数据同步canal客户端
1、增量订阅、消费设计
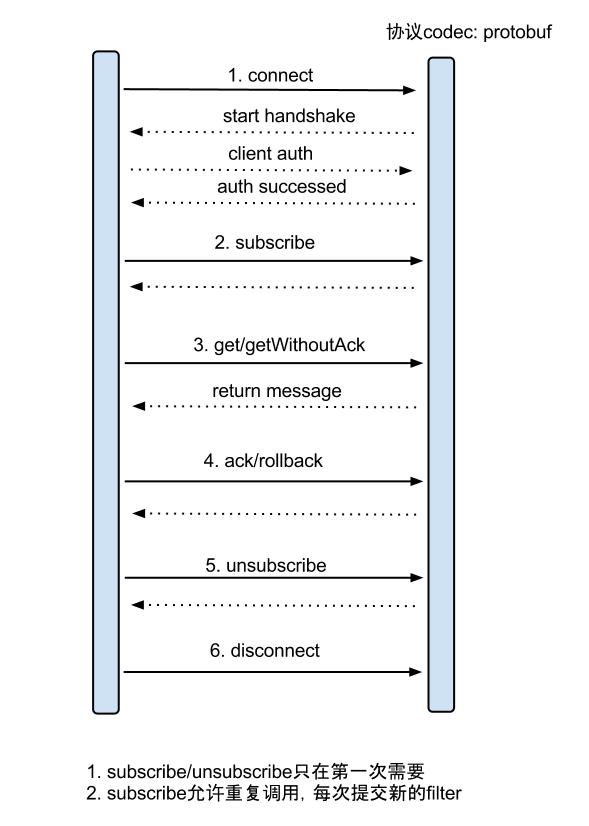
get/ack/rollback协议介绍:
① Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:
a. batch id 唯一标识
b. entries 具体的数据对象,对应的数据对象格式:EntryProtocol.proto
② void rollback(long batchId),顾命思议,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
③ void ack(long batchId),顾命思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
2、数据对象格式:EntryProtocol.proto
Entry
Header
logfileName [binlog文件名]
logfileOffset [binlog position]
executeTime [binlog里记录变更发生的时间戳]
schemaName [数据库实例]
tableName [表名]
eventType [insert/update/delete类型]
entryType [事务头BEGIN/事务尾END/数据ROWDATA]
storeValue [byte数据,可展开,对应的类型为RowChange]
RowChange
isDdl [是否是ddl变更操作,比如create table/drop table]
sql [具体的ddl sql]
rowDatas [具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理]
beforeColumns [Column类型的数组]
afterColumns [Column类型的数组] Column
index [column序号]
sqlType [jdbc type]
name [column name]
isKey [是否为主键]
updated [是否发生过变更]
isNull [值是否为null]
value [具体的内容,注意为文本]
insert只有after columns, delete只有before columns,而update则会有before / after columns数据.
3、client使用例子
3.1 创建Connector
a. 创建SimpleCanalConnector (直连ip,不支持server/client的failover机制)
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),11111), destination, "", "");
b. 创建ClusterCanalConnector (基于zookeeper获取canal server ip,支持server/client的failover机制)
CanalConnector connector = CanalConnectors.newClusterConnector("10.20.144.51:2181", destination, "", "");
c. 创建ClusterCanalConnector (基于固定canal server的地址,支持固定的server ip的failover机制,不支持client的failover机制
CanalConnector connector = CanalConnectors.newClusterConnector(Arrays.asList(new InetSocketAddress(AddressUtils.getHostIp(),11111)), destination,"", "");
如上可见,创建client connector的时候需要指定destination,即对应于一个instance,一个数据库。所以canal client和数据库是一一对应的关系。
3.2 get/ack/rollback使用
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(canal_ip, 11111), destination, canal_username, canal_password); try { // 连接canal,获取数据
connector.connect();
connector.subscribe();
connector.rollback();
log.info("数据同步工程启动成功,开始获取数据");
while (true) { // 获取指定数量的数据
Message message = connector.getWithoutAck(1000); // 数据批号
long batchId = message.getId(); // 获取该批次数据的数量
int size = message.getEntries().size(); // 无数据
if (batchId == -1 || size == 0) { // 等待1秒后重新获取
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
log.error(e);
Thread.currentThread().interrupt();
} // 提交确认
connector.ack(batchId); // 数据存在,执行方法
} else {
try { // 处理数据
HandleData.handleEntry(message.getEntries()); // 提交确认
connector.ack(batchId);
} catch (KafkaException e) {
log.error(e); // 处理失败, 回滚数据
connector.rollback(batchId);
} catch (Exception e1) {
log.error(e1); // 提交确认
