(My)SQL
1.SQL语句分类
- DDL(Data Definition Languages)语句:用来创建 删除 修改数据库、表、列、索引等数据库对象。常用的语句关键字主要包括create、drop、alter等。
- DML(Data Manipulation Language)语句:数据操纵语句,对数据库表中的数据进行添加、删除、更新和查询,并检查数据完整性。常用的语句关键字主要包括insert、delete、update和select等。
- DCL(Data Control Language)语句:数据控制语句,用于控制不同数据段直接的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括grant、revoke等。
2.DDL语句
和数据库相关
- 创建数据库 CREATE DATABASE db_name; (SQL语句可以 ; 作为结束标志也可以使用 \g 作为结束标志。)
- 删除数据库 DROP DATABASE db_name;
- 使用数据库 USE db_name;
- 显示所有数据库 SHOW DATABASES;
- 显示当前数据库所有表 SHOW TABLES;
和表相关
- 创建表: CREATE TABLE t_name( col_name col_TYPE . . .);
- 删除表:DROP TABLE t_name;
- 查询表定义: DESC t_name;
- 查询表定义的SQL语句:SHOW CREATE TABLE t_naem;
- AS : 为表或者字段添加别名, 不使用as 直接在表名或者字段名后面一个空格 和 别名也是可以的。
修改表:ALTER
- 中括号表示其中的元素可有可无。
- 可以指定修改后的位置,FIRST 表示第一列, AFTER col_name 表示在某列之后。
- MODIFY 修改表字段类型
- 如varchar(10)改为varchar(20) : ALTER TABLE t_name MODIFY [COLUMN] col_naem varchar(20) [FIRST|AFTER col_name];
- 默认位置不变。
- ADD 添加表字段
- ALTER TABLE t_name ADD [COLUMN]con_name int(3) [FIRST|AFTER col_name];
- 默认添加在最后。
- DROP删除字段
- ALTER TABLE t_name DROP [COLUMN] col_name;
- CHANGE 可以用来修改字段名称
- ALTER TABLE t_name CHANGE [COLUMN] old_col_name new_col_naem TYPE [FIRST|AFTER col_name];
- 默认位置不变。
- RENAME 修改表名
- ALTER TABLE t_name RENAME [TO] new_t_name;
- MODIFY 与 CHANGE 都可以修改字段类型(CHANGE 需要写2遍列名,不方便),但是 CHANGE优点就是可以修改字段名称。
- CHANGE/FIRST|AFTER COLUMN这些关键字都属于MySQL在标准SQL上的扩展,在其他数据库上不一定适用。
- MODIFY 修改表字段类型
3.DML语句
- INSERT 插入数据
- INSERT INTO tablename (field1,field2,…,fieldn) VALUES(value1,value2,…,valuen);
- 自增,设有默认值,可以为NULL的字段,可以不出现在 字段列表中,但要始终保持字段列表和值列表一一对应。
- 也可以不用指定字段名称,但是values后面的顺序应该和字段的排列顺序一致,如果有自增字段值应该对应写 ''(空字符)。
--如插入数据 id(自增),年龄,性别
INSERT INTO t_name values('', 20, 'man') - INSERT 可以一次性插入多条数据,插入值之间用“ , ”分割。 这个特性可以使得MySQL在插入大量数据时节省很多的网络开销,大大提高插入效率。
INSERT INTO emp(name,age) VALUES('孙悟空',100),('猪八戒',100),('唐三藏',100) - INSERT INTO t1_name SELECT .... FROM t2_naem ....
