第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点

No.2. 准备工作,导入类库,准备测试数据

No.3. 构建训练集

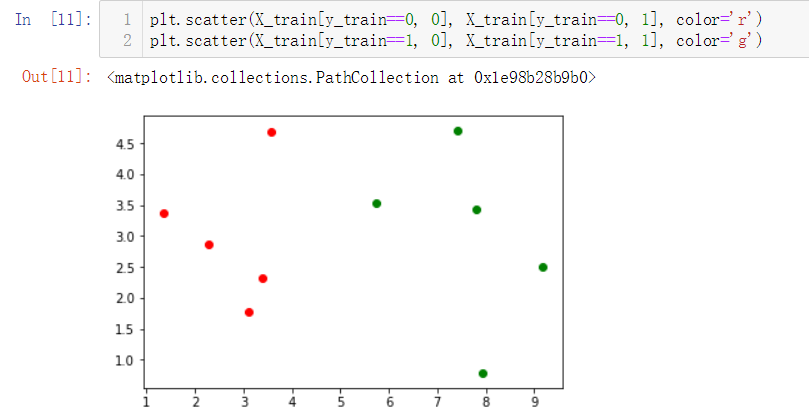
No.4. 简单查看一下训练数据集大概是什么样子,借助散点图

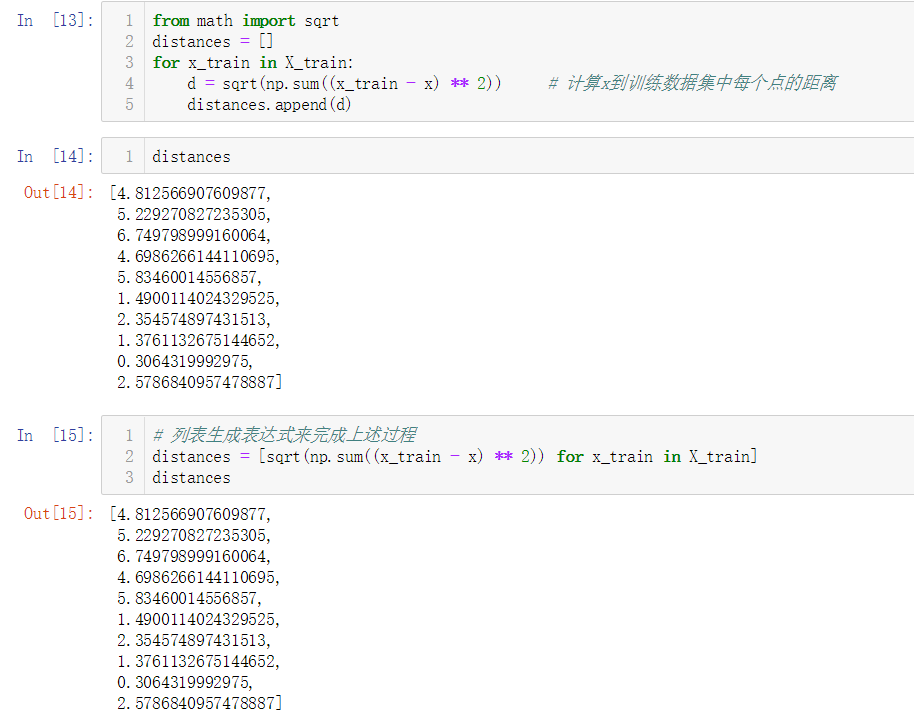
No.6. kNN的实现过程——计算x到训练数据集中每个点的距离
No.7. kNN的实现过程——使用argsort来获取距离x由近到远的点的索引组成的向量,进行保存

No.8. kNN的实现过程——指定需要考虑的最近的点的个数k,并获取距离x最近的k个点的y_train中的数据

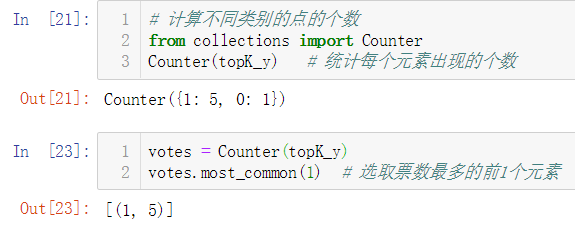
No.9. kNN的实现过程——统计出属于不同类别的点的个数,并选择票数最多的类别
No.10. kNN的实现过程——对预测结果进行保存,结束。