connector.ack(batchId);
}
}
}
} catch (Exception e) { log.error(e);
} finally { // 断开连接
connector.disconnect();
}
处理数据的方法封装到HandleData类中,且看handleEntry如何处理
// 获取日志行
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
log.error(e);
} // 获取执行事件类型
EventType eventType = rowChage.getEventType(); // 日志打印,数据明细
log.info(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s", entry
.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(), entry.getHeader()
.getSchemaName(), entry.getHeader().getTableName(), eventType)); // 获取表名
String tableName = entry.getHeader().getTableName(); // 遍历日志行,执行任务
for (RowData rowData : rowChage.getRowDatasList()) {
Map<String, Object> data; // 删除操作
if (eventType == EventType.DELETE) { // 解析数据
data = DataUtils.parseData(tableName, "delete", rowData.getBeforeColumnsList()); // 插入操作
} else if (eventType == EventType.INSERT) { // 解析数据
data = DataUtils.parseData(tableName, "insert", rowData.getAfterColumnsList()); // 更新操作
} else { // 解析数据
data = DataUtils.parseData(tableName, "update", rowData.getAfterColumnsList());
} // 数据解析成功
if (data != null && data.size() > 0) { // 内容转接json格式发送
JSONObject json = JSONObject.fromObject(data);
try {
Productor.send("canal_" + tableName = "_topic", json.toString(), tableName + "|" + data.get("canal_kafka_key"));
} catch (Exception e) {
throw new KafkaException("kafka发送异常:" + e);
} log.info("数据成功发送kafka");
}
}
Entry数据被解析成Map格式数据,然后转为json字符串,发到kafka。为什么要借用消息中间件kafka呢,不用kafka可以吗?当然可以,直接写数据同步的逻辑没有问题。但是如果一个数据用到多个业务场景,势必导致一个类中有多套同步逻辑,对于后期的维护很不利,多套业务掺杂在一起势必会互相影响。合理的做法应该是业务隔离,每套业务都能接受到数据变更的消息,然后做自己需要的同步,这样就需要在数据接受和数据处理形成1对n的关系。消息中间件的消息接受和消费模型正好可以完成这个功能。
一个canal client的消息分发给多个kafka消费者消费。每个kafka消费者代表一种业务场景,架构清晰、利于维护,同时一个kafka消费者可以消费多个canal client的topic。
上面的解析数据逻辑比较简单,将list解析成map
Map<String, Object> result = new HashMap<String, Object>();
try {
int index = 0;
for (Column column : columns) {
String value = column.getIsNull() ? null : column.getValue(); // kafka在消息为10K时吞吐量达到最大
if (value != null && value.length() > 10240) {
value = value.substring(0, 10240);
}
if (index == 0) {
result.put("canal_kafka_key", value);
}
result.put(column.getName(), value);
index++;
}
result.put("operate_type", "delete"||"insert"||"update");
} catch (Exception e) {
log.error(e);
}
if (logStr.lastIndexOf(",") == logStr.length() - 1) {
logStr = logStr.substring(0, logStr.length() - 1);
}
return result;
数据同步canal客户端的更多相关文章
- 数据同步canal服务端介绍
1.下载安装包 canal&github的地址,最权威的学习canal相关知识的地方 https://github.com/alibaba/canal 在下面的wiki列表中找到AdminGu ...
- 数据同步canal服务端HA配置
canal服务端HA模式,本人并未使用过,为保证文章的完整性,从以下地址摘抄该部分内容,待以后验证及使用 https://github.com/alibaba/canal/wiki/AdminGuid ...
