spark[源码]-SparkEnv执行环境创建
sparkEnv概述
sparkEnv是spark的执行环境,其中包括众多与Executor执行相关的对象。在local模式下Driver会创建Executor,local-cluster部署模式或者Standalone部署模式下worker另起的CoarseGrainedExecutorBackend进程中也会创建Executor,所以SparkEnv存在于Driver或者CoarseGrainedExecutorBackend进程中。
创建分析
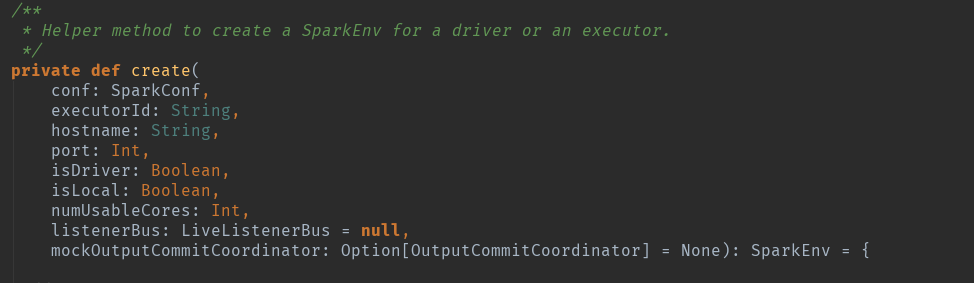
创建方法源码:
_conf.set("spark.executor.id", SparkContext.DRIVER_IDENTIFIER):请注意这个,其实在spark眼里没有driver的概念,都是Executor,只是id标签标记为了driver而已。

根据源码来看,其实在sparkContext初始化的时候,创建的是DriverEnv环境:457行
conf:sparkConf,spark的环境配置。
isLocal:模式判断。
listenerBus:事件监听总线。
SparkContext.numDriverCores(master):Driver的核数。
跳进方法体:代码很长,自行看吧,不全贴图了,根据开发者提示,dirver和executor都是调用的这个创建方法。
具体构造步骤如下:
创建安全管理器:securityManager。
actorSystem创建。

创建Netty分布式消息系统。这个地方默认应该是netty了:val rpcEnvName = conf.get("spark.rpc", "netty")
调用getRpcEnvFactory(conf).create(config)创建rpcEnv

根据代码来看,默认使用的是netty方式的,对应的实例生成类是:org.apache.spark.rpc.netty.NettyRpcEnvFactory中的create方法:

是driver就启动,这个地方启动的netty方式启动的,用于接受Executor的汇报信息。
Serializer和closureSerializer都是使用Class.forName反射生成的org.apache.spark.serializer.JavaSerializer类的实例。其中closureSerializer实例用来对Scala中的闭包进行序列化。
最后都是调用startServiceOnPort启动监听端口,只不过存在driver的这个节点在启动的时候多一个是用netty启动的,多了一个判断处理而已,但是这个节点仍然被认为是Executor。
dirver的netty方式处理:

executor的处理:

两个处理方式不一样,dirver的是netty的方式,而executor是采用akka的actor方式的。最终都是这个方法启动完成创建:

