【Hadoop】二、HDFS文件读写流程
(二)HDFS数据流
作为一个文件系统,文件的读和写是最基本的需求,这一部分我们来了解客户端是如何与HDFS进行交互的,也就是客户端与HDFS,以及构成HDFS的两类节点(namenode和datanode)之间的数据流是怎样的。
1、剖析文件读取过程
客户端从HDFS读取文件,其内部的读取过程实际是比较复杂的,可以用下图来表示读取文件的基本流程。
对于客户端来说,首先是调用FileSystem对象的open()方法来打开希望读取的文件,然后DFS会返回一个文件输入流FSDataInputStream ,客户端对这个输入流调用read()方法,读取数据,一旦完成读取,就对这个输入流调用close()方法关闭,这三个过程对应图中的步骤1、3、6。
以上三个步骤是从客户端的角度来分析的,实际上,要实现文件读取,HDFS内部还需要比较复杂的机制来支持,而这些过程都是对客户端透明的,所以客户端感受不到,在客户看来就像是在读取一个连续的流。
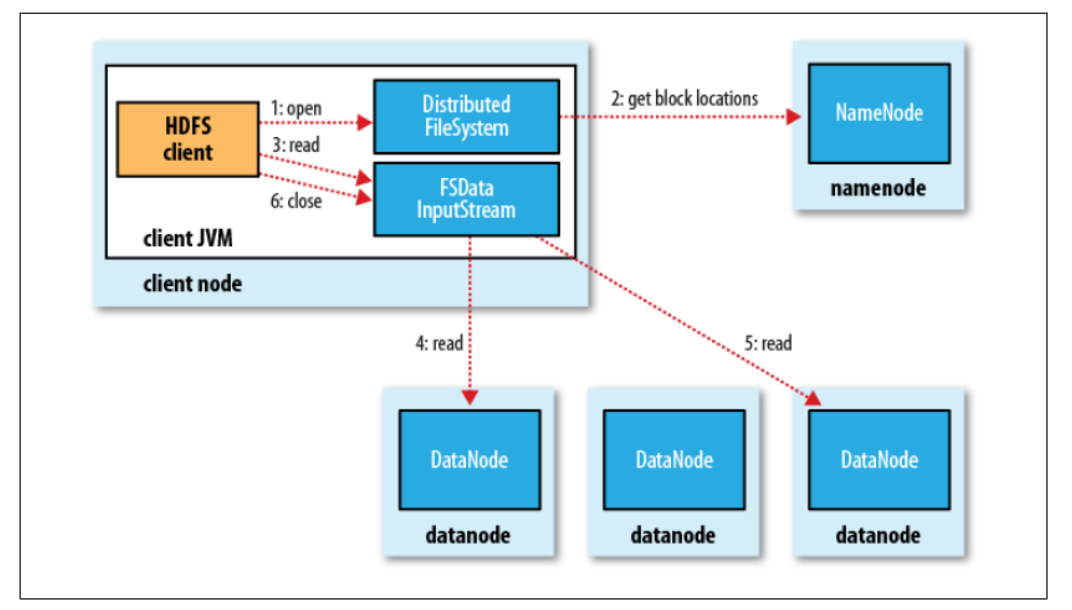
具体的,从HDFS的角度来说,客户端调用的FileSystem对象的open()方法,这个FileSystem对象实际上是分布式文件系统DistributedFileSystem的一个实例,DistributedFileSystem通过远程过程调用(RPC)来调用namenode,以获得文件起始块的位置(步骤2,namenode返回存有该数据块副本的datanode的地址)。当然,由于HDFS保存了一个数据块的多个副本(默认是3),所以满足请求的datanode地址不止一个,此时会根据它们与客户端的距离来排序,优先选择距离近的datanode,如果该客户端本身就是一个datanode,该客户端就可以从本地读取数据(比如:mapReduce就利用了这里的数据本地化优势)。
open方法完成后,DistributedFileSystem类返回一个FSDataInputStream文件输入流对象给客户端。这个类转而封装为DFSInputStream对象,该对象管理着datanode和namenode的I/O。
这个DFSInputStream存储着文件起始几个块的datanode地址,因此,客户端对这个输入流调用read()方法就可以知道到哪个datanode(网络拓扑中距离最近的)去读取数据,这样,反复调用read方法就可以将数据从datanode传输到客户端(步骤4)。到达一个块的末端时,会关闭和这个datanode的连接,寻找下一个块的最佳datanode,重复这个过程。
当然,上面我们说DFSInputStream只存储着文件起始的几个块,在读取过程中,也会根据需要再次询问namenode来获取下一批数据块的datanode地址。一旦客户端读取完成,就调用close方法关闭数据流。
如果在读取过程中,datanode遇到故障,很明显,输入流只需要从另外一个保存了该数据块副本的最近datanode读取即可,同时记住那个故障datanode,以后避免从那里读取数据。
