KNN-K近邻算法(1)
KNN(K-nearest neighbors)
- 思想简单
- 数学所需知识少(近零)
- 效果好
- 可解释机器学习算法使用过程中的很多细节问题
- 更完整的刻画机器学习应用的流程
- 天然可解决多分类问题
- 可解决回归问题
K近邻本质:如果两个样本足够相似,那么它们就有可能属于同一类别。
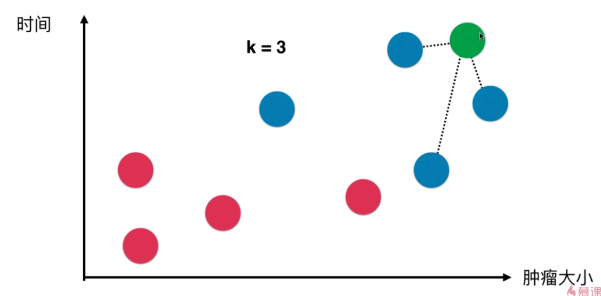
e.g. 绿色的点是新加入的点,取其最近的k(3)个点作为小团体来投票,票数高的获胜(蓝比红-3:0),所以绿点应该也是蓝点
计算距离:
最常见 -> 欧拉距离,求a, b两点的距离(二维,三维,多维):
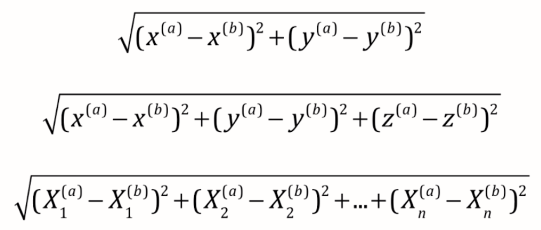 ->
-> 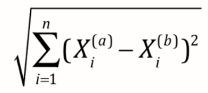
理解小笔记:((a样本第一个维度特征-b样本第一个维度特征)2 + (a样本第二个维度特征-b样本第二个维度特征)2 + ... ) 再开根
近乎可以说,KNN算法是机器学习中唯一一个不需要训练过程的算法。输入用例可直接送给训练数据集。
- KNN可以被认为是没有模型的算法
- 为和其他算法统一,可认为其训练数据集本身就是模型
使用KNN解决回归问题
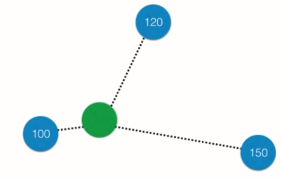
绿点的值即可设为离它最近的三个点的(加权)平均值
KNN缺点
最大缺点:效率低下。
如果训练集有m个样本,n个特征,则预测每一个新的数据,都需要计算它与每一个点之间的距离(共m个点),每计算一个点的距离就需要O(n)的时间复杂度。
每预测一个,共需要O(m*n)的时间复杂度。
优化,使用树的结构:KD-Tree, Ball-Tree
缺点2:高度数据相关
尽管所有的机器学习算法都是根据给定的数据集来学习,都是高度数据相关的。但KNN相对而言对outlier更加敏感。例如加入使用k=3,当预测点旁有两个错误数据就足以导致预测结果的错误。
缺点3:预测结果不具有可解释性
往往实际应用中我们只知道结果是什么是不够的,我们需要知道为什么是这样的结果从而得到某种规律可以进行推广。
缺点4:维数灾难
随维度的增加,“看似相近”的两个点之间的距离越来越大

解决方法:降维
超参数
指在算法运行前需要决定的参数。
与之相对的模型参数指:算法过程中学习的参数。
KNN算法中没有模型参数,其中K是典型的超参数。
寻找好的超参数:
- 领域知识
- 经验数值
- 实验搜索:尝试测试几组不同的超参数,找到最好的配对
KNN中的其他超参数? -> 距离权重
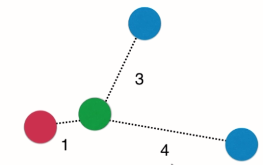

权重一般取距离的倒数。
考虑距离权重的另一个好处:可解决平票问题
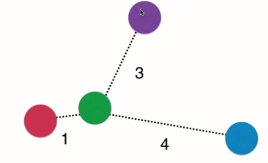
不考虑距离时,红蓝紫平票,模型会随机选一个颜色作为输出结果。但很明显这是不合理的(滑稽脸)。而加入距离权重后,则小红获胜(合情合理有理有据)。
更多的距离定义
之前说到的距离都是欧拉距离。还有一种常见的距离叫曼哈顿距离。
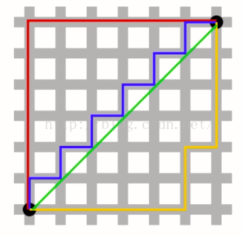
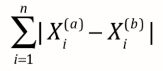
定义为:两点在每个维度上距离的和。如上图例子中黑色两点的曼哈顿距离即它两在x方向上的差值加上y方向上的差值。所有彩线的曼哈顿距离都相同(其中绿线即欧拉距离)
推广一下可发现:
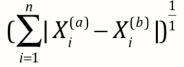 -> 曼哈顿距离
-> 曼哈顿距离
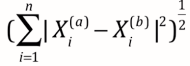 -> 欧拉距离
-> 欧拉距离
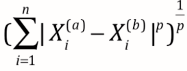 -> 明可夫斯基距离Minkowski distance
-> 明可夫斯基距离Minkowski distance
当p=1时,明可是曼哈顿距离,p=2时,变身成曼哈顿距离,p=其他数,其他距离的表示方式。
【系统提示】叮咚!又获得一个新的超参数,p
由sklearn中叫metric的超参数控制,默认为明可夫斯基距离
- 向量空间余弦相似度 Cosine Similarity
- 调整余弦相似度 Adjusted Cosine Similarity
- 皮尔森相关系数 Pearson Correlation Coefficient
- Jaccard相似系数 Jaccard Coefficient
KNN-K近邻算法(1)的更多相关文章
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- KNN K~近邻算法笔记