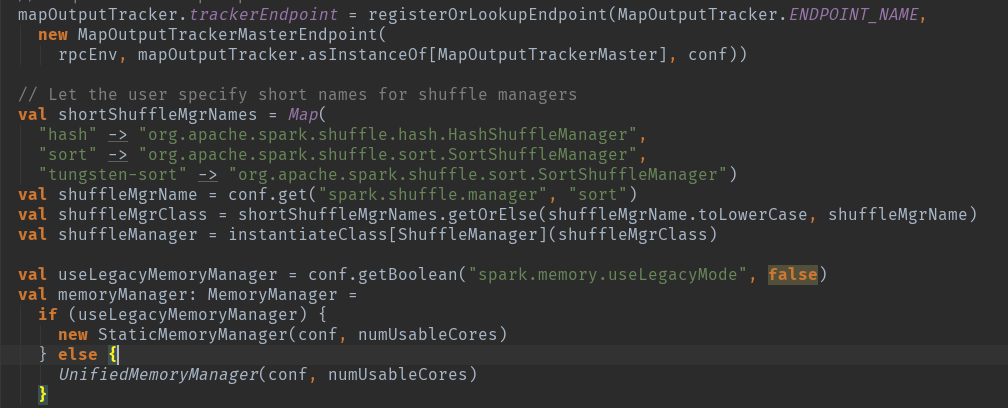
mapOutputTracker创建:
用于跟踪map阶段任务的输出状态,此状态便于reduce阶段任务获取地址及中间输出结果。MapOutputTrackerMaster内部使用mapStatus:TimeStampedHashMap[Int,Array[MapStatus]]来维护跟踪各个map任务的输出状态。其中key对应shuffleId,Array存储各个map任务对应的状态信息MapStatus。

根据代码可以看出,有是根据是否为driver存在不同的创建方式:
如果当前应用程序为Driver,则创建MapOutputTrackerMaster,然后创建MapOutputTrackerMasterEndpoint,并且注册到RpcEndpoint系统中。
如果当前应用程序为Executor,则创建MapOutputTrackerWorker,并从RpcEndpoint持有MapOutputTrackerMasterEndpint的应用。

