HDFS04 HDFS的读写流程
HDFS的读写流程(面试重点)
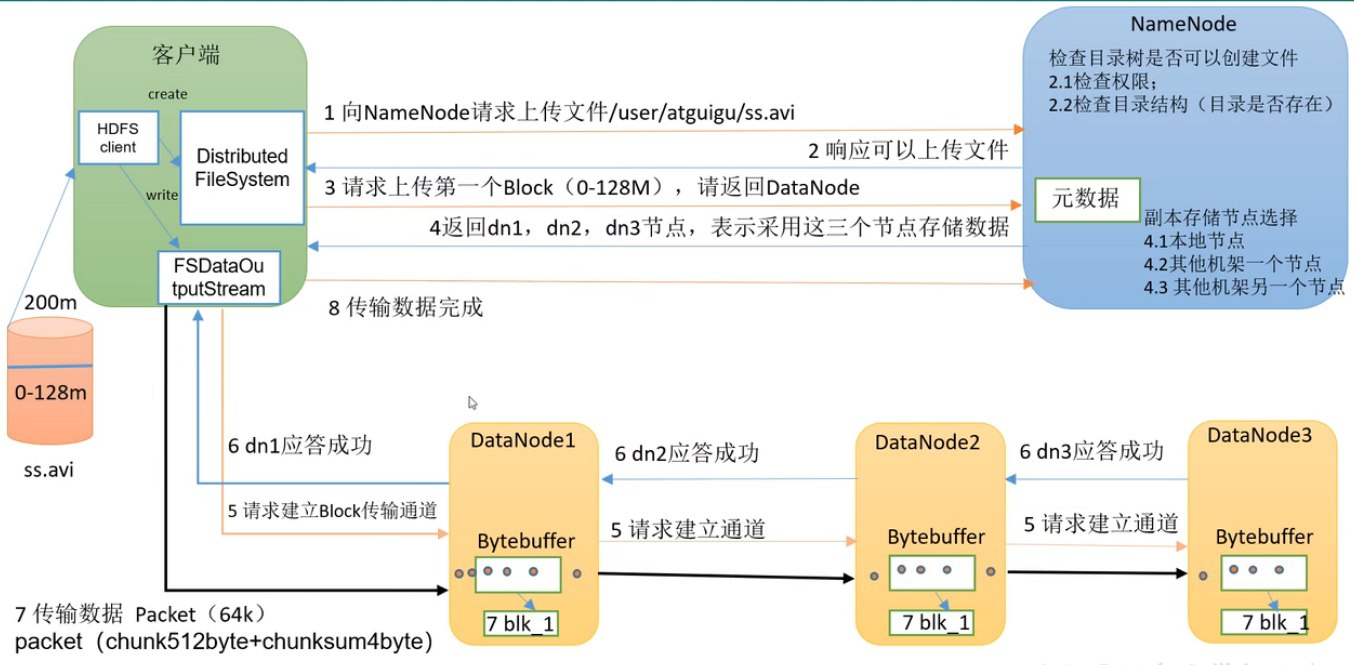
HDFS写数据流程
客服端把D://ss.avi文件传送到集群
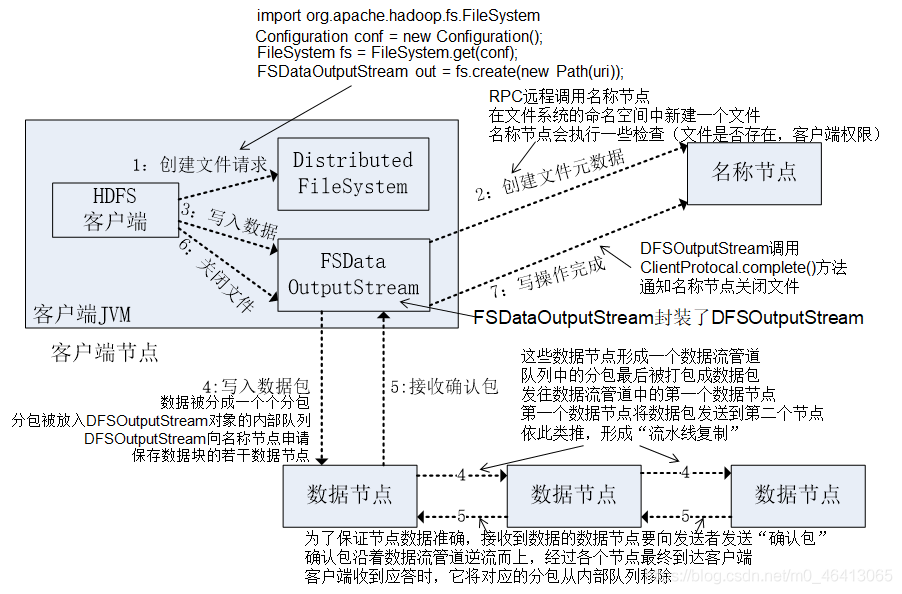
1.首先需要创建一个Distributed FileSystem(分布式文件系统)客服端。向NameNode请求上传文件。上传到/user/atguigu/ss.avi路径。
2.NameNode 检查用户是否有权限,检查目标路径/user/atguigu是否可行,检测目标文件ss.avi是否存在。检查完毕后返回结果,是否可以上传文件。
3.客户端请求第一个 Block 上传到哪几个 DataNode 服务器上。
4.NameNode根据选择策略返回 DataNode 节点。