- 要求t1表必须存在。
- 从t2表中查找出数据插入t1表中,值类型需要相符,但是如果值是数字或者null那么int 和 varchar 可以互。
- 也可以简单赋值,如emp只有一个字段int 或者 varchar :INSERT INTO emp select 20;
- 还有一种插入数据方法 SELECT * into t2 from t1; 这要求T2不存在并且会创建t2表,但是MySQL不支持这种写法。
- UPDATE 更新数据
- UPDATE t_name SET field1 = valve1, field2 = value2 [WHERE 条件];
- 没有 where条件 就会把所有值设为相同值。
- 一次更新多个表中的记录
update emp a,dept b
set
a.sal=a.sal*b.deptno,
b.deptname=a.ename
wherea.deptno=b.deptno;注意别名的用法:设置别名就是为了便捷,所以选择表时如果设置了别名之后使用时就用别名,如果不用别名有时会出现SQL语句错误。
- DELETE 删除记录
- 删除单个表中某行记录 :DELETE FROM t_naem [WHERE 条件];
- 删除多个表中的记录:如果FROM 后面表加了别名那么FROM必须要用表的别名。
DELETE t1,tt,t3 FROM,t2 tt ,t3 [WHERE 条件];
- 没有where条件会将整个表清空,所以where条件很重要。
- SELECT 查询记录
- 最基本语法 SELECT * FROM t_name [WHERE 条件];
4.查询数据
- 对于查询处理,可将其分为逻辑查询处理及物理查询处理。逻辑查询处理表示执行查询应该产生什么样的结果,而物理查询代表MySQL数据库是如何得到该结果的。两种查询的方法可能完全不同,但是得到的结果必定是相同的。
- 在SQL语言逻辑查询中,第一个被处理的子句总是FROM子句,查询顺序如下图
 (摘自 《MySQL技术内幕:SQL编程》)
(摘自 《MySQL技术内幕:SQL编程》)
FROM 做笛卡尔积
- 如果有 JOIN 则首先对FROM子句中的左表<left_table>和右表<right_table>做笛卡儿积,产生虚拟表VT1。再执行 2。
- 如果没有 JOIN 即不做表连接,则对FROM后面的表做笛卡尔积。执行4。
ON 对JOIN后的结果过滤
- JOIN 分为 内连接 [INNER] JOIN 和 外连接 [OUTER] JOIN
- 外连接 又分为:LEFT [OUTER] JOIN 和 RIGHT [OUTER] JOIN
- 只有JOIN 左右最近的一个表才是左表右表生成VT1,这两个表会执行ON条件,所以ON中只能出现这两个表的字段,其他表中的字段不在VT1中所以不能出现在ON中。
- 对于符合条件的行会标志认为TRUE,不符合条件的行标志位FALSE。
- 对于等号一边的一个条件对应值NULL,则标记为FALSE,如果2个条件都为NULL,则标记为UNKNOWN, UNKNOWN也被当做FALSE处理。
- ON对2个NULL的处理和 ORDER BY 、GROUP BY不同,ORDER BY 会把所有NULL值分到同一组,GROUP BY会认为他们是不同的排列在一起。
- 对虚拟表VT1应用ON筛选,只有那些符合<join_condition>也就是被标注为TRUE的行才被插入虚拟表VT2中。
- ON 只对JOIN的表过滤,没有JOIN是不能使用ON过滤的。
- SELECT查询一共有3个过滤过程,分别是ON、WHERE、HAVING。ON是最先执行的过滤过程。
OUTER JOIN 以某一张表为基表保留 进行相关查询
- 只有外连接才会执行这一步
- 如果指定了OUTER JOIN(如LEFT [OUTER] JOIN、RIGHT [OUTER] JOIN),那么保留表中未匹配的行作为外部行添加到虚拟表VT2中,产生虚拟表VT3。