实例化shuffleManager:
ShuffleManager负责管理本地及远程的block数据的shuffle操作。默认的SortShuffleManager通过持有的IndexShuffleBlockManger间接操作BlockManager中的DiskBlockManger将map结果写入本地,并根据shuffleId,mapId写入索引文件,也能通过MapOutputTrackerMaster中维护的mapStatuses从本地或者其他远程节点读取文件。
块传输服务blockTransferService:
BlockTransferService默认为NettyBlockTransferService,使用Netty提供的异步事件驱动的网络应用框架,提供web服务及客户端,获取远程节点上Block的集合。
BlockManagerMaster介绍:
BlockManagerMaster负责对Block的管理和协调,具体操作依赖于BlockManagerMasterEndpoint。Driver和Executor处理的BlockManagerMaster的方式不同:
·如果当前应用程序为Driver,则创建BlockManagerMasterEndpoint,并且注册到RpcEndpoint中。
·如果当前应用程序为Executor, 则从RpcEndpoint中找到BlockManagerMasterEndpoint。
无论是Driver还是Executor,最后BlockManagerMaster的属性driverEndpoint将持有对BlockManagerMasterEndpoint的引用(RpcEndpointRef)。
创建块管理器BlockManager:
BlockManager负责对Block的管理,只有在BlockManager的初始化方法initialize被调用后,它才是有效地。
创建广播管理器BroadcastManager:
BroadcastManager用户将配置信息和序列化后的RDD、Job以及ShuffleDependency等信息在本地存储。如果为了容灾,也会复制到其他节点上。
BroadcastManager必须在其初始化方法initialize被调用后,才能生效。
创建缓存管理器CacheManager:
CacheManager用户缓存RDD某个分区计算后的中间结果,缓存计算结果发生在迭代计算的时候。
创建测量系统MetricsSystem:
MetricsSystem是Spark的测量系统。
spark[源码]-SparkEnv执行环境创建的更多相关文章
- Spark源码剖析 - SparkContext的初始化(九)_启动测量系统MetricsSystem
9. 启动测量系统MetricsSystem MetricsSystem使用codahale提供的第三方测量仓库Metrics.MetricsSystem中有三个概念: Instance:指定了谁在使 ...
- Spark源码剖析 - SparkContext的初始化(二)_创建执行环境SparkEnv
2. 创建执行环境SparkEnv SparkEnv是Spark的执行环境对象,其中包括众多与Executor执行相关的对象.由于在local模式下Driver会创建Executor,local-cl ...
- emacs+ensime+sbt打造spark源码阅读环境
欢迎转载,转载请注明出处,徽沪一郎. 概述 Scala越来越流行, Spark也愈来愈红火, 对spark的代码进行走读也成了一个很普遍的行为.不巧的是,当前java社区中很流行的ide如eclips ...
- Spark源码剖析 - SparkContext的初始化(三)_创建并初始化Spark UI
3. 创建并初始化Spark UI 任何系统都需要提供监控功能,用浏览器能访问具有样式及布局并提供丰富监控数据的页面无疑是一种简单.高效的方式.SparkUI就是这样的服务. 在大型分布式系统中,采用 ...
- win7+idea+maven搭建spark源码阅读环境
1.参考. 利用IDEA工具编译Spark源码(1.60~2.20) https://blog.csdn.net/He11o_Liu/article/details/78739699 Maven编译打 ...
- spark 源码分析之四 -- TaskScheduler的创建和启动过程
在 spark 源码分析之二 -- SparkContext 的初始化过程 中,第 14 步 和 16 步分别描述了 TaskScheduler的 初始化 和 启动过程. 话分两头,先说 TaskSc ...
- Spark 源码和应用开发环境的构建
引言 Spark 现在无疑是大数据领域最热门的技术之一,读者很容易搜索到介绍如何应用 Spark 技术的文章,但是作为开发人员,在了解了应用的概念之后,更习惯的是打开开发环境,开发一些应用来更深入的学 ...
- Spark源码分析(三)-TaskScheduler创建
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3879151.html 在SparkContext创建过程中会调用createTaskScheduler函 ...
- Spark源码分析环境搭建
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3868718.html 本文主要分享一下如何构建Spark源码分析环境.以前主要使用eclipse来阅读源 ...
随机推荐
- 【转】Native Thread for Win32 A- Create Thread(通俗易懂,非常好)
http://www.bogotobogo.com/cplusplus/multithreading_win32A.php Microsoft Windows operating system's s ...
- Appium自动化测试3之获取apk包名和launcherActivity后续
接着“Appium自动化测试3之获取apk包名和launcherActivity”章节介绍 测试脚本 1.测试脚本如下: # -*- coding:utf-8 -*- import os, time, ...
- AWS系列-EC2实例添加磁盘
注意:添加的磁盘,必须和挂载的实例是在同一可用区. 1.1 如下图,打开EC2控制台,打开卷,点击创建卷 1.2 选择磁盘配置 磁盘类型:如下图 磁盘大小:如图,最小500G,最大16T 可用区:注意 ...
- ArcGIS Android SDK 中文标注乱码
Android使用如下代码添加标注: TextSymbol ts = new TextSymbol(12, "名称", Color.RED);Graphic gp = new Gr ...
- 关东升的iOS实战系列图书 《iOS实战:入门与提高卷(Swift版)》已经上市
承蒙广大读者的厚爱我的 <iOS实战:入门与提高卷(Swift版)>京东上市了,欢迎广大读者提出宝贵意见.http://item.jd.com/11766718.html ...
- 通过pymysql程序debug学习数据库事务、隔离级别
问题 今天在使用pymysql连数据库的时候,出现了一个bug,查询数据库某个数据,但是在我在数据库中执行sql语句改变数据后,pymsql的查询依然没有发生改变. 代码如下: # 5.6.10 co ...
- Spring Security OAuth2 源码分析
Spring Security OAuth2 主要两部分功能:1.生成token,2.验证token,最大概的流程进行了一次梳理 1.Server端生成token (post /oauth/token ...
- wf-删除所选
w框架-结合用户的不同点击路径,提交正确的id集合. <table class="table"> <tr> <td></td> &l ...
- linux devcie lspci,lscpu,blkdiscard,fstrim,parted,partprobe,smartctl
blkdiscard/sparse/thin-provisioned device,like ssdfstrim--- discard unused blocks on a mounted files ...
- Apache 2.4 配置多个虚拟主机的问题
以前一直用Apache2.2的版本,最近升级到了2.4的版本,尝尝新版本嘛. 不过遇到了几个问题,一个就是配置了多个virtualhost,虽然没有报错,不过除了第一可以正常访问外,其他的都存在403 ...