spark work目录处理 And HDFS空间都去哪了?
1、说在前面
过完今天就放假回家了(挺高兴),于是提前检查了下个服务集群的状况,一切良好。正在我想着回家的时候突然发现手机上一连串的告警,spark任务执行失败,spark空间不足。我的心突然颤抖了一下,于是赶紧去看服务器的磁盘容量:
#df -h
确实,还剩下6.8G,赶紧排查是什么占用了空间。发现hadoop、spark站的空间比较大,一个50多G(data)、一个30多G(spark-events)。不对啊,这也没占多少啊,于是登录到hadoop的webui去看资源的使用情况:
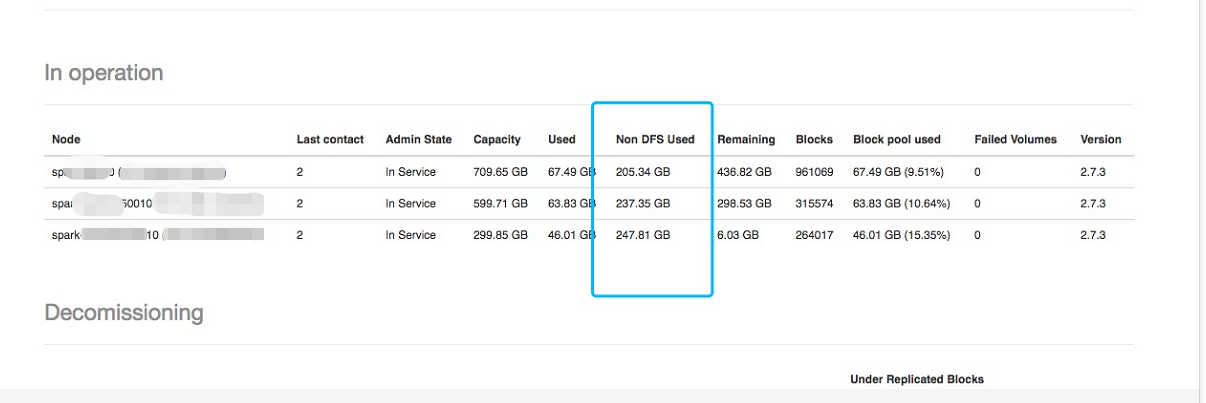
发现Non DFS Used的值很大,接下来就是名词解释时间:
Capacity:可用的总空间
Used:已用的空间
Non DFS Used:非hdfs文件占用dfs的空间(侵占)
Remaining:剩余可用空间
发现Non DFS Used的值都很大,证明有很多的非hdfs文件侵占了大量的dfs空间。可以看到其中有一个加点只剩6.03G了。这个总空间的大小默认就是磁盘的大小,不过hadoop有个磁盘的配置项dfs.datanode.du.reserved,这个配置是设置hadoop保留一部分不用于hdfs存储的空间默认是0。
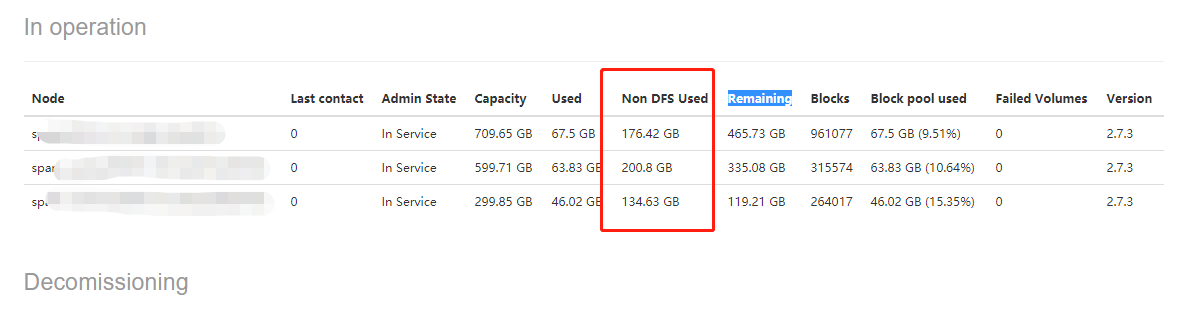
2、好了,明白这个后,开始去排查到底是什么文件侵占了dfs的空间。看了一下服务器上面部署的服务,有spark、hadoop(hdfs)、presto,如果是对大数据相对熟悉的人第一判断应该是spark,首先想到的是spark work和spark-events,检查是否运行了history。简单科普一下,spark work存放的是一个spark work任务运行的依赖环境和日志输出,集群其他的节点都来这个地方拉取,spark-events存放的是运行日志,history web就是去的这里的数据。经检查发现是work,已经201G了。
使用spark standalone模式执行任务,每提交一次任务,在每个节点work目录下都会生成一个文件夹,命名规则app-20180212191730-0249。该文件夹下是任务提交时,各节点从主节点下载的程序所需要的资源文件。 这些目录每次执行都会生成,且不会自动清理,执行任务过多会将内存撑爆。将历史没用的work目录下面的app目录删除:
3、解决方案
需要添加定时清理策略,只针对于standalong模式:
在spark-env.sh里面添加如下配置
-Dspark.worker.cleanup.interval=1800:清理周期,每隔多长时间清理一次,单位秒
-Dspark.worker.cleanup.appDataTtl=3600:保留最近多长时间的数据
spark work目录处理 And HDFS空间都去哪了?的更多相关文章
- du 命令,对文件和目录磁盘使用的空间的查看
Linux du命令也是查看使用空间的,但是与df命令不同的是Linux du命令是对文件和目录磁盘使用的空间的查看,还是和df命令有一些区别的. 1.命令格式: du [选项][文件] 2.命令功能 ...