总结:
以上就是HDFS的文件读取过程,从这个过程的分析中我们可以看出:其优势在于客户端可以直接连接到datanode进行数据的读取,这样由于数据分散在不同的datanode上,就可以同时为大量并发的客户端提供服务。而namenode作为管理节点,只需要响应数据块位置的请求,告知客户端每个数据块所在的最佳datanode即可(datanode的位置信息存储在内存中,非常高效的可以获取)。这样使得namenode无需进行具体的数据传输任务,否则namenode在客户端数量多的情况下会成为瓶颈。
2、剖析文件写入过程
接下来我们分析文件写入的过程,重点考虑的情况是如何新建一个文件、如何将数据写入文件并最后关闭该文件。
同样的道理,从客户端的角度来说,这个过程是比较简单的,首先通过对DistributedFileSystem对象调用create()方法来新建文件,然后会返回一个FSDataOutputStream的文件输出流对象,由此客户端便可以调用这个输出流的write()方法写入数据,完成写入后,调用close()方法关闭输出流(下图中的步骤1、3、6)。
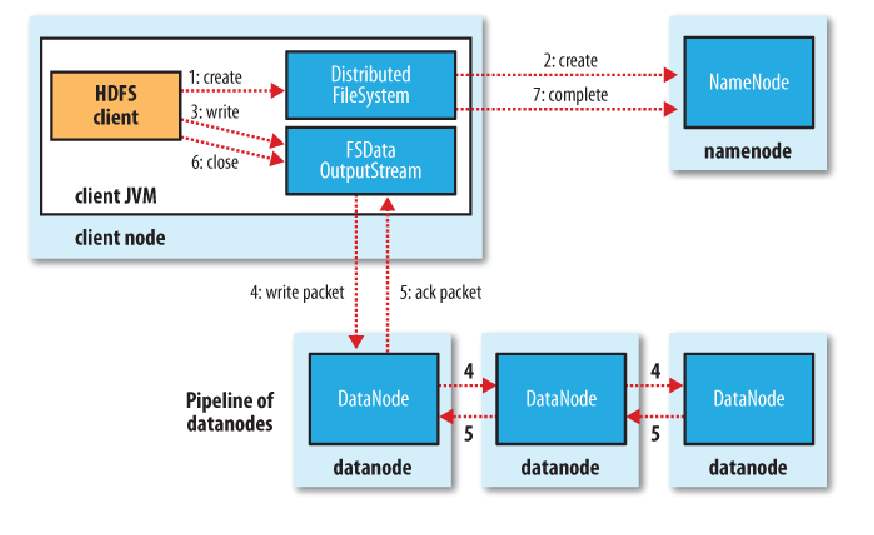
然而,具体的,从HDFS的角度来看,这个写数据的过程就相当复杂了。客户端在调用create方法新建文件时,DistributedFileSystem会对namenode创建一个RPC调用,在文件系统的命名空间中新建一个文件,此时还没有相应的数据块(步骤2)。namedata接收到这个RPC调用后,会进行一系列的检查,确保这个文件不存在,并且这个客户端有新建文件的权限,然后再通过检查后就会为这个新文件在命名空间中加入一条记录(如果未通过检查则会返回异常),最后给客户端返回一个FSDataOutputStream对象。
类似于文件读的过程,这个FSDataOutputStream对象转而封装成为一个DFSOutputStream对象,用于处理datanode和namenode之间的I/O。
接下来,客户端就可以调用输出流的write()方法进行数据写入,而在写入时,DFSOutputStream将数据分为一个一个的数据包,先写入内部队列,称为“数据队列”。然后有一个单独的DataStreamer来处理数据队列,它的职责是挑选出适合存储数据副本的一组datanode,并要求namenode分配新的数据块。假设副本数为3,那么选出来的datanode就是3个,这3个dadanode会构成一个数据管线。DataStreamer将数据包流式传输到管线中的第一个datanode,第一个存储并发到第二个,第二个存储并发到第三个(步骤4)。
然后DFSOutputStream对象内部还有一个数据包队列用于接收datanode的确认回执,称为“确认队列”,收到所有datanode的确认消息后,该数据包才会从队列中删除。
