hadoop-eclipse插件编译及windows下运行wordcount项目
参考文章:http://www.360doc.com/content/16/0227/18/10529016_537828949.shtml,
配置修改:http://blog.csdn.net/loliaryx/article/details/79125444
本文基于以上两篇文章和自己的实际操作整理,之前没有成功就是因为没有进行“hadoop2x-eclipse-plugin”配置修改:
1.环境:
win7 64位,hadoop2.7.5,JDK1.8.0_162,ant1.9.10,eclipse(Mars.1 Release (4.5.1))
Hadoop2.x之后没有Eclipse插件工具,我们就不能在Eclipse 上调试代码,我们要把写好的java代码的MapReduce打包成jar然后在Linux上运行,所以这种不方便我们调试代码,所以我们自己编译一个 Eclipse插件,方便我们在我们本地上调试,经过hadoop1.x的发展,编译hadoop2.x版本的eclipse插件比之前简单多了。接下来 我 们开始编译Hadoop-eclipse-plugin插件,并在Eclipse开发Hadoop。
2.下载安装ant
http://ant.apache.org/bindownload.cgi

解压后

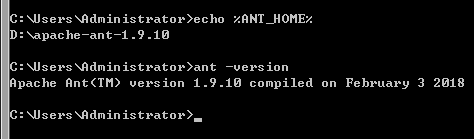
配置环境变量:
在计算机-》右键-》属性-》高级系统设置-》高级-》环境变量-》系统变量新建变量
ANT_HOME
D:\apache-ant-1.9.10
PATH末尾添加
%ANT_HOME%\bin;
3.hadoop下载
从官网下载Hadoop最新版2.7.5
http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz
解压
4.下载hadoop2x-eclipse-plugin源码
https://github.com/winghc/hadoop2x-eclipse-plugin然后点击Download ZIP进行下载
解压:D:\hadoop2x-eclipse-plugin-master-master
修改相关文件, 主要有两个,
一个是 hadoop2x-eclipse-plugin-master/src/contrib/eclipse-plugin/build.xml , 第二个是 hadoop2x-eclipse-plugin-master/ivy/libraries.properties
4.1 修改build.xml
1.在第81行 找到 <!-- Override jar target to specify manifest --> ,
在第82行 找到 <target name="jar" depends="compile" unless="skip.contrib">标签,添加和修改copy子标签标签一下内容, 也就是127行下面, 如下 ( 删除第127行 <copy file="${hadoop.home}/share/hadoop/common/lib/htrace-core-${htrace.version}.jar" todir="${build.dir}/lib" verbose="true"/> , 添加下面3行 ) <copy file="${hadoop.home}/share/hadoop/common/lib/htrace-core-${htrace.version}-incubating.jar" todir="${build.dir}/lib" verbose="true"/> <copy