- hadoop进阶---hadoop性能优化(一)---hdfs空间不足的管理优化
Hadoop 空间不足,hive首先就会没法跑了,进度始终是0%. 将HDFS备份数降低 将默认的备份数3设置为2. 步骤:CDH–>HDFS–>配置–>搜索dfs.replicat ...
- Flume实时监控目录sink到hdfs,再用sparkStreaming监控hdfs的这个目录,对数据进行计算
目标:Flume实时监控目录sink到hdfs,再用sparkStreaming监控hdfs的这个目录,对数据进行计算 1.flume的配置,配置spoolDirSource_hdfsSink.pro ...
- 泛函p121可分Hilbert空间都同构于l^2
如何理解最后面两句话, L^2与l^2同构 L^2里面 有理系数多项式 是可数稠密子集 所以L^2可分 可分Hilbert空间都同构于 l^2 傅里叶级数是一个稠密的子集
- du---是对文件和目录磁盘使用的空间查看
du命令也是查看使用空间的,但是与df命令不同的是Linux du命令是对文件和目录磁盘使用的空间的查看,还是和df命令有一些区别的. 语法 du [选项][文件] 选项 -a或-all 显示目录中个 ...
- linux中root目录下下指定磁盘空间扩容
1 查看当前磁盘情况 fdisk -l /dev/sda1 2048 6143 2048 83 Linux /dev/sda2 * 6144 1054719 524288 83 Linux /dev/ ...
- Redis内存——内存消耗(内存都去哪了?)
最新:Redis内存--三个重要的缓冲区 最新:Redis内存--内存消耗(内存都去哪了?) 最新:Redis持久化--如何选择合适的持久化方式 最新:Redis持久化--AOF日志 更多文章... ...
- MySQL 中删除的数据都去哪儿了?
不知道大家有没有想过下面这件事? 我们平时调用 DELETE 在 MySQL 中删除的数据都去哪儿了? 这还用问吗?当然是被删除了啊 那么这里又有个新的问题了,如果在 InnoDB 下,多事务并发的情 ...
- from表单上提交的数据都去了哪里呢?
from表单上提交的数据都去了哪里呢? 一个简单的from案例如下: <form> 姓名:<br> <input type="text" name=& ...
随机推荐
- QT中的线程与事件循环理解(2)
1. Qt多线程与Qobject的关系 每一个 Qt 应用程序至少有一个事件循环,就是调用了QCoreApplication::exec()的那个事件循环.不过,QThread也可以开启事件循环.只不 ...
- UIKit Dynamic主题学习笔记
1.重力效果:UIGravityBehavior @IBOutlet weak var frogImage: UIImageView! //创建一个关联到view的动画(必须为全局变量) lazy v ...
- find的用法(完整)
一.根据文件或者正则表达式进行匹配 1.列出当前目录(/.code)及子目录下所有文件和文件夹 find . 2.在当前目录(/.code)下查找以.pdf结尾的文件名 find . -name & ...
- 2.Django模型
ORM简介 MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库 ORM是“对象-关系-映射”的简称 ...
- CAS Ticket票据:TGT、ST、PGT、PT、PGTIOU
CAS的核心就是其Ticket,及其在Ticket之上的一系列处理操作.CAS的主要票据有TGT.ST.PGT.PGTIOU.PT,其中TGT.ST是CAS1.0协议中就有的票据,PGT.PGTIOU ...
- php file_get_contents fopen 连接远程文件
使用file_get_contents和fopen必须空间开启allow_url_fopen. 方法: 编辑php.ini,设置allow_url_fopen =true On,allow_url_f ...
- C# WPF 中WebBrowser拖动来移动窗口,改变窗口位置
前言 wpf中的WebBrowser相比之前的winform阉割了不少东西,也增加了不少东西,但是msdn对wpf也没有较好的文档 WebBrowser可以说是一个.NET控件,相对于WPF中的控件, ...
- JavaScript 那些不经意间发生的数据类型自动转换
JavaScript可以自由的进行数据类型转换,也提供了多种显式转换的方式.但是更多的情况下,是由JavaScript自动转换的,当然这些转换遵循着一定的规则,了解数据类型自由转换的规则是非常必要的. ...
- 初识SQL语句
SQL(Structured Query Language ) 即结构化查询语言 SQL语言主要用于存取数据.查询数据.更新数据和管理关系数据库系统,SQL语言由IBM开发.SQL语言分为3种类型: ...
- Django admin argument to reversed() must be a sequence
django执行反序列化操作老是报Django admin argument to reversed() must be a sequence 切记查看所有的路由设置,主路由(urls)和分的都要修改 ...