在客户端完成数据的写入后,对数据流调用close()方法(步骤6),该操作将剩余的所有数据包写入数据管线,并联系namenode告知文件写入完成之前,等待确认(步骤7)。
3、一致模型
HDFS的一致模型描述了文件读、写的数据可见性。
基于以上对文件读写过程的分析,我们知道新建一个文件之后,它可以在命名空间中立即可见,但是即使数据流已经刷新并存储,写入文件的内容并不保证能立即可见。当写入的数据超过一个数据块后,第一个数据块对新的reader就是可见的,也就是说:当前正在写的块对其他reader不可见。
HDFS提供了一种将所有缓存刷新到datanode中的方法,即对FSDataOutputStream调用hflush()方法,当hflush方法调用成功后,到目前为止写入的数据都到达了datanode的写入管道并且对所有reader可见。
但是,hflush()并不保证数据已经都写到磁盘上,为确保数据都写入磁盘,可以使用hsync()操作代替。
在HDFS中,close方法实际上隐含了执行hflush()方法。
4、通过distcp并行复制
当我们想从Hadoop文件系统中复制大量数据或者将大量数据复制到HDFS中时,可以采用Hadoop自带的一个程序distcp,它用来并行复制。
distcp的一个用法是代替hadoop fs -cp,也可以用来在两个HDFS集群之间传输数据。
$ hadoop distcp file1 file2
$ hadoop distcp dir1 dir2
$ hadoop distco -update -delete -p hdfs://namenode1/foo hdfs://namenode2/foo
总结
以上主要对HDFS文件系统的文件读写进行了详细的介绍,重点是掌握HDFS的文件读写流程,体会这种机制对整个分布式系统性能提升带来的好处。
【Hadoop】二、HDFS文件读写流程的更多相关文章
- HDFS文件读写流程
一.HDFS HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而对于低延时数据访问.大量 ...
- hadoop笔记-hdfs文件读写
概念 文件系统 磁盘进行读写的最小单位:数据块,文件系统构建于磁盘之上,文件系统的块大小是磁盘块的整数倍. 文件系统块一般为几千字节,磁盘块一般512字节. hdfs的block.pocket.chu ...
- Hadoop之HDFS文件读写过程
一.HDFS读过程 1.1 HDFS API 读文件 Configuration conf = new Configuration(); FileSystem fs = FileSystem.get( ...
- HDFS文件读写流程 (转)
文件读取的过程如下: 使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求: Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namen ...