- 如果需要连接表的数量大于2,则对上一个连接生成的结果表VT3和下一个表重复执行步骤1)~步骤3),直到处理完所有的表为止。
SELECT *
FROM customers AS c
LEFT JOIN orders AS o
ON c.customer_id = o.customer_id
RIGHT JOIN emp
ON emp.age=20; WHERE 条件查询
- where后面的条件可以使用=,除了=外,还可以使用>、<、>=、<=、!=等比较运算符;
- 多个条件之间还可以使用or、and等逻辑运算符进行多条件联合查询。
- 外连接下ON会保留基表被过滤的行,而WHERE则不会保留,内连接ON 和WHERE作用一样。
- 由于数据还没有分组,因此现在还不能在WHERE过滤器中使用 统计类函数。
- 因为WHERE 在SELECT 之前执行,所以在SELECT 中设定的字段别名在WHERE中时不能使用的,同样的道理FROM 最先执行所以FROM设定的表的别名在任何地方都能使用。
SELECT NAME,age 年龄
FROM emp e
WHERE e.age=20;
GROUP BY
- 分组的目的就是为了使用 统计类函数。
- GROUP BY 还有一个作用就是去重,它只会返回一组的一个值。
- 根据GROUP BY子句中的列,对VT4中的记录进行分组操作,产生VT5。
- 根据要分组的列判断是否为同一组。 单列就比较此列,多列就要多列都相同才认为同一组。
- GROUP BY默认会根据该字段排序,相当于执行了一次ORDER BY...ASC 。
CUBE|ROLLUP
- 对表VT5进行CUBE或ROLLUP操作,产生表VT6,使用CULB和ROLLUP要加上WITH 。
- MySQL数据库虽然支持该关键字CUBE的解析,但是并未实现该功能。
- 如果指定了ROLLUP选项,那么将创建一个额外的记录添加到虚拟表VT5的最后,并生成虚拟表VT6。
- ROLLUP是根据维度在数据结果集中进行的聚合操作,他和GROUP BY 的列息息相关。
- 聚合操作就是对某一项所有不同数据进行统计,而维度就是要聚合项的数量。
- WITH ROLLUP,在分组的统计数据的基础上再进行相同的统计(SUM,AVG,COUNT…),而其他字段为null,可以根据这个特定判断是对象还是统计结果。
SELECT empid,custid, YEAR(orderdate) YEAR, SUM(qty) SUM
FROM t
GROUP BY empid,custid,YEAR(orderdate)
WITH ROLLUP;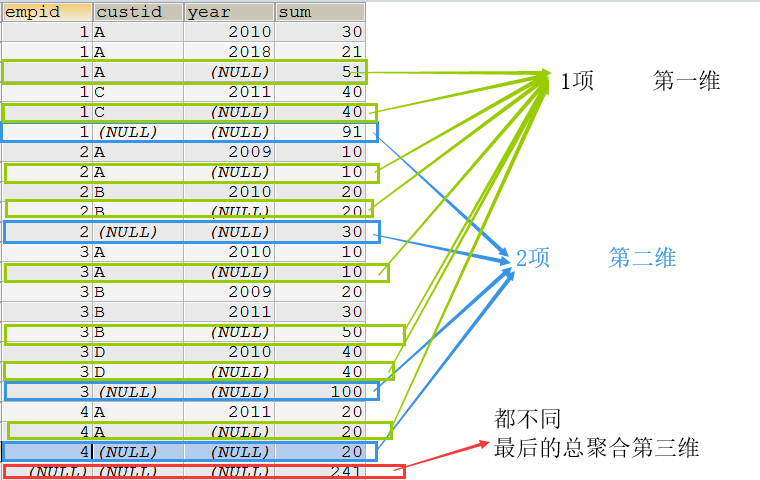
- 如果分组的列包含NULL值,那么ROLLUP的结果可能是不正确的,因为在ROLLUP中进行分组统计时值NULL具有特殊意义。因此在进行ROLLUP操作时,可以先将NULL值转换为一个不可能存在的值,或者没有特别含义的值,例如:IFNULL(XXX, 0)
IFNULL函数是MySQL控制流函数之一,它接受两个参数,如果不是NULL,则返回第一个参数。 否则,IFNULL函数返回第二个参数。
HAVING
- 对虚拟表VT6应用HAVING过滤器,只有符合<having_condition>的记录才被插入虚拟表VT7中
- 分组后对分组进行过滤,过滤条件一般是判断聚合函数的值
- 需要特别注意的是,过滤函数中不能使用COUNT(1)或COUNT(*),因为这会把通过OUTER JOIN添加的行统计入内而导致最终查询结果与预期结果不同。
- COUNT(id) 要使用具体的列。
SELECT
- 选择指定的列,插入到虚拟表VT8中。
DISTINCT查询不重复的记录
- SELECT DISTINCT name FROM t_name; 它会返回所有不同的name
- SELECT DISTINCT id,name FROM t_name; 只有2条记录的id和name都相同才会被去除。
- SELECT id,DISTINCT name FROM t_name; 这样是非法的,DISTINCT只能用在所有字段的最前面。