5.客户端创建FSDataOutPutStream,请求 dn1建立Block传输通道,dn1 收到请求会继续传给dn2,然后 dn2 传给 dn3,将这个通信管道建立完成。
6.dn3、dn2、dn1应答客户端。
7.dn1在磁盘中写的过程中,同时把数据传给dn2。以Packet(64k)为单位,dn1收到一个 Packet就会传给dn2,dn2 传给 dn3。每个dn都有ACK队列,应答成功后,缓存的数据才会清空,如果失败,缓存数据用于重发。
(8)当一个 Block 传输完成之后, 客户端再次请求 NameNode 上传第二个 Block。(重复执行 3-7 步)
补充:选择策略
节点距离最近与负载均衡
4.1优先本地节点
4.2其他机架A一个节点
4.3其他机架A另一个节点
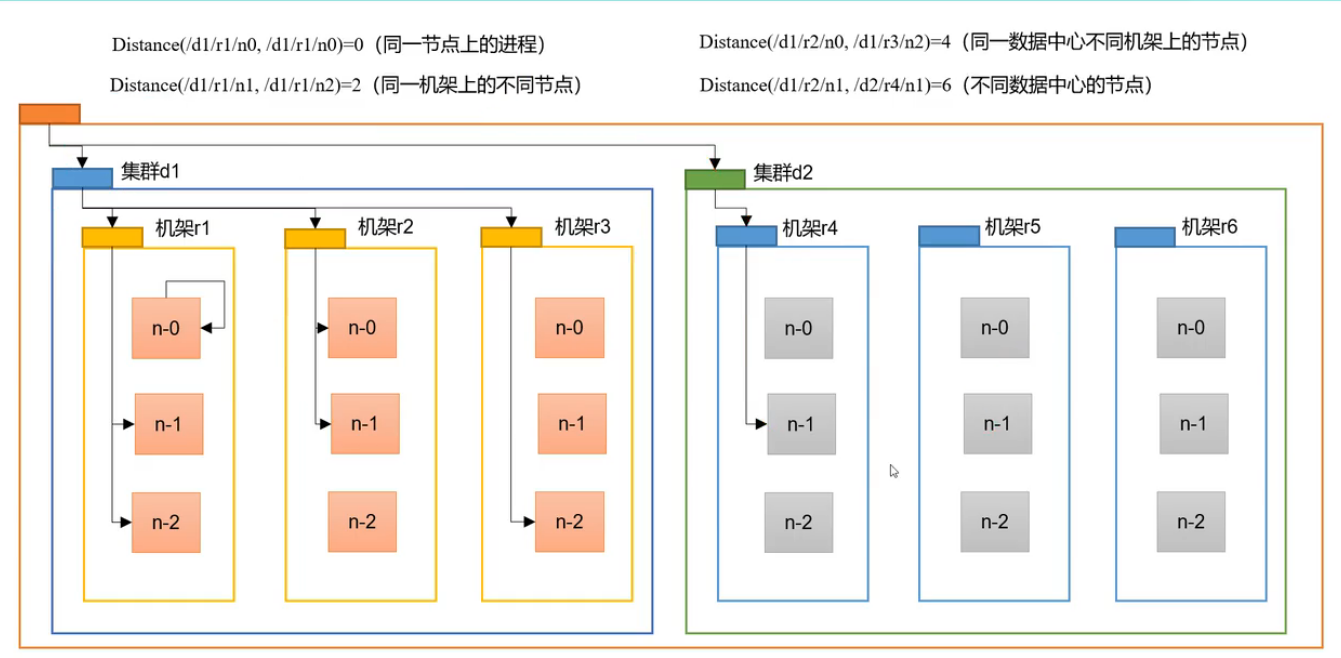
网络拓扑-节点距离计算
在HDFS写数据的过程中,NameNode会选择距 离待传上传数据最近距离 的DataNode接收。那么这个最近距离怎么计算?
节点距离:两个节点到达最近的共同祖先的距离总和。
例如,假设有数据中心 d1 机架 r1 中的节点 n1。该节点可以表示为/d1/r1/n1。以下给出了四种类型距离描述。
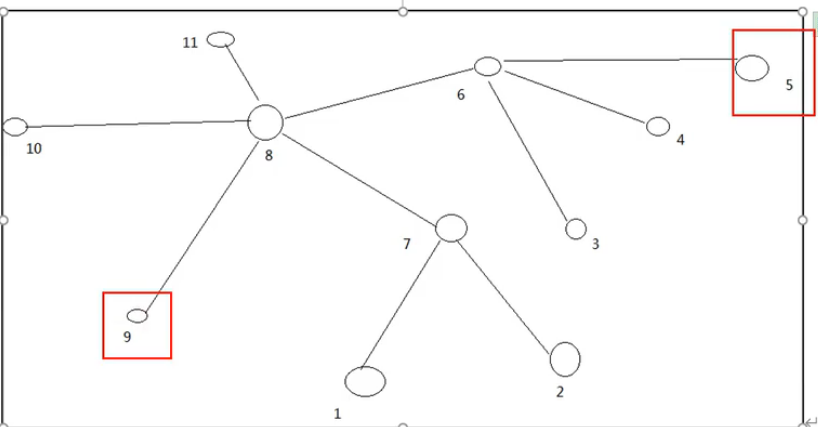
案例
计算节点5与节点9之间的节点距离是多少 -3
计算节点2与节点10之间的节点距离是多少 -3
机架感知(副本存储节点的选择)
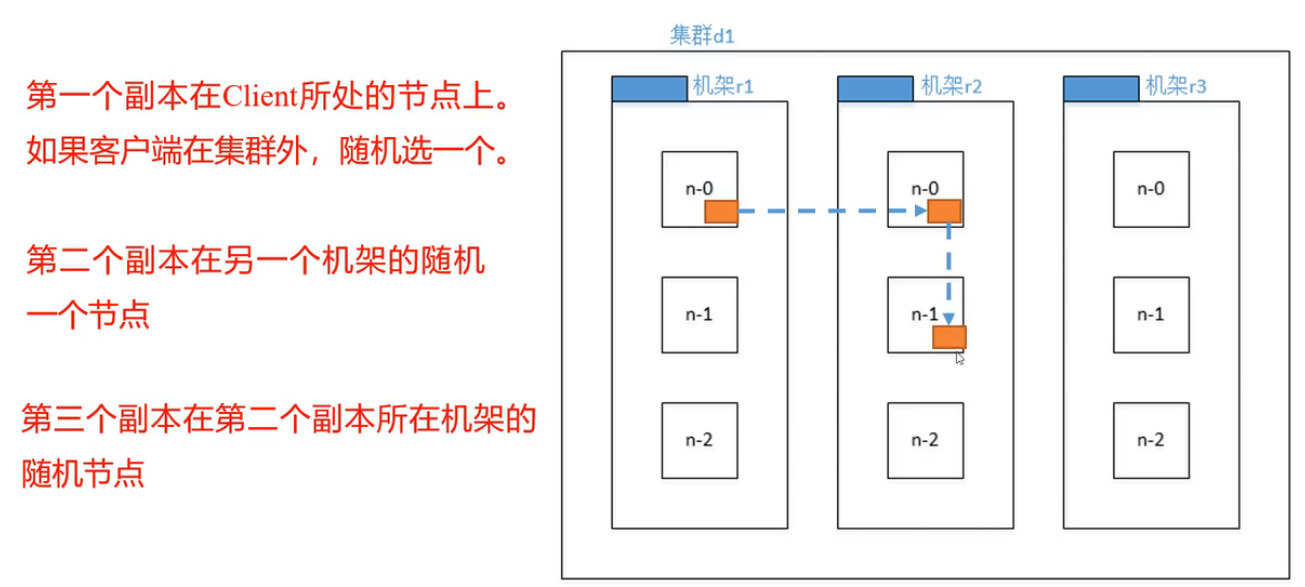
第一个副本考虑的是节点距离最近,上传速度最快。
第二个副本保证数据可靠性。
第三个副本兼顾效率与速度。