- 数据同步canal服务端配置mysql多主
canal服务端HA模式,本人并未使用过,为保证文章的完整性,从以下地址摘抄该部分内容,待以后验证及使用 https://github.com/alibaba/canal/wiki/AdminGuid ...
- CentOS7下rsync服务端与Windows下cwRsync客户端实现数据同步配置方法
最近需求想定期备份服务器d盘的数据到Linux服务器上面,做个笔记顺便写下遇到的问题 以前整过一个win下的cwrsync(客户端)+rsync(服务端:存储)的bat脚本 和整过一个Linux下的r ...
- Linux-非结构化数据同步-Linux下Rsync+Rsync实现非结构化增量差异数据的同步2
说明: 操作系统:CentOS 5.X 源服务器:192.168.21.129 目标服务器:192.168.21.127,192.168.21.128 目的:把源服务器上/home/www.osyun ...
- canal数据同步 客户端代码实现
1.引入相关依赖 <dependencies> <dependency> <groupId>org.springframework.boot</groupId ...
- canal数据同步目录
我们公司对于数据同步有以下需求 1.多个mysql库中有一些基础表需要数据统一,mysql跨库同步 2.mysql热数据加载到redis 3.全文检索需要mysql同步到es 4.数据变更是附属的其它 ...
- 阿里Canal框架(数据同步中间件)初步实践
最近在工作中需要处理一些大数据量同步的场景,正好运用到了canal这款数据库中间件,因此特意花了点时间来进行该中间件的的学习和总结. 背景介绍 早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存 ...
- 基于canal的client-adapter数据同步必读指南
本文将介绍canal项目中client-adapter的使用,以及落地生产中需要考虑的可靠性.高可用与监控报警.(基于canal 1.1.4版本) canal作为mysql的实时数据订阅组件,实现了对 ...
随机推荐
- 编程输出杨辉三角的前10行---多维数组的应用---java实现
import java.util.Scanner;public class yanghui{ public static void main(String[] args){ Scanner sc=n ...
- HDU4662(SummerTrainingDay03-B)
MU Puzzle Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total S ...
- 老男孩教育python全栈第九期视频
失效了在下面评论即可,会及时更新.python9期已全部更新完 链接: https://pan.baidu.com/s/1VV8_ZyVasK05iKd7QMxO-A 密码: 9zau
- SPOJ4580 ABCDEF(meet in the middle)
题意 题目链接 Sol 发现abcdef是互不相关的 那么meet in the middle一下.先算出abc的,再算def的 注意d = 0的时候不合法(害我wa了两发..) #include&l ...
- 接口自动化 基于python实现的http+json协议接口自动化测试框架源码(实用改进版)
基于python实现的http+json协议接口自动化测试框架(实用改进版) by:授客 QQ:1033553122 欢迎加入软件性能测试交流QQ群:7156436 目录 1. ...
- 【转】Linux配置NTP时间同步服务器
分布式程序通常需要运行在一个统一的时间环境里. 转自:http://blog.csdn.net/mengfanzhundsc/article/details/62046562 安装NTP:yum in ...
- smarty详细使用教程(韩顺平smarty模板技术笔记)
MVC是一种开发模式,强调数据的输入.处理.显示是强制分离的 Smarty使用教程1.如何配置我们的smarty解压后把libs文件夹放在网站第一级目录下,然后创建两个文件夹templates 存放模 ...
- 团队项目个人进展——Day07
一.昨天工作总结 冲刺第七天,学习了微信小程序中WebSocket 连接,如果当前已存在一个 WebSocket 连接,会自动关闭该连接,并重新创建一个 WebSocket 连接. 二.遇到的问题 对 ...
- AJAX四种跨域处理方法
同源策略 同源策略 同源策略限制从一个源加载的文档或者脚本如何与来自另一个源的资源进行交互.这是一个用于隔离潜在恶意文件的关键的安全机制. 具体定义是:一段脚本向后台请求数据,只能读取属于同一协议名. ...
- SQL Server 如何设置数据库的默认初始大小和自动增长大小
我们在SQL Server中新建数据库的时候,可以选择数据库文件及日志文件的初始大小.自动增长大小和最大大小,如下图所示: 可以通过设置更改数据库初始大小.自动增长大小和最大大小: 但是其实在SQL ...