Spark角色介绍及spark-shell的基本使用
Spark角色介绍
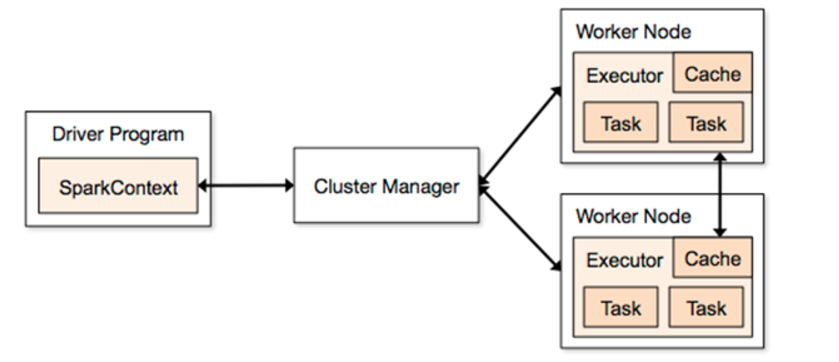
1、Driver
它会运行客户端的main方法,构建了SparkContext对象,它是所有spark程序的入口
2、Application
它就是一个应用程序,包括了Driver端的代码和当前这个任务在运行的时候需要的资源信息
3、Master
它是整个spark集群的老大,负责资源的分配
4、ClusterManager
它是一个可以给任务提供资源的外部服务
standAlone
spark自带的集群模式,整个任务的资源分配由Master负责
yarn
spark可以把程序提交到yarn中去运行,整个任务的资源分配由ResourceManager负责
mesos
它是一个apache开源的类似于yarn的资源管理平台
5、Worker
它是整个spark集群的小弟,任务最后会运行在worker节点
6、Executor
它是一个进程,任务最后会运行在worker节点的executor进程中。
7、task
它是一个线程,spark的任务是以线程的方式运行在worker节点的executor进程中。
spark-shell的使用
1、通过spark-shell --master local[N] 读取本地数据文件实现单词统计
--master local[N]
local表示本地运行,跟spark集群没有任何关系,方便于我们做测试
N表示一个正整数,在这里local[N] 就是表示本地采用N个线程去运行任务
它会产生一个SparkSubmit进程
spark-shell --master local[2]
sc.textFile("file:///root/words.txt").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y).collect sc.textFile("file:///root/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
2、通过spark-shell --master local[N] 读取HDFS上数据文件实现单词统计
#spark整合HDFS
vim spark-env.sh #引入hadoop中配置文件路径
export HADOOP_CONF_DIR=/export/servers/hadoop/etc/hadoop
spark-shell --master local[2]
sc.textFile("hdfs://node1:9000/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
sc.textFile("/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
3、通过spark-shell 指定master为整个spark集群中alive的master地址
spark-shell --master spark://node1:7077 --executor-memory 1g --total-executor-cores 2
sc.textFile("/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
使用spark-submit提交jar包任务到集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node1:7077,node2:7077,node3:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
examples/jars/spark-examples_2.11-2.1.3.jar \
10
Spark角色介绍及spark-shell的基本使用的更多相关文章
- 2 Spark角色介绍及运行模式
第2章 Spark角色介绍及运行模式 2.1 集群角色 从物理部署层面上来看,Spark主要分为两种类型的节点,Master节点和Worker节点:Master节点主要运行集群管理器的中心化部分,所承 ...
- Spark概念介绍
Spark概念介绍:spark应用程序在集群中以一系列独立的线程运行,通过驱动器程序(Driver Program)发起一系列的并行操作.SparkContext对象作为中间的连接对象,通过Spark ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- spark API 介绍链接
spark API介绍: http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html#aggregateByKey
- Spark记录-spark编程介绍
Spark核心编程 Spark 核心是整个项目的基础.它提供了分布式任务调度,调度和基本的 I/O 功能.Spark 使用一种称为RDD(弹性分布式数据集)一个专门的基础数据结构,是整个机器分区数据的 ...
- Spark(二) -- Spark简单介绍
spark是什么? spark开源的类Hadoop MapReduce的通用的并行计算框架 spark基于map reduce算法实现的分布式计算 拥有Hadoop MapReduce所具有的优点 但 ...
- Spark MLlib介绍
Spark MLlib介绍 Spark之所以在机器学习方面具有得天独厚的优势,有以下几点原因: (1)机器学习算法一般都有很多个步骤迭代计算的过程,机器学习的计算需要在多次迭代后获得足够小的误差或者足 ...
- Apache Spark简单介绍、安装及使用
Apache Spark简介 Apache Spark是一个高速的通用型计算引擎,用来实现分布式的大规模数据的处理任务. 分布式的处理方式可以使以前单台计算机面对大规模数据时处理不了的情况成为可能. ...
- spark相关介绍-提取hive表(一)
本文环境说明 centos服务器 jupyter的scala核spylon-kernel spark-2.4.0 scala-2.11.12 hadoop-2.6.0 本文主要内容 spark读取hi ...
随机推荐
- luvit 被忽视的lua 高性能框架(仿nodejs)
备注: luvit 开放模式和nodejs 一样,但是因为生态以及小众语言的问题,使用的人比较少,但是从目前 来看更新速度还是比较快的,但是从现有lua 开发框架来说一般倾向于使 ...
- caddy server 几个常用插件
1.log日志 log /var/www/log/example.log 2.目录访问 browse 3.gzip压缩 gzip 4.自主ssl证书 tls /path/ssl/exa ...
- filter异常捕捉
jsp中抛出一个异常 <% String action = request.getParameter("action"); if ("accountExceptio ...
- UOJ #54 时空穿梭 —— 计数+莫比乌斯反演+多项式系数
题目:http://uoj.ac/problem/54 10分还要用 Lucas 定理囧...因为模数太小了不能直接算... #include<cstdio> #include<cs ...
- Spring入门一----HelloWorld
知识点: 简介 HelloWorld 简介: 百度百科 HelloWorld 项目结构图: 导入Spring支持包: 然后选中所有包,右键Build Path à Add to Buil ...
- 基于INTEL FPGA硬浮点DSP实现卷积运算
概述 卷积是一种线性运算,其本质是滑动平均思想,广泛应用于图像滤波.而随着人工智能及深度学习的发展,卷积也在神经网络中发挥重要的作用,如卷积神经网络.本参考设计主要介绍如何基于INTEL 硬浮点的DS ...
- GOF23设计模式之适配器模式(Adapter)
一.适配器模式概述 将一个类的接口转换成客户可用的另外一个接口. 将原本不兼容不能在一起工作的类添加适配处理类,使其可以在一起工作. 二.适配器模式场景 要想只有USB接口的电脑想使用PS/2接口的键 ...
- 第三章:Hadoop简介及配置Hadoop-1.2.1,hbase-0.94.13集群
前面给大家讲了怎么安装Hadoop,肯定会有人还是很迷茫,装完以后原来就是这个样子,但是怎么用,下面,先给大家讲下Hadoop简介:大致理解下就OK了 hadoop是一个平台,提供了庞大的存储和并行计 ...
- 前端性能优化:gzip压缩文件传输数据
一.文件压缩的好处 前端生产环境中将js.css.图片等文件进行压缩的好处显而易见,通过减少数据传输量减小传输时间,节省服务器网络带宽,提高前端性能. 二.http协议如何支持压缩文件的传输 1.浏览 ...
- javaweb地图定位demo
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/stri ...