一致性Hash算法说明
- 本文章比较好的说明了一致性Hash算法的概念
- Hash算法一般分为除模求余和一致性Hash
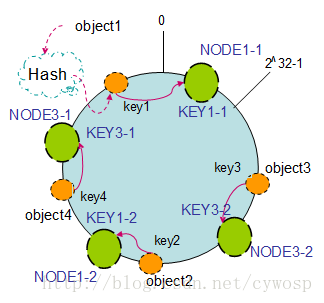
1、除模求余:当新增、删除机器时会导致大量key的移动
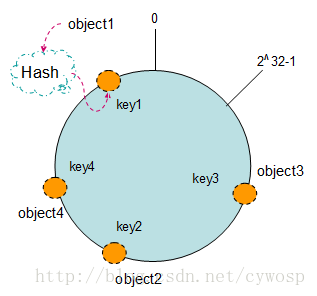
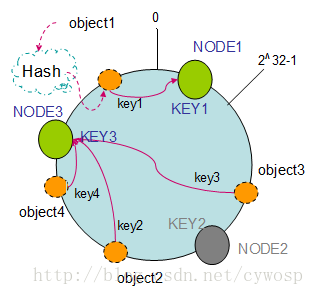
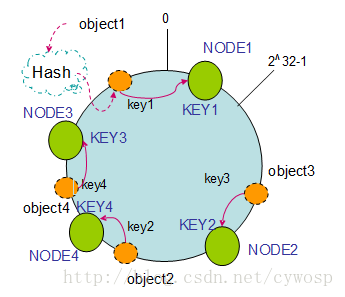
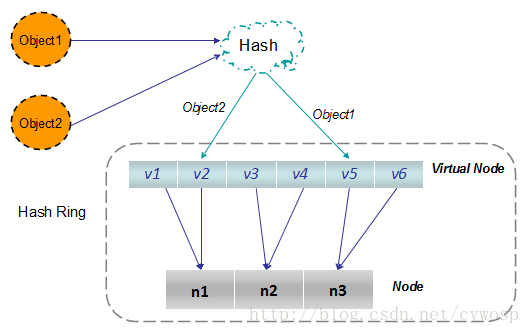
2、一致性Hash:当新增、删除机器时只会影响到附近的key,因为是环状结构
1、平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
2、单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
3、分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
4、负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。

一致性Hash算法说明的更多相关文章
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- 一致性hash算法详解
转载请说明出处:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT) ...
- 一致性hash算法简介
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简单哈希 ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 一致性 hash 算法( consistent hashing )a
一致性 hash 算法( consistent hashing ) 张亮 consistent hashing 算法早在 1997 年就在论文 Consistent hashing and rando ...
- 一致性hash算法简介与代码实现
一.简介: 一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义: 1.平衡性(Balance) 2.单调性(Monotonicity) 3.分散性(Spread) 4.负 ...
- memcache的一致性hash算法使用
一.概述 1.我们的memcache客户端(这里我看的spymemcache的源码),使用了一致性hash算法ketama进行数据存储节点的选择.与常规的hash算法思路不同,只是对我们要存储数据的k ...
- 一致性Hash算法在Redis分布式中的使用
由于redis是单点,但是项目中不可避免的会使用多台Redis缓存服务器,那么怎么把缓存的Key均匀的映射到多台Redis服务器上,且随着缓存服务器的增加或减少时做到最小化的减少缓存Key的命中率呢? ...
- 【转载】一致性hash算法释义
http://www.cnblogs.com/haippy/archive/2011/12/10/2282943.html 一致性Hash算法背景 一致性哈希算法在1997年由麻省理工学院的Karge ...
- 一致性Hash算法在Memcached中的应用
前言 大家应该都知道Memcached要想实现分布式只能在客户端来完成,目前比较流行的是通过一致性hash算法来实现.常规的方法是将server的hash值与server的总台数进行求余,即hash% ...
随机推荐
- 用原生js实现ajax
// 通过createXHR()函数创建一个XHR对象 function createXHR() { if(window.XMLHttpRequest) { // IE7.Firefox.Opera. ...
- [转载]angular通过$http与服务器通信
转载自:http://www.cooklife.cn/detail/54c5044ec93620284e964b58#View angular是一个前端框架,实现了可交互式的页面,但是对于一个web应 ...
- 深入理解java虚拟机-01 走进java
第一章是对java的产生,历史的整体介绍 java的使用很广泛,安装jdk的时候会看到一句广告语runs in 10 billions machines.使用java的设备多达几十亿台 1.概述 优点 ...
- 绘图: matplotlib核心剖析
参考:http://www.cnblogs.com/vamei/archive/2013/01/30/2879700.html http://blog.csdn.net/ywjun0919/artic ...
- TinyHttpd代码解析
十一假期,闲来无事.看了几个C语言开源代码.http://www.cnblogs.com/TinyHttpd 这里本来想解析一下TinyHttpd的代码,但是在网上一搜,发现前辈们已经做的很好了.这里 ...
- android短信验证
短信验证demo http://download.csdn.net/detail/crazy1235/8315279#comment 使用MOB平台开发,用法详见: http://blog.csdn. ...
- jQuery预览图
- explain的使用
MySQL 提供了一个 EXPLAIN 命令, 它可以对 SELECT 语句进行分析, 并输出 SELECT 执行的详细信息, 以供开发人员针对性优化. mysql. row ************ ...
- 如何用node.js批量给图片加水印
上一篇我们讲了如何用node.js给图片加水印,但是只是给某一张图片加,并没有涉及到批量处理.这一篇,我们学习如果批量进行图片加水印处理. 一.准备工作: 首先,你要阅读完这篇文章:http://ww ...
- C语言中对数组名取地址
在C/C++中,数组名相当于一个指针,指向数组的首地址.这里“相当于”不代表等于,数组名和指针还是有很多区别的,这个在<C陷阱与缺陷>里有详尽的讲述.而这里要说的是对于数组名取地址的这么一 ...