file="${hadoop.home}/share/hadoop/common/lib/servlet-api-${servlet-api.version}.jar" todir="${build.dir}/lib" verbose="true"/> <copy file="${hadoop.home}/share/hadoop/common/lib/commons-io-${commons-io.version}.jar" todir="${build.dir}/lib" verbose="true"/>
然后找到标签<attribute name="Bundle-ClassPath" ( 在修改之前的配置文件 build.xml 第133行 )在齐总的value的列表中对应的添加和修改lib,如下 ( 删除第154行 lib/htrace-core-${htrace.version}.jar, 添加下面3行 ) lib/servlet-api-${servlet-api.version}.jar, lib/commons-io-${commons-io.version}.jar, lib/htrace-core-${htrace.version}-incubating.jar"/>
4.2 修改 hadoop2x-eclipse-plugin-master/ivy/libraries.properties
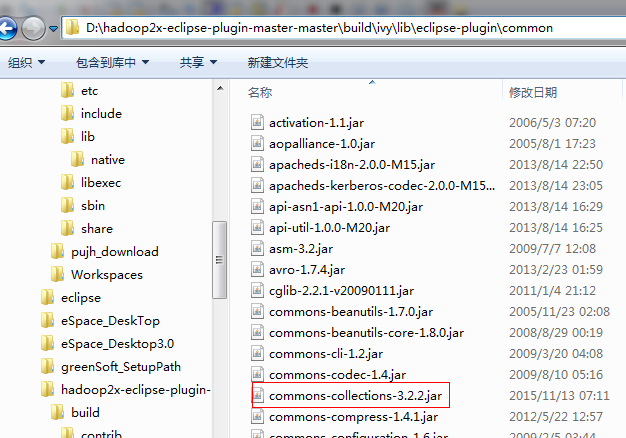
此步骤要根据实际情况修改(D:\hadoop2x-eclipse-plugin-master-master\build\ivy\lib\eclipse-plugin\common 中有下面的包,修改为相对应jar的版本即可)
#hadoop.version=2.6.0 modify
hadoop.version=2.7.5
#commons-collections.version=3.2.1 modify
commons-collections.version=3.2.2
#commons-httpclient.version=3.0.1 modify
commons-httpclient.version=3.1
#commons-logging.version=1.0.4 modify
commons-logging.version=1.1.3
#commons-logging-api.version=1.0.4 modify
commons-logging-api.version=1.1.3
#commons-math.version=2.1 modify
commons-math.version=3.1.1
#commons-io.version=2.1 modify
commons-io.version=2.4
#hsqldb.version=1.8.0.10 modify
hsqldb.version=2.0.0
#htrace.version=3.0.4 modify
htrace.version=3.1.0
jets3t.version=0.6.1 modify
jets3t.version=0.9.0
#jersey-core.version=1.8 modify
#jersey-json.version=1.8 modify
#jersey-server.version=1.8 modify
jersey-core.version=1.9
