Spark源码剖析 - SparkContext的初始化(九)_启动测量系统MetricsSystem
9. 启动测量系统MetricsSystem
MetricsSystem使用codahale提供的第三方测量仓库Metrics。MetricsSystem中有三个概念:
- Instance:指定了谁在使用测量系统;
- Source:指定了从哪里收集测量数据;
- Sink:指定了从哪里输出测量数据;
Spark按照Instance的不同,区分为Master、Worker、Application、Driver和Executor。
Spark目前提供的Sink有ConsoleSink、CsvSink、JmxSink、MetricsServlet、GraphiteSink等。
Spark中使用MetricsServlet作为默认的Sink。
MetricsSystem在SparkEnv执行环境创建的过程中创建,代码如下:

MetricsSystem的启动代码如下:


MetricsSystem的启动过程包括以下步骤:
1) 注册Sources;
2) 注册Sinks;
3) 给Sinks增加Jetty的ServletContextHandler。
MetricsSystem启动完毕后,会遍历与Sinks有关的ServletContextHandler,并调用attachHandler将它们绑定到Spark UI上。代码如上图
9.1 注册Sources
registerSources方法用于注册Sources,告诉测量系统从哪里收集测量数据。注册Sources的过程分为以下步骤:
1) 从metricsConfig获取Driver的Properties,默认为创建MetricsSystem的过程中解析的{sink.servlet.class=org.apache.spark.metrics.sink.MetricsServlet,sink.servlet.path=/metrics/json}。
2) 用正则匹配Driver的Properties中以source.开头的属性。然后将属性中的Source发射得到的实例加入ArrayBuffer[Source]。
3) 将每个source的metricRegistry(也是MetricSet的子类型)注册到ConcurrentMap<String, Metric>metrics。

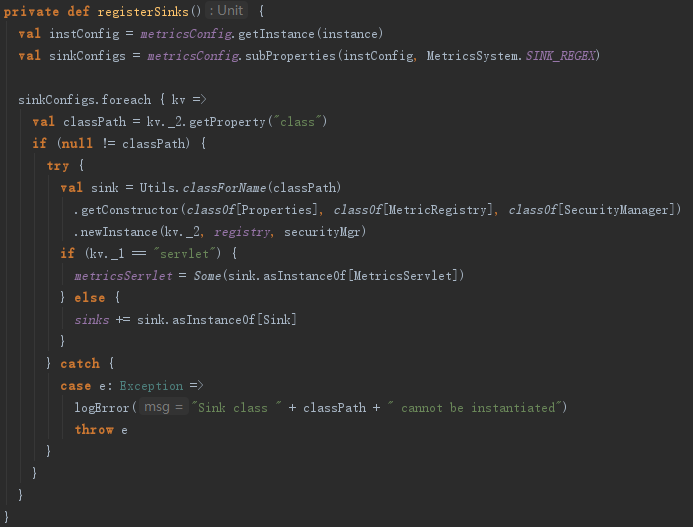
9.2 注册Sinks
registerSinks方法用于注册Sinks,即告诉测量系统MetricsSystem往哪里输出测量数据。注册Sinks的步骤如下:
1) 从Driver的Properties中用正则匹配以sink.开头的属性,如{sink.servlet.class=org.apache.spark.metrics.sink.MetricsServlet,sink.servlet.path=/metrics/json},将其转换为Map(servlet->{class=org.apache.spark.metrics.sink.MetricsServlet,path=/metrics/json})。
2) 将子属性class对应的类metricsServlet发射得到MetricsServlet实例。如果属性的key是serlvet,将其设置为metricsServlet;如果是Sink,则加入到ArrayBuffer[Sink]中。
9.3 给Sinks增加Jetty的ServletContextHandler
为了能够在SparkUI(网页)访问到测量数据,所以需要给Sinks增加Jetty的ServletContextHandler,这里主要用到MetricsSystem的getServletHandlers方法实现如下:

可以看到调用了metricsServlet的getHandlers,其实现如下:

最终生成处理/metrics/json请求的ServletContextHandler,而请求的真正处理由getMetricsSnapshot方法,利用fastjson解析。生成的ServletContextHandler通过SparkUI。最终我们可以使用以下这些地址来访问测量数据。
http://localhost:4040/metrics/applications/json
http://localhost:4040/metrics/json
http://localhost:4040/metrics/master/json
Spark源码剖析 - SparkContext的初始化(九)_启动测量系统MetricsSystem的更多相关文章
- Spark源码剖析 - SparkContext的初始化(二)_创建执行环境SparkEnv
2. 创建执行环境SparkEnv SparkEnv是Spark的执行环境对象,其中包括众多与Executor执行相关的对象.由于在local模式下Driver会创建Executor,local-cl ...
- Spark源码剖析 - SparkContext的初始化(三)_创建并初始化Spark UI
3. 创建并初始化Spark UI 任何系统都需要提供监控功能,用浏览器能访问具有样式及布局并提供丰富监控数据的页面无疑是一种简单.高效的方式.SparkUI就是这样的服务. 在大型分布式系统中,采用 ...
- Spark源码剖析 - SparkContext的初始化(五)_创建任务调度器TaskScheduler
5. 创建任务调度器TaskScheduler TaskScheduler也是SparkContext的重要组成部分,负责任务的提交,并且请求集群管理器对任务调度.TaskScheduler也可以看作 ...
- Spark源码剖析 - SparkContext的初始化(八)_初始化管理器BlockManager
8.初始化管理器BlockManager 无论是Spark的初始化阶段还是任务提交.执行阶段,始终离不开存储体系.Spark为了避免Hadoop读写磁盘的I/O操作成为性能瓶颈,优先将配置信息.计算结 ...
- Spark源码剖析 - SparkContext的初始化(六)_创建和启动DAGScheduler
6.创建和启动DAGScheduler DAGScheduler主要用于在任务正式交给TaskSchedulerImpl提交之前做一些准备工作,包括:创建Job,将DAG中的RDD划分到不同的Stag ...
- Spark源码剖析 - SparkContext的初始化(一)
1. SparkContext概述 注意:SparkContext的初始化剖析是基于Spark2.1.0版本的 Spark Driver用于提交用户应用程序,实际可以看作Spark的客户端.了解Spa ...
- Spark源码剖析 - SparkContext的初始化(十)_Spark环境更新
12. Spark环境更新 在SparkContext的初始化过程中,可能对其环境造成影响,所以需要更新环境,代码如下: SparkContext初始化过程中,如果设置了spark.jars属性,sp ...
- Spark源码剖析 - SparkContext的初始化(七)_TaskScheduler的启动
7. TaskScheduler的启动 第五节介绍了TaskScheduler的创建,要想TaskScheduler发挥作用,必须要启动它,代码: TaskScheduler在启动的时候,实际调用了b ...
- Spark源码剖析 - SparkContext的初始化(四)_Hadoop相关配置及Executor环境变量
4. Hadoop相关配置及Executor环境变量的设置 4.1 Hadoop相关配置信息 默认情况下,Spark使用HDFS作为分布式文件系统,所以需要获取Hadoop相关配置信息的代码如下: 获 ...
随机推荐
- MySQL 报错 1055
具体报错 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'exer.student.sid' w ...
- 【比赛】NOIP2018 货币系统
可以发现最后的集合一定是给定集合的子集 所以就变成了裸的背包嘛,对于每个数判断它能不能被其它数表示出来,如果可以,就表示这个数是没用的,可以去掉 #include<bits/stdc++.h&g ...
- 【SPOJ】Power Modulo Inverted(拓展BSGS)
[SPOJ]Power Modulo Inverted(拓展BSGS) 题面 洛谷 求最小的\(y\) 满足 \[k\equiv x^y(mod\ z)\] 题解 拓展\(BSGS\)模板题 #inc ...
- 51NOD1174 区间最大数 && RMQ问题(ST算法)
RMQ问题(区间最值问题Range Minimum/Maximum Query) ST算法 RMQ(Range Minimum/Maximum Query),即区间最值查询,是指这样一个问题:对于长度 ...
- CF1139D Steps to One(DP,莫比乌斯反演,质因数分解)
stm这是div2的D题……我要对不住我这个紫名了…… 题目链接:CF原网 洛谷 题目大意:有个一开始为空的序列.每次操作会往序列最后加一个 $1$ 到 $m$ 的随机整数.当整个序列的 $\gcd ...
- 前端基础-- HTML
HTML知识 HTML介绍 Web服务本质 浏览器发请求 --> HTTP协议 --> 服务端接收请求 --> 服务端返回响应 --> 服务端把HTML文件内容发给浏览器 -- ...
- 编写高质量代码:改善Java程序的151个建议 --[26~36]
提防包装类型的null值 public static int testMethod(List<Integer> list) { int count = 0; for (Integer i ...
- nio 阻塞 非阻塞 同步 异步
https://mp.weixin.qq.com/s/5SKgdkC0kaHN495psLd3Tg 说在前面 上篇NIO相关基础篇二,主要介绍了文件锁.以及比较关键的Selector,本篇继续NIO相 ...
- QML学习笔记(三)-引入Font-awesome
作者: 狐狸家的鱼 Github: 八至 1.首先得在qml文件夹下建立字体文件,将font-awesome放入进去 2.然后在main.cpp中注册字体 引入中一定要写上 引用字体 引用字体得路径一 ...
- 区间最深LCA
求编号在区间[l, r]之间的两两lca的深度最大值. 例题. 解:口胡几种做法.前两种基于莫队,第三种是启发式合并 + 扫描线,第四种是lct + 线段树. ①: 有个结论就是这个答案一定是点集中D ...