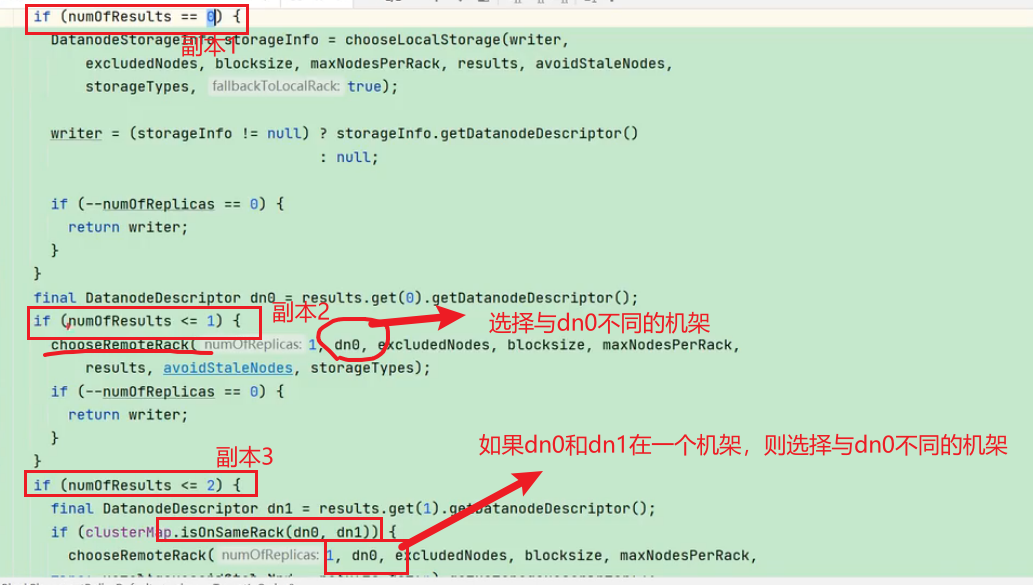
查看源码
Crtl + n 查找 BlockPlacementPolicyDefault类,在该类中查找 chooseTargetInOrder 方法。

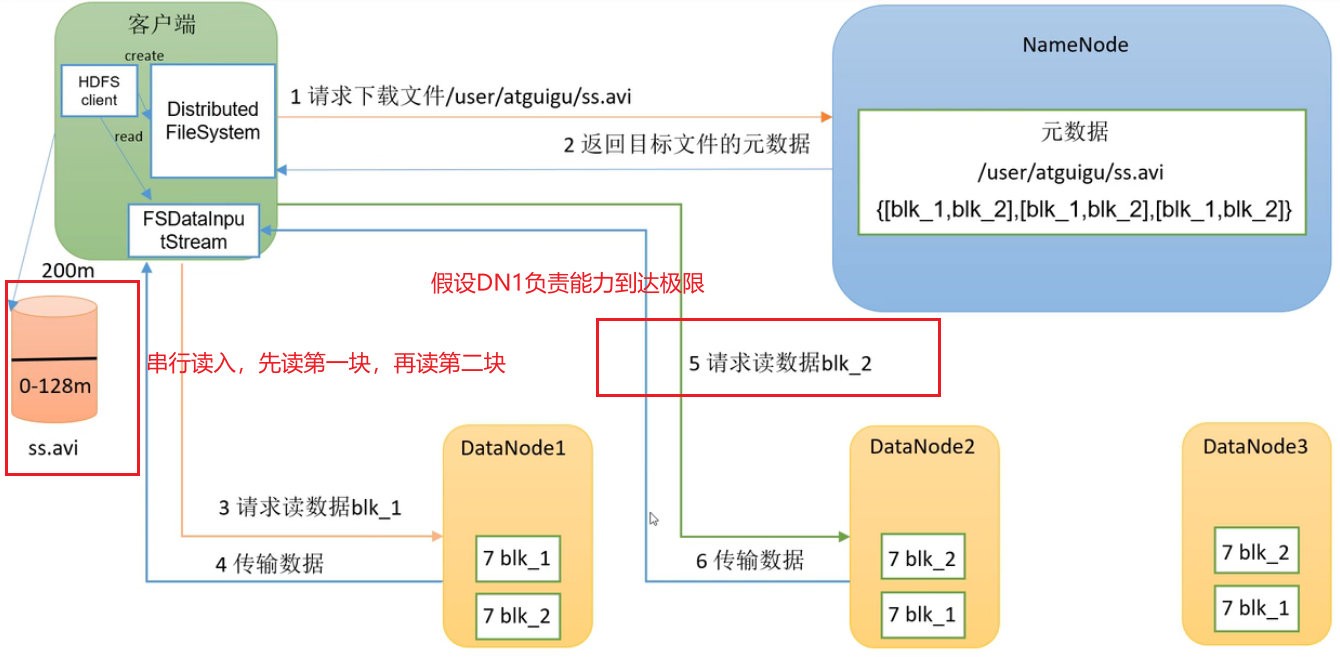
HDFS的读数据流程
把HDFS的数据读到本地
1.客户端通过 DistributedFileSystem 向 NameNode 请求下载文件。
2.NameNode先判断权限再通过查询元数据,找到文件块所在的 DataNode 地址,返回目标文件的元数据。
3.客户端创建FSDataInputStream流对象,挑选一台 DataNode服务器(就近原则与负载能力),请求读取数据。 假设DN1负载能力到了极限,串行读,先读第一块,再读第二块
(3)DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位来做校验)。
(4)客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。
HDFS04 HDFS的读写流程的更多相关文章
- HDFS的读写流程——宏观与微观
HDFS的读写流程--宏观与微观 HDFS:分布式文件系统,负责存放数据 分布式文件系统:就是将我们的数据放到多台电脑上存储. 写数据:就是将客户端上的数据上传到HDFS 宏观过程 客户端向HDFS发 ...
- HDFS文件读写流程
一.HDFS HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而对于低延时数据访问.大量 ...