jersey-json.version=1.9
jersey-server.version=1.9
#junit.version=4.5 modify
junit.version=4.11
#slf4j-api.version=1.7.5 modify
#slf4j-log4j12.version=1.7.5 modify
slf4j-api.version=1.7.10
slf4j-log4j12.version=1.7.10
#xerces.version=1.4.4 modify
xerces.version=2.9.1
5.编译插件
在cmd中
cd /d D:\hadoop2x-eclipse-plugin-master-master\src\contrib\eclipse-plugin
然后:
ant jar -Dversion=2.7.5 -Dhadoop.version=2.7.5 -Declipse.home=D:\eclipse -Dhadoop.home=D:\Develop\hadoop-2.7.5
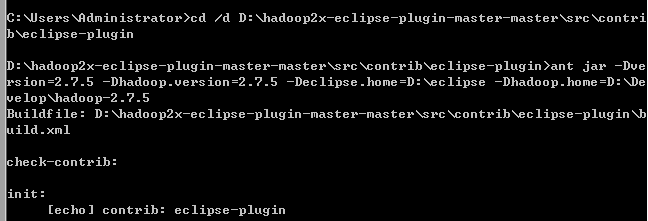
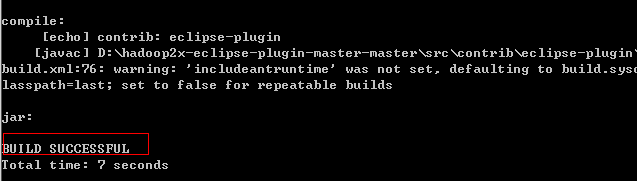
编译成功的插件hadoop-eclipse-plugin-2.7.5.jar在D:\hadoop2x-eclipse-plugin-master-master\build\contrib\eclipse-plugin下

6.安装插件
关闭eclipse
6.1将插件拷贝至
D:\eclipse\plugins
重启eclipse,可以看到DFS Locations

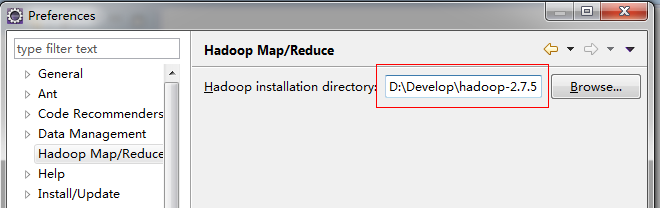
打开Window->Preferences->hadoop Map/Reduce,填写本地hadoop路径
Window-->Show View-->Others-->MapReduce Tools 点击Map/ReduceLocation
然后点击Map/Reduce Locations选项卡 右侧小象图标,打开Hadoop Location配置窗口: 输入Location Name,任意名称即可.配置Map/Reduce Master和DFS Mastrer,Host和Port配置成hdfs-site.xml与core-site.xml的设置一致即可

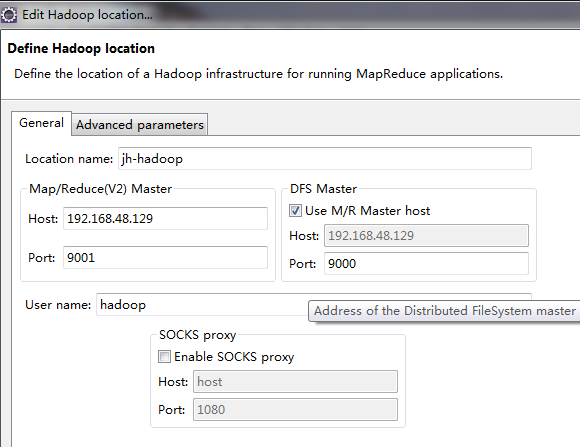
完成后点击右下侧的finish

查看是否连接成功
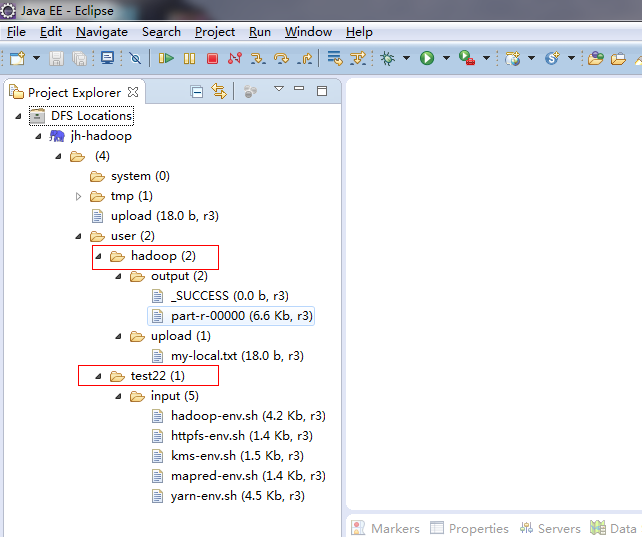
7.运行新建WordCount 项目并运行
7.1下载window环境所需要的批处理文件hadoop.dll和winutils.exe
http://download.csdn.net/detail/chenxf10/9621093
hadoop安装路径D:\Develop\hadoop-2.7.5\bin下放置hadoop.dll和winutils.exe两个文件
C:\Windows\System32路径下放置winutils.exe
没有的直接运行会报错
7.2.File->New->Map/Reduce Project
7.3.新建WordCount.java
解压D:\Develop\hadoop-2.7.5\share\hadoop\mapreduce\sources\hadoop-mapreduce-examples-2.7.5-sources.jar