- 所以DISTINCT无法做到 只对某一字段去重 同时显示其他内容。
- DISTINCT一般用来记录 不重复的记录数量SELECT COUNT(DISTINCT naem) FROM t_name;
- GROUP BY 之后使用DISTINCT 无意义,因为GROUP BY也会去重。
ORDER BY排序
- 用来对查询结果排序
SELECT*FROM tablename [WHERE CONDITION] [ORDER BYfield1 [DESC|ASC],field2 [DESC|ASC],…,fieldn [DESC|ASC]]
- ASC 代表升序,第一行最小,最后一行最大,DESC 代表降序,第一行最大,最后一行最小。默认升序。
- 可以对多个字段排序,且可以使用不同的排序规则,如果第一个字段有相同的则会根据第二个字段排序。
- 不要为表中的行假定任何特定的顺序。就是说,在实际使用环境中,如果确实需要有序输出行记录,则必须使用ORDER BY子句。
- 因为没有ORDER BY子句的查询只代表从集合中查询数据,而集合是没有顺序概念的。
- 在ORDER BY子句中,NULL值被认为是相同的值,会将其排序在一起。在MySQL数据库中,NULL值在升序过程中总是首先被选出,即NULL值在ORDER BY子句中最小的。
- WITH ROLLUP与ORDER BY相互排斥,不能同时使用。
ORDER BY子句中指定SELECT列表中列的序列号,如下面的语句:
SELECT order_id,customer_id
FROM orders
ORDER BY 2,1; -- 等同于:
SELECT order_id,customer_id
FROM orders
ORDER BY customer_id,order_id;
- 用来对查询结果排序
LIMIT限制
- LIMIT 是最后一个执行的条件。
- LIMIT start ,count : start 是起始位置, count 是数量而不是结束位置,可以不写 start 默认是0 ,如 从第3条开始选10条记录 :limit 3,10;
5.物理查询
- 数据库引擎不会按照逻辑查询那样去一步一步执行,它有大量优化操作,但最终结果和逻辑查询是一样的。
- 比如 索引的使用就避免的 笛卡尔积 的产生,大大缩短了运行时间。
6.子查询
(My)SQL的更多相关文章
- (二)SQL Server分区创建过程
虽然分区有很多好处(一)SQL Server分区详解Partition,却不能随意使用:且不说分区管理的繁琐,只是跨分区带来的负面影响就需要我们好好分析是否有必要使用分区.一般分区创建的业务特点:用于 ...
- Java程序员从笨鸟到菜鸟之(一百零二)sql注入攻击详解(三)sql注入解决办法
sql注入攻击详解(二)sql注入过程详解 sql注入攻击详解(一)sql注入原理详解 我们了解了sql注入原理和sql注入过程,今天我们就来了解一下sql注入的解决办法.怎么来解决和防范sql注入, ...
- Java程序员从笨鸟到菜鸟之(一百)sql注入攻击详解(一)sql注入原理详解
前段时间,在很多博客和微博中暴漏出了12306铁道部网站的一些漏洞,作为这么大的一个项目,要说有漏洞也不是没可能,但其漏洞确是一些菜鸟级程序员才会犯的错误.其实sql注入漏洞就是一个.作为一个菜鸟小程 ...
- 人人都是 DBA(VIII)SQL Server 页存储结构
当在 SQL Server 数据库中创建一张表时,会在多张系统基础表中插入所创建表的信息,用于管理该表.通过目录视图 sys.tables, sys.columns, sys.indexes 可以查看 ...
- 人人都是 DBA(VI)SQL Server 事务日志
SQL Server 的数据库引擎通过事务服务(Transaction Services)提供事务的 ACID 属性支持.ACID 属性包括: 原子性(Atomicity) 一致性(Consisten ...