- 【Hadoop】二、HDFS文件读写流程
(二)HDFS数据流 作为一个文件系统,文件的读和写是最基本的需求,这一部分我们来了解客户端是如何与HDFS进行交互的,也就是客户端与HDFS,以及构成HDFS的两类节点(namenode和dat ...
- HDFS文件读写流程 (转)
文件读取的过程如下: 使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求: Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namen ...
- HDFS的读写流程
1.2. 客户端向NameNode发起创建文件的请求,在NameNode上创建一个文件名,并且返回一个输出流 3.客户端向输出流发起写入数据的请求 4.输出流向NameNode请求写数据,NameNo ...
- Hadoop---HDFS读写流程
Hadoop---HDFS HDFS 性能详解 HDFS 天生是为大规模数据存储与计算服务的,而对大规模数据的处理目前还有没比较稳妥的解决方案. HDFS 将将要存储的大文件进行分割,分割到既定的存储 ...
- 大数据系列文章-Hadoop的HDFS读写流程(二)
在介绍HDFS读写流程时,先介绍下Block副本放置策略. Block副本放置策略 第一个副本:放置在上传文件的DataNode:如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点. 第二 ...
- 【转】HDFS读写流程
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现. 特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性流式数据访问 ...
- 超详细的HDFS读写流程详解(最容易理解的方式)
HDFS采用的是master/slaves这种主从的结构模型管理数据,这种结构模型主要由四个部分组成,分别是Client(客户端).Namenode(名称节点).Datanode(数据节点)和Seco ...
随机推荐
- Linux题目学习
一.填空题: 1. 在Linux系统中,以 文件 方式访问设备 . 2. Linux内核引导时,从文件/etc/fstab 中读取要加载的文件系统. 3. Linux文件系统中每个文件用 i节点来标识 ...
- 剖析虚幻渲染体系(12)- 移动端专题Part 1(UE移动端渲染分析)
目录 12.1 本篇概述 12.1.1 移动设备的特点 12.2 UE移动端渲染特性 12.2.1 Feature Level 12.2.2 Deferred Shading 12.2.3 Groun ...
- java核心技术 第3章 java基本程序设计结构
类名规范:以大写字母开头的名词 若由多个单词组成 每个单词的第一个字母应大写(驼峰命名法) 与.java文件名相同 运行程序:java ClassName(dos命令) 打印语句:System.ou ...
- Java测试开发--Java基础知识(二)
一.java中8大基本类型 数值类型:byte.short.int .float.double .long 字符类型:char 布尔类型:boolean 二. 封装:将属性私有化,不允许外部数据直接访 ...
- idea连接数据库时区错误
错误界面 IDEA连接mysql,地址,用户名,密码,数据库名,全都配置好了,点测试连接,咔!不成功! 界面是这样的, 翻译过来就是:服务器返回无效时区.进入"高级"选项卡,手动设 ...
- js中的特数值-null-undefined-NaN
一.补充 1.js中的三大特殊数据:undefined.null.NaN NaN :非法的数值运算得到的结果 特殊之处: 是一个数值型数据,但不是一个数字 NaN不等于任何值,和任何数据都不相等,Na ...
- Redis核心原理与实践--事务实践与源码分析
Redis支持事务机制,但Redis的事务机制与传统关系型数据库的事务机制并不相同. Redis事务的本质是一组命令的集合(命令队列).事务可以一次执行多个命令,并提供以下保证: (1)事务中的所有命 ...
- C#中base 和this
[意义] this:指当前类,this调用当前类的属性,方法,包括构造函数的方法,继承本类的构造函数 base:指当前类的父类,可调用父类的非私有属性,方法,继承父类的构造函数括号里的参数 [用处] ...
- js实现全选与全部取消功能
function checkAll() { //把所有参与选择的checkbox使用相同的name,这里为"num_iid" var eles = document.getE ...
- Spring Boot中如何自定义starter?
Spring Boot starter 我们知道Spring Boot大大简化了项目初始搭建以及开发过程,而这些都是通过Spring Boot提供的starter来完成的.品达通用权限系统就是基于Sp ...