K~近邻算法是最简单的机器学习算法.工作原理就是:将新数据的每一个特征与样本集中数据相应的特征进行比較.然后算法提取样本集中特征最相似的数据的分类标签.一般来说.仅仅提取样本数据集中前K个最相似的数据 ...
- KNN (K近邻算法) - 识别手写数字
KNN项目实战——手写数字识别 1. 介绍 k近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法.它的工作原理是:存在一个 ...
- kNN(k近邻)算法代码实现
目标:预测未知数据(或测试数据)X的分类y 批量kNN算法 1.输入一个待预测的X(一维或多维)给训练数据集,计算出训练集X_train中的每一个样本与其的距离 2.找到前k个距离该数据最近的样本-- ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- k近邻算法(KNN)
k近邻算法(KNN) 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. from sklearn.model_selection ...
- 1. K近邻算法(KNN)
1. K近邻算法(KNN) 2. KNN和KdTree算法实现 1. 前言 K近邻法(k-nearest neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用, ...
- 机器学习:k-NN算法(也叫k近邻算法)
一.kNN算法基础 # kNN:k-Nearest Neighboors # 多用于解决分裂问题 1)特点: 是机器学习中唯一一个不需要训练过程的算法,可以别认为是没有模型的算法,也可以认为训练数据集 ...
随机推荐
- vijos1846 [NOIP2013] 华容道【最短路】
传送门:https://vijos.org/p/1983 (其实noip的题各个oj都会有的,就不贴其它传送门了) 这道题真的是,怎么说,我都不知道怎么评价了= =.果然数据量小的题怎么暴力都可以过. ...
- 找规律 Codeforces Round #309 (Div. 2) A. Kyoya and Photobooks
题目传送门 /* 找规律,水 */ #include <cstdio> #include <iostream> #include <algorithm> #incl ...
- magento 获得当前产品页面的产品id
$product_id = Mage::registry('current_product')->getId();
- 32位Oracle10g在64位CentOS下安装失败记录
环境信息:Alibaba Cloud Elastic Compute Service,CentOS Linux release 7.4.1708 (Core),16C/64GB. 使用32位Oracl ...
- spring tool suite开发环境搭建
先把是构建工具maven: maven里面有一个conf文件夹,然后里面有个setting.xml配置文件,先要把项目要的setting.xml覆盖这个原来的配置文件. 这个maven配置文件有一个作 ...
- 179 Largest Number 把数组排成最大的数
给定一个非负整数的列表,重新排列它们的顺序把他们组成一个最大的整数.例如,给定 [3, 30, 34, 5, 9],最大的组成数是 9534330.注意: 结果可能非常大,所以您需要返回一个字符串而不 ...
- Hadoop YARN学习之组件功能简述(3)
Hadoop YARN学习之组件功能简述(3) 1. YARN的三大组件功能简述: ResourceManager(RM)是集群的资源的仲裁者, 它有两部分:一个可插拔的调度器和一个Applicati ...
- spring 配置 shiro rememberMe
1.shiro 提供记住我的功能,当将form表单中name="rememberMe" 的value设为true或者登陆的token中.token.setRememberMe(tr ...
- Python学习 Day 3 字符串 编码 list tuple 循环 dict set
字符串和编码 字符 ASCII Unicode UTF-8 A 1000001 00000000 01000001 1000001 中 x 01001110 00101101 11100100 101 ...
- SQLServer性能优化专题
SQLServer性能优化专题 01.SQLServer性能优化之----强大的文件组----分盘存储(水平分库) http://www.cnblogs.com/dunitian/p/5276431. ...