- 人人都是 DBA(V)SQL Server 数据库文件
SQL Server 数据库安装后会包含 4 个默认系统数据库:master, model, msdb, tempdb. SELECT [name] ,database_id ,suser_sname ...
- 人人都是 DBA(IV)SQL Server 内存管理
SQL Server 的内存管理是一个庞大的主题,涉及特别多的概念和技术,例如常见的 Plan Cache.Buffer Pool.Memory Clerks 等.本文仅是管中窥豹,描述常见的内存管理 ...
- 人人都是 DBA(III)SQL Server 调度器
在 SQL Server 中,当数据库启动后,SQL Server 会为每个物理 CPU(包括 Physical CPU 和 Hyperthreaded)创建一个对应的任务调度器(Scheduler) ...
- 人人都是 DBA(II)SQL Server 元数据
SQL Server 中维护了一组表用于存储 SQL Server 中所有的对象.数据类型.约束条件.配置选项.可用资源等信息,这些信息称为元数据信息(Metadata),而这些表称为系统基础表(Sy ...
- 人人都是 DBA(I)SQL Server 体系结构
在了解 SQL Server 数据库时,可以先从数据库的体系结构来观察.SQL Server 的体系结构中包含 4 个主要组成部分: 协议层(Protocols) 关系引擎(Relational En ...
随机推荐
- 洛谷 P4093 [HEOI2016/TJOI2016]序列 解题报告
P4093 [HEOI2016/TJOI2016]序列 题目描述 佳媛姐姐过生日的时候,她的小伙伴从某宝上买了一个有趣的玩具送给他.玩具上有一个数列,数列中某些项的值可能会变化,但同一个时刻最多只有一 ...
- SQL通用优化方案(where优化、索引优化、分页优化、事务优化、临时表优化)
SQL通用优化方案:1. 使用参数化查询:防止SQL注入,预编译SQL命令提高效率2. 去掉不必要的查询和搜索字段:其实在项目的实际应用中,很多查询条件是可有可无的,能从源头上避免的多余功能尽量砍掉, ...
- apk文件签名绕过
声明: 1.本文转载自:http://www.2cto.com/Article/201311/256406.html,为了留作日后参考上传博客 2.如有转载请复试上面连接,尊重原创 apk文件签名绕过 ...
- 2017北京国庆刷题Day7 afternoon
期望得分:100+30+100=230 实际得分:60+30+100=190 排序去重 固定右端点,左端点单调不减 考场上用了二分,没去重,60 #include<cstdio> #inc ...
- Codeforces 797 D. Broken BST
D. Broken BST http://codeforces.com/problemset/problem/797/D time limit per test 1 second memory lim ...
- JAVA多线程提高三:线程范围内共享变量&ThreadLocal
今天我们学习的是如何在线程自己的范围内达到变量数据的共享,而各个线程之间又是互相独立开来,各自维护的,即我们说的ThreadLocal的作用. 一.概念 可以将每个线程用到的数据与对应的线程号存放到一 ...
- kle 日志收集系统维护之清理索引及索引优化脚本
logstash每天往es建好索引,按天生成,就目前的需求,需要清理不需要的数据,以保证最新日志的速度展示,哈哈,瞎搞了这个脚本,路过的大神批评. #!/usr/bin/env python # co ...
- Xcode变量概览-summary
问题描述 在Xcode中断点调试时,鼠标停留在变量上,就能看到变量的信息.但对于自定义对象,通常Xcode提供的直接信息非常有限,像这样 想要了解这个对象具体的内容,需要展开左边的箭头 当开发者想要知 ...
- js刷题:leecode 25
原题:https://leetcode.com/problems/reverse-nodes-in-k-group/ 题意就是给你一个有序链表.如1->2->3->4->5,还 ...
- python初步学习-python函数 (二)
几个特殊的函数(待补充) python是支持多种范型的语言,可以进行所谓函数式编程,其突出体现在有这么几个函数: filter.map.reduce.lambda.yield lambda >& ...