拷贝org\apache\hadoop\examples\WordCount.java到eclipse工程下
src目录下新建log4j.properties文件
内容:
### 设置###
log4j.rootLogger = debug,stdout,D,E
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n ### 输出DEBUG 级别以上的日志到=E://logs/error.log ###
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = E://logs/log.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n ### 输出ERROR 级别以上的日志到=E://logs/error.log ###
log4j.appender.E = org.apache.log4j.DailyRollingFileAppender
log4j.appender.E.File =E://logs/error.log
log4j.appender.E.Append = true
log4j.appender.E.Threshold = ERROR
log4j.appender.E.layout = org.apache.log4j.PatternLayout
log4j.appender.E.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n 可以参考:http://blog.csdn.net/sinat_30185177/article/details/73550377
工程目录结构:
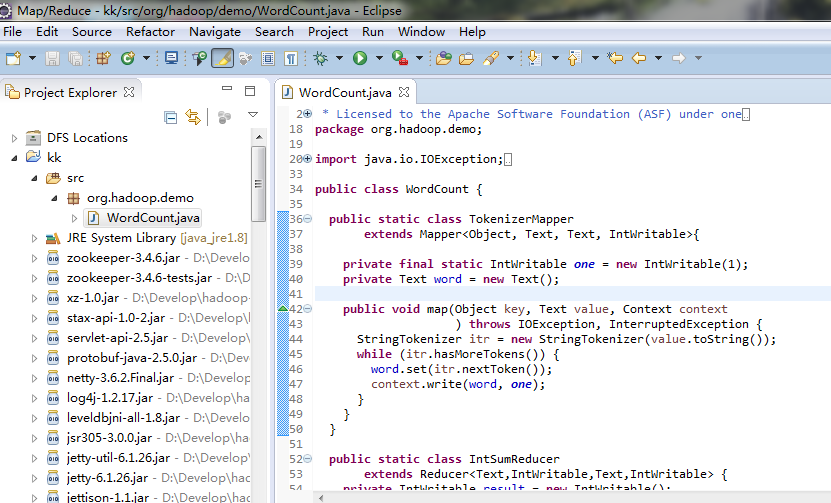
7.3.在hdfs输入目录创建需要统计的文本
以下建目录,上传文件都在linux任意能连接hadoop集群的机器(包括集群内的机器及hadoop client)上执行(hadoop client搭建可参照http://www.cnblogs.com/pu20065226/p/8464867.html),读者也可在windows的eclipse上DFS-location ==>jh-hadoop==>user右键完成以下操作
7.3.1没有输入输出目录卡,先在hdfs上建个文件夹
hdfs dfs -mkdir –p /user/test22/input
7.3.2把要统计的文本上传到hdfs的输入目录下
[hadoop@hadoop-master hadoop-2.7.]$ pwd
/usr/hadoop/hadoop-2.7.
[hadoop@hadoop-master hadoop-2.7.]$ hdfs dfs -put etc/hadoop/*.sh /user/test22/input //将本地文件上传至hadoop集群/user/test22/input文件下
[hadoop@hadoop-master hadoop-2.7.5]$ hdfs dfs -ls /user/test22/input
Found 5 items
-rw-r--r-- 3 hadoop supergroup 4277 2018-03-16 02:02 /user/test22/input/hadoop-env.sh
-rw-r--r-- 3 hadoop supergroup 1449 2018-03-16 02:02 /user/test22/input/httpfs-env.sh