- HDFS的读写流程——宏观与微观
HDFS的读写流程--宏观与微观 HDFS:分布式文件系统,负责存放数据 分布式文件系统:就是将我们的数据放到多台电脑上存储. 写数据:就是将客户端上的数据上传到HDFS 宏观过程 客户端向HDFS发 ...
- Hadoop之HDFS文件操作常有两种方式(转载)
摘要:Hadoop之HDFS文件操作常有两种方式,命令行方式和JavaAPI方式.本文介绍如何利用这两种方式对HDFS文件进行操作. 关键词:HDFS文件 命令行 Java API HD ...
- HDFS 文件读写过程
HDFS 文件读写过程 HDFS 文件读取剖析 客户端通过调用FileSystem对象的open()来读取希望打开的文件.对于HDFS来说,这个对象是分布式文件系统的一个实例. Distributed ...
- Hadoop之HDFS文件操作
摘要:Hadoop之HDFS文件操作常有两种方式.命令行方式和JavaAPI方式.本文介绍怎样利用这两种方式对HDFS文件进行操作. 关键词:HDFS文件 命令行 Java API HD ...
- HDFS04 HDFS的读写流程
HDFS的读写流程(面试重点) 目录 HDFS的读写流程(面试重点) HDFS写数据流程 网络拓扑-节点距离计算 机架感知(副本存储节点的选择) HDFS的读数据流程 HDFS写数据流程 客服端把D: ...
随机推荐
- 查看jvm常用命令
jinfo:可以输出并修改运行时的java 进程的opts. jps:与unix上的ps类似,用来显示本地的java进程,可以查看本地运行着几个java程序,并显示他们的进程号. jstat:一个极强 ...
- Codeforces Round #311 (Div. 2) D - Vitaly and Cycle
D. Vitaly and Cycle time limit per test 1 second memory limit per test 256 megabytes input standard ...
- ATM网络
ATM是Asynchronous Transfer Mode(ATM)异步传输模式的缩写,是实现B-ISDN的业务的核心技术之一.ATM是以信元为基础的一种分组交换和复用技术
- C#与excel互操作的错误无法将类型为“Microsoft.Office.Interop.Excel.ApplicationClass”的 COM 对象强制
C#与excel互操作的错误无法将类型为“Microsoft.Office.Interop.Excel.ApplicationClass”的 COM 对象强制 如果您使用的电脑要操作的是office2 ...
- 什么是javascript闭包?
在我们开发中,也经常使用到闭包,但当有人问什么是闭包,就会可能说不上来.那就谈谈一些基本的: 一.理解闭包的概念, 简单说当function里嵌套function时,内部的function可以访问外部 ...
- 转贴:CSS伪类与CSS伪元素的区别及由来具体说明
关于两者的区别,其实是很古老的问题.但是时至今日,由于各种网络误传以及一些不负责任的书籍误笔,仍然有相当多的人将伪类与伪元素混为一谈,甚至不乏很多CSS老手.早些年刚入行的时候,我自己也被深深误导,因 ...
- 私有CA和证书
证书类型 证书授权机构的证书 服务器 用户证书 获取证书两种方法 使用证书授权机构: 生成签名请求(csr ) 将csr发送给CA 从CA处接收签名 自签名的证书: 自已签发自己的公钥 openSSL ...
- 10.24afternoon清北学堂刷题班
/* 这是什么题... */ #include<iostream> #include<cstdio> #include<cstring> #include<q ...
- [App Store Connect帮助]六、测试 Beta 版本(4.1) 管理 Beta 版构建版本:为构建版本添加测试员
在“TestFlight”部分中,您可以查看您所有 App 版本的构建版本,并深入查看构建版本的详细信息.您也可以为某个构建版本添加群组或独立测试员. 必要职能:“帐户持有人”职能.“管理”职能或“A ...
- python实现对某招聘网接口测试获取平台信息
"""通过接口测试的技术获取某招聘网平台的资料"""url = "https://www.lagou.com/jobs/posit ...