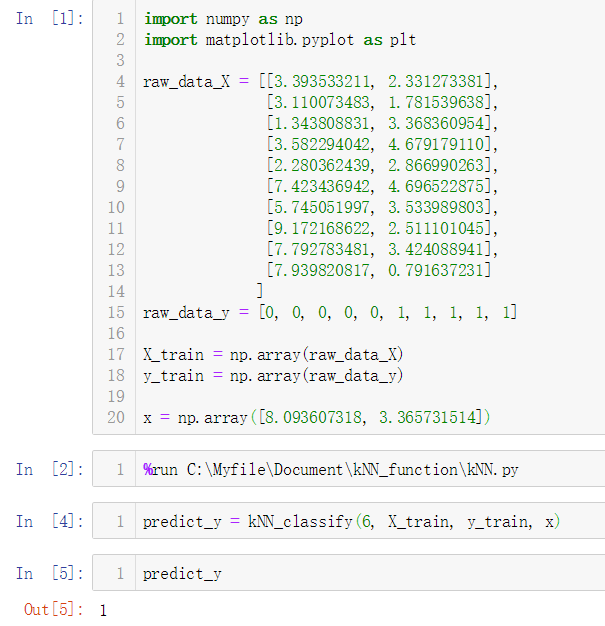
No.11. 我们可以将kNN算法封装到一个函数中

No.12. 然后我们处理好测试数据,直接调用这个封装好的函数,就能得到预测结果
No.13. 机器学习的一般流程

No.14. k-近邻算法的特殊性

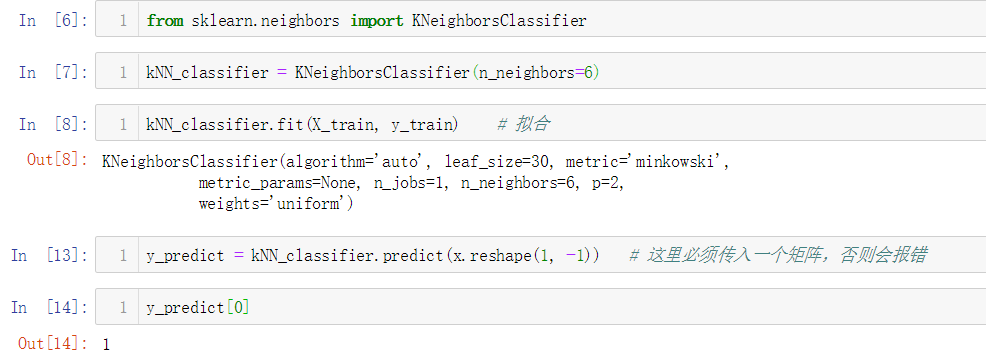
No.15. 使用scikit-learn中的kNN算法
No.16. 模仿scikit-learn封装自己的KNNClassifier类

No.17. 调用自己封装的KNNClassifier类

- 缺点1:效率低下,这也是kNN算法的最大缺点,如果训练数据集有m个样本,n个特征,则预测一个新数据的时间复杂度为O(m*n)
- 缺点2:高度数据相关,容易导致预测出错
- 缺点3:预测结果不具有可解释性
- 缺点4:维数灾难,随着维数的增加,原本看似很近的两个点的距离会越来越大

