【转载】Beautiful Soup库(bs4)入门
from bs4 import BeautifulSoup
import requests
r = requests.get('http://www.23us.so/')
html = r.text
soup = BeautifulSoup(html,'html.parser')
print soup.prettify()
from bs4 import BeautifulSoup
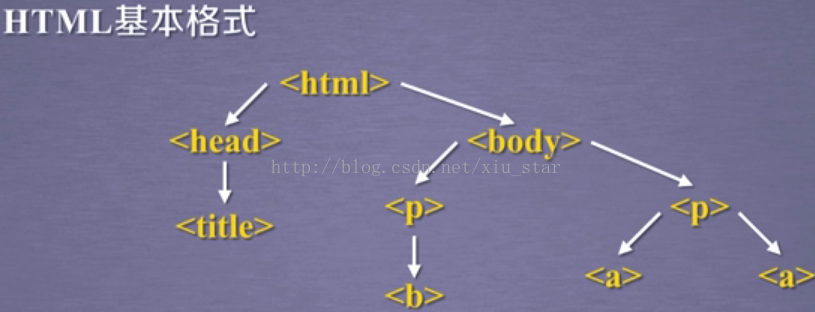
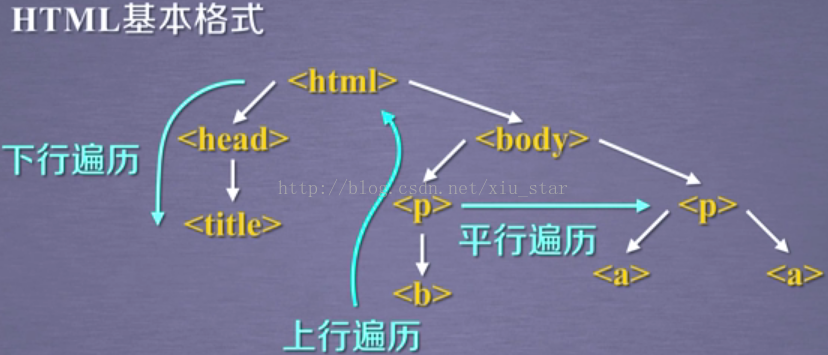
标签树的下行遍历:
- .contents属性:子节点的列表,将<tag>所有儿子节点存入列表
- .children属性:子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
- .descendants属性:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
from bs4 import BeautifulSoup #beautifulsoup4库使用时是简写的bs4
import requests
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo,'html.parser') #解析器:html.parser
child = soup.body.contents
print(child)
for child in soup.body.descendants:
print(child)
- .parent属性:节点的父标签
- parents属性:节点先辈标签的迭代类型,用于循环遍历先辈节点


from bs4 import BeautifulSoup #beautifulsoup4库使用时是简写的bs4
import requests
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo,'html.parser') #解析器:html.parser
print(soup.prettify()) #打印解析好的内容
from bs4 import BeautifulSoup


标签树的下行遍历:
- .contents属性:子节点的列表,将<tag>所有儿子节点存入列表
- .children属性:子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
- .descendants属性:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
import requests
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo,'html.parser') #解析器:html.parser
child = soup.body.contents
print(child)
for child in soup.body.descendants:
- .parent属性:节点的父标签
- parents属性:节点先辈标签的迭代类型,用于循环遍历先辈节点
【转载】Beautiful Soup库(bs4)入门的更多相关文章
- Beautiful Soup库入门
1.安装:pip install beautifulsoup4 Beautiful Soup库是解析.遍历.维护“标签树”的功能库 2.引用:(1)from bs4 import BeautifulS ...
- Beautiful Soup库基础用法(爬虫)
初识Beautiful Soup 官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/# 中文文档:https://www.crumm ...
- Python Beautiful Soup库
Beautiful Soup库 Beautiful Soup库:https://www.crummy.com/software/BeautifulSoup/ 安装Beautiful Soup: 使用B ...
- crawler碎碎念4 关于python requests、Beautiful Soup库、SQLlite的基本操作
Requests import requests from PIL import Image from io improt BytesTO import jason url = "..... ...
- 【Python爬虫学习笔记(3)】Beautiful Soup库相关知识点总结
1. Beautiful Soup简介 Beautiful Soup是将数据从HTML和XML文件中解析出来的一个python库,它能够提供一种符合习惯的方法去遍历搜索和修改解析树,这将大大减 ...
- python beautiful soup库的超详细用法
原文地址https://blog.csdn.net/love666666shen/article/details/77512353 参考文章https://cuiqingcai.com/1319.ht ...
- python之Beautiful Soup库
1.简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索 ...
- Beautiful Soup库介绍
开始前需安装Beautiful Soup 和lxml. Beautiful Soup在解析时依赖解析器,下表列出bs4支持的解析器. 解析器 使用方法 Python标准库 BeautifulSoup( ...
- Beautiful Soup库
原文传送门:静觅 » Python爬虫利器二之Beautiful Soup的用法
随机推荐
- Codeforces Round #409 (rated, Div. 2, based on VK Cup 2017 Round 2)
A 每次可以换一个或不换,暴力枚举位置即可 B 模拟 C 二分答案.. 边界可以优化r=totb/(tota-p),二分可以直接(r-l>=EPS,EPS不要太小,合适就好),也可以直接限定二分 ...
- spark core (二)
一.Spark-Shell交互式工具 1.Spark-Shell交互式工具 Spark-Shell提供了一种学习API的简单方式, 以及一个能够交互式分析数据的强大工具. 在Scala语言环境下或Py ...
- 解题:ZJOI 2006 游戏排名系统
题面 跟i207M学了学重载运算符后找前驱后继,然后就是练练无旋树堆 #include<map> #include<cstdio> #include<string> ...
- python函数:字符串函数示例
优先掌握的操作 #作用:名字,性别,国籍,地址等描述信息 #定义:在单引号\双引号\三引号内,由一串字符组成 name='egon' #优先掌握的操作: #1.按索引取值(正向取+反向取) :只能取 ...
- PID控制算法的C语言实现七 梯形积分的PID控制算法C语言实现
在PID控制律中积分项的作用是消除余差,为了减小余差,应提高积分项的运算精度,为此,可将矩形积分改为梯形积分. 梯形积分的计算公式为: pid.voltage=pid.Kp*pid.err+index ...
- Codeforces Round #410 (Div. 2)A B C D 暴力 暴力 思路 姿势/随机
A. Mike and palindrome time limit per test 2 seconds memory limit per test 256 megabytes input stand ...
- 洛谷P2345 奶牛集会
题目背景 MooFest, 2004 Open 题目描述 约翰的N 头奶牛每年都会参加“哞哞大会”.哞哞大会是奶牛界的盛事.集会上的活动很 多,比如堆干草,跨栅栏,摸牛仔的屁股等等.它们参加活动时会聚 ...
- uniqid()
uniqid() 函数基于以微秒计的当前时间,生成一个唯一的 ID.
- js 30分钟倒计时
<html> <head> <meta charset="UTF-8"> <title></title> </he ...
- 前端PHP入门-030-文件函数API
bool file_exists ( $指定文件名或者文件路径) 功能:文件是否存在. bool is_readable ( $指定文件名或者文件路径) 功能:文件是否可读 bool is_write ...