中解析出来的一个python库,它能够提供一种符合习惯的方法去遍历搜索和修改解析树,这将大大减 ...
- python之Beautiful Soup库
1.简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索 ...
- Beautiful Soup库介绍
开始前需安装Beautiful Soup 和lxml. Beautiful Soup在解析时依赖解析器,下表列出bs4支持的解析器. 解析器 使用方法 Python标准库 BeautifulSoup( ...
- Beautiful Soup库
原文传送门:静觅 » Python爬虫利器二之Beautiful Soup的用法
随机推荐
- vscode React编程配置
2.添加RN开发插件 React Native Tools:微软官方出的ReactNative插件,非常好用Reactjs code snippets:react的代码提示,如componentWil ...
- oracle封装OracleHelper
1.Oracle 封装类 using System; using System.Collections.Generic; using System.Linq; using System.Text; u ...
- JavaScript基础08——DOM
DOM的概念 DOM是document Object Model的缩写,简称文档对象模型.他给文档提供了一种结构化的表示方式,可以改变文档的内容和呈现方式 所谓的DOM是以家族的形式描述HTML.父子 ...
- Python 检查代码占用内存 工具和模块
只介绍简单的使用, 更多使用方法请查看官方文档 tracemalloc 官方文档 tracemalloc文档地址 使用 import tracemalloc tracemalloc.start() # ...
- STL next_permutation 全排列
调用方法: ]={,,,}; )){ ;i<;i++) printf("%d ",arr[i]); puts(""); } 测试效果: 注:可以看到1 2 ...
- Fiborial 题解——2019.10.14
一看到这个题 就感觉...cao,, 什么东西...??! 然后就开始暴力求Fn 然鹅我并不会写高精(我太菜了) 只能求到大概10左右 在吧Fn给质因数分解 求出其因子个数 妄图找到什么有关的规律 但 ...
- nginx之http反向代理多台服务器
Nginx http 反向代理高级应用 是Nginx可以基于ngx_http_upstream_module模块提供服务器分组转发.权重分配.状态监测.调度算法等高级功能. http upstream ...
- 在itop4412移植linux4.14和设备树遇到的问题及解决
Linux4.14的设备树下已经对itop4412做了支持,本来应该很容易进行移植,可是在使用讯为给的资料中,对exynos4412-itop-scp-core.dtsi中原本的代码全部进行了注释,并 ...
- 微服务看门神-Zuul
Zuul网关和基本应用场景 构建微服务时,常见的问题是为系统的客户端应用程序提供唯一的网关. 事实上,您的服务被拆分为小型微服务应用程序,这些应用程序应该对用户不可见,否则可能会导致大量的开发/维护工 ...
- 【转】Linux 系统如何处理名称解析
原文写的很好:https://blog.arstercz.com/linux-%E7%B3%BB%E7%BB%9F%E5%A6%82%E4%BD%95%E5%A4%84%E7%90%86%E5%90% ...