第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)的更多相关文章
- 第四十九篇 入门机器学习——数据归一化(Feature Scaling)
No.1. 数据归一化的目的 数据归一化的目的,就是将数据的所有特征都映射到同一尺度上,这样可以避免由于量纲的不同使数据的某些特征形成主导作用. No.2. 数据归一化的方法 数据归一化的方法主要 ...
- 第四十二篇 入门机器学习——Numpy的基本操作——索引相关
No.1. 使用np.argmin和np.argmax来获取向量元素中最小值和最大值的索引 No.2. 使用np.random.shuffle将向量中的元素顺序打乱,操作后,原向量发生改变:使用np. ...
- 第三十六篇 入门机器学习——Jupyter Notebook中的魔法命令
No.1.魔法命令的基本形式是:%命令 No.2.运行脚本文件的命令:%run %run 脚本文件的地址 %run C:\Users\Jie\Desktop\hello.py # 脚本一旦 ...
- Python之路(第四十六篇)多种方法实现python线程池(threadpool模块\multiprocessing.dummy模块\concurrent.futures模块)
一.线程池 很久(python2.6)之前python没有官方的线程池模块,只有第三方的threadpool模块, 之后再python2.6加入了multiprocessing.dummy 作为可以使 ...
- Jmeter(四十六) - 从入门到精通高级篇 - Jmeter之网页图片爬虫-下篇(详解教程)
1.简介 上一篇介绍了爬取文章,这一篇宏哥就简单的介绍一下,如何爬取图片然后保存到本地电脑中.网上很多漂亮的壁纸或者是美女.妹子,想自己收藏一些,挨个保存太费时间,那你可以利用爬虫然后批量下载. 2. ...
- 第四十六篇、UICollectionView广告轮播控件
这是利用人的视觉错觉来实现无限轮播,UICollectionView 有很好的重用机制,这只是部分核心代码,后期还要继续完善和代码重构. #import <UIKit/UIKit.h> # ...
- 第四十六篇--解析和保存xml文件
新建assets资源文件夹,右键app --> new --> Folder --> Assets Folder,将info.xml放入此文件夹下面. info.xml <?x ...
- 第三十九篇 入门机器学习——Numpy.array的基础操作——合并与分割向量和矩阵
No.1. 初始化状态 No.2. 合并多个向量为一个向量 No.3. 合并多个矩阵为一个矩阵 No.4. 借助vstack和hstack实现矩阵与向量的快速合并.或多个矩阵快速合并 No.5. 分割 ...
- 第三十八篇 入门机器学习——Numpy.array的基本操作——查看向量或矩阵
No.1. 初始化状态 No.2. 通过ndim来查看数组维数,向量是一维数组,矩阵是二维数组 No.3. 通过shape来查看向量中元素的个数或矩阵中的行列数 No.4. 通过size来查看数组中的 ...
随机推荐
- Spark学习之路 (二十)SparkSQL的元数据[转]
概述 SparkSQL 的元数据的状态有两种: 1.in_memory,用完了元数据也就丢了 2.hive , 通过hive去保存的,也就是说,hive的元数据存在哪儿,它的元数据也就存在哪儿. 换句 ...
- git项目分支管理
分支管理 创建项目时,会针对不同环境创建两个常设分支(也可以算主分支,永久不会删除): master :生产环境的稳定分支,生产环境基于该分支构建.仅用来发布新版本,除了从 release 测试分支或 ...
- 2019kali中文乱码
1.安装KALI2019.4版本后会出现乱码问题 2.更新国内源,使用vim编辑器修改:vim /etc/apt/sources.list添加 #清华大学 [更新源] deb https://m ...
- Matrix Sum HihoCoder - 1336 二维树状数组 感觉好像二维差分。
#include<cstdio> #include<cstring> using namespace std; typedef long long ll; ; ; ll c[N ...
- vue必须掌握之组件通信(7种方法)
方法一:$emit / props 父组件通过props的方式向子组件传递,子组件通过$emit触发父组件中v-on绑定的自定义事件 <!--父组件--> <template> ...
- Qt 程序打包发布总结 转
1. 概述 当我们用QT写好了一个软件,要把你的程序分享出去的时候,不可能把编译的目录拷贝给别人去运行.编译好的程序应该是一个主程序,加一些资源文件,再加一些动态链接库,高大上一些的还可以做一个安装 ...
- mac屏幕录制
屏幕录制 shift+command+5 录制完成后将文件拖拽到要保存的文件中
- Linux -初体验笔记
课堂笔记 鸟哥Linux私房菜 Linux 版本很多,内核都是一样的 计算机基础知识: 1.完整计算机系统:软件+硬件 硬件:物理装置本身,计算机的物质基础 软件:相对硬件而言, 程序:计算机完成一项 ...
- linux 安装 Django
安装django的命令 pip install Django ## 这样运行默认安装的是最新版 备注 根据测试在python3.4基础上安装Django 1.8.9正式版是没有问题的,所以要执行下面命 ...
- HBuilderX开发app实现自动更新版本
需求说明:使用MUI+Vue等技术并且通过HBuilderX打包开发移动app,在有版本更新时需要自动提示用户有新版本,并且可以点击下载自动安装. 思路说明: 应用打开时(使用Vue的生命周期mo ...