Spark角色介绍及spark-shell的基本使用
Spark角色介绍
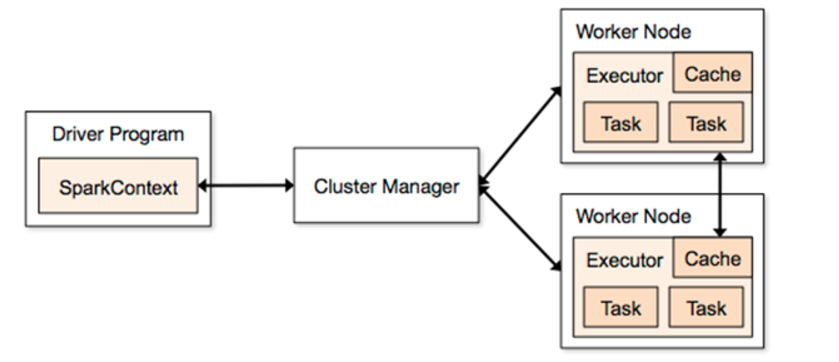
1、Driver
它会运行客户端的main方法,构建了SparkContext对象,它是所有spark程序的入口
2、Application
它就是一个应用程序,包括了Driver端的代码和当前这个任务在运行的时候需要的资源信息
3、Master
它是整个spark集群的老大,负责资源的分配
4、ClusterManager
它是一个可以给任务提供资源的外部服务
standAlone
spark自带的集群模式,整个任务的资源分配由Master负责
yarn
spark可以把程序提交到yarn中去运行,整个任务的资源分配由ResourceManager负责
mesos
它是一个apache开源的类似于yarn的资源管理平台
5、Worker
它是整个spark集群的小弟,任务最后会运行在worker节点
6、Executor
它是一个进程,任务最后会运行在worker节点的executor进程中。
7、task
它是一个线程,spark的任务是以线程的方式运行在worker节点的executor进程中。
spark-shell的使用
1、通过spark-shell --master local[N] 读取本地数据文件实现单词统计
--master local[N]
local表示本地运行,跟spark集群没有任何关系,方便于我们做测试
N表示一个正整数,在这里local[N] 就是表示本地采用N个线程去运行任务
它会产生一个SparkSubmit进程
spark-shell --master local[2]
sc.textFile("file:///root/words.txt").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y).collect sc.textFile("file:///root/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
2、通过spark-shell --master local[N] 读取HDFS上数据文件实现单词统计
#spark整合HDFS
vim spark-env.sh #引入hadoop中配置文件路径
export HADOOP_CONF_DIR=/export/servers/hadoop/etc/hadoop
spark-shell --master local[2]
sc.textFile("hdfs://node1:9000/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
sc.textFile("/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
3、通过spark-shell 指定master为整个spark集群中alive的master地址
spark-shell --master spark://node1:7077 --executor-memory 1g --total-executor-cores 2
sc.textFile("/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
使用spark-submit提交jar包任务到集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node1:7077,node2:7077,node3:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
examples/jars/spark-examples_2.11-2.1.3.jar \
10
Spark角色介绍及spark-shell的基本使用的更多相关文章
- 2 Spark角色介绍及运行模式
第2章 Spark角色介绍及运行模式 2.1 集群角色 从物理部署层面上来看,Spark主要分为两种类型的节点,Master节点和Worker节点:Master节点主要运行集群管理器的中心化部分,所承 ...
- Spark概念介绍
Spark概念介绍:spark应用程序在集群中以一系列独立的线程运行,通过驱动器程序(Driver Program)发起一系列的并行操作.SparkContext对象作为中间的连接对象,通过Spark ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- spark API 介绍链接
spark API介绍: http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html#aggregateByKey
- Spark记录-spark编程介绍
Spark核心编程 Spark 核心是整个项目的基础.它提供了分布式任务调度,调度和基本的 I/O 功能.Spark 使用一种称为RDD(弹性分布式数据集)一个专门的基础数据结构,是整个机器分区数据的 ...
- Spark(二) -- Spark简单介绍
spark是什么? spark开源的类Hadoop MapReduce的通用的并行计算框架 spark基于map reduce算法实现的分布式计算 拥有Hadoop MapReduce所具有的优点 但 ...
- Spark MLlib介绍
Spark MLlib介绍 Spark之所以在机器学习方面具有得天独厚的优势,有以下几点原因: (1)机器学习算法一般都有很多个步骤迭代计算的过程,机器学习的计算需要在多次迭代后获得足够小的误差或者足 ...
- Apache Spark简单介绍、安装及使用
Apache Spark简介 Apache Spark是一个高速的通用型计算引擎,用来实现分布式的大规模数据的处理任务. 分布式的处理方式可以使以前单台计算机面对大规模数据时处理不了的情况成为可能. ...
- spark相关介绍-提取hive表(一)
本文环境说明 centos服务器 jupyter的scala核spylon-kernel spark-2.4.0 scala-2.11.12 hadoop-2.6.0 本文主要内容 spark读取hi ...
随机推荐
- python: delete the duplicates in a list
下面有几种做法, 其中3之简洁令人惊讶. 1, >>> t = [1, 2, 3, 1, 2, 5, 6, 7, 8] >>> t [1, 2, 3, 1, 2, ...
- maven docker plugin 常见问题解决
1. maven 项目必须使用小写,不然会一直有500 的错误 500: HTTP 500InternalServerError 2. docker server 连接数超了 Fail ...
- JavaSE 手写 Web 服务器(一)
原文地址:JavaSE 手写 Web 服务器(一) 博客地址:http://www.extlight.com 一.背景 某日,在 Java 技术群中看到网友讨论 tomcat 容器相关内容,然后想到自 ...
- 在ng中的select的使用方法的讲解
项目中我们可能会使用到条件过滤选择框之类的东西,最简单的就是input.select. 关于select的使用我们通常会需要从数据库中返回数据进行动态绑定. 此时我们会有两种方式: 1)使用ng-re ...
- centos7下安装docker 17.x
docker的17.X版本与以前的docker安装有些不同,参考了下这篇文章http://www.itmuch.com/docker/docker-2/,以下是我的docker 17.X版本安装过程, ...
- python 线程/进程模块
线程的基本使用: import threading # ###################### 1.线程的基本使用 def func(arg): print(arg) t = threading ...
- Java-Runoob-高级教程:Java 泛型
ylbtech-Java-Runoob-高级教程:Java 泛型 1.返回顶部 1. Java 泛型 Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检 ...
- Zabbix 添加 WEB 监控
添加 WEB Monitorings Web Monitoring是用来监控web程序的,可以监控到web程序的下载速度.返回码及响应时间,还支持把一组连续的web动作作为一个整体来监控. 下面我们以 ...
- 安装windows 2003 server
最近去给客户安装windows 2003 server,想想也是技术,就写出来了,我这个实在虚拟机安装的,安装这个系统主要是为了安装limesurvey问卷系统 第一步:安装,选择Enter 第二步: ...
- Go - 开始
学习Go的缘由 由于LZ目前在使用docker,docker的编程语言使用的是“Go”,所以想更加深入的了解Docker(尝试着看懂source code)遂尝试了解下Golang. 安装 LZ用的是 ...