-rw-r--r-- 3 hadoop supergroup 1527 2018-03-16 02:02 /user/test22/input/kms-env.sh
-rw-r--r-- 3 hadoop supergroup 1383 2018-03-16 02:02 /user/test22/input/mapred-env.sh
-rw-r--r-- 3 hadoop supergroup 4567 2018-03-16 02:02 /user/test22/input/yarn-env.sh
[hadoop@hadoop-master hadoop-2.7.5]$
7.3.3查看
hdfs dfs -ls /user/test22/input
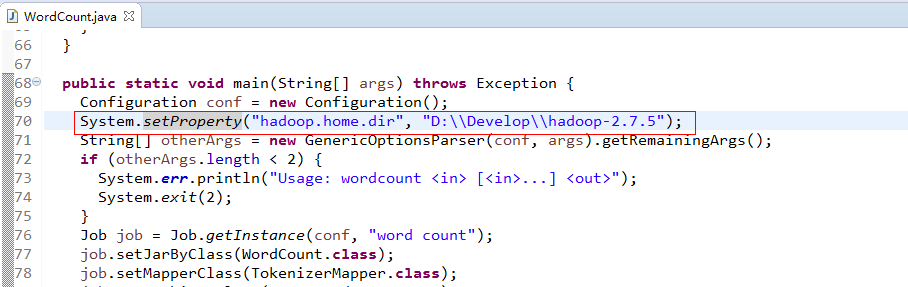
7.3.4设置hadoop.home.dir
在刚才已经新建MapReduce项目中的WordCount程序的main函数中添加如下图所示的内容:
(即 System.setProperty("hadoop.home.dir", "D:\\aaSoftware\\hadoop-2.5.2");其中:hadoop.home.dir是固定写法,因为程序中需要获取这个参数对应的值,也就是后面的hadop文件的路径。仅仅在程序中添加了这么一句代码,其他的都是hadoop源文件中自己的代码。)
7.4.点击WordCount.java右击-->Run As-->Run Configurations 设置输入和输出目录路径,如图所示:
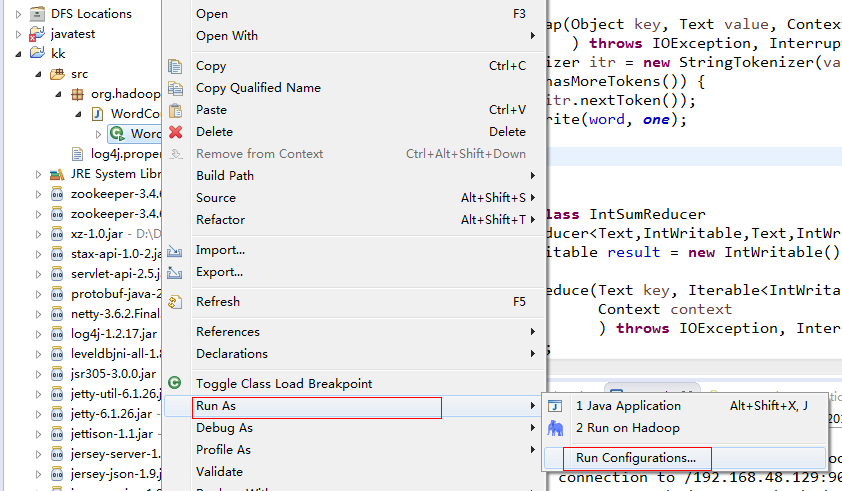



7.5.点击WordCount.java右击-->Run As-->Run on Hadoop
然后到output/count目录下,有一个统计文件,并查看结果,所以配置成功。

7.6报错Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String;I)V
解决:删除hadoop\bin\hadoop.dll,删除c:\windows\system32\hadoop.dll
参考:http://www.cnblogs.com/pu20065226/p/8583267.html
分析:http://blog.csdn.net/charKim/article/details/77113990
.注意的地方
我们在这篇介了,Eclipse连接Linux虚拟机上Hadoop并在Eclipse开发Hadoop的一些问题,解决Exception: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z 等一系列问题
hadoop-eclipse插件编译及windows下运行wordcount项目的更多相关文章
- hadoop 1.2.1 eclipse 插件编译
hadoop-1.2.1 eclipse插件编译 在ubuntu上进行hadoop相关的开发,需要在eclipse上安装hadoop开发插件.最新释放出的hadoop包含源码的包,以had ...
- Windows下运行Hadoop
Windows下运行Hadoop,通常有两种方式:一种是用VM方式安装一个Linux操作系统,这样基本可以实现全Linux环境的Hadoop运行:另一种是通过Cygwin模拟Linux环境.后者的好处 ...
- Hadoop学习笔记—6.Hadoop Eclipse插件的使用
开篇:Hadoop是一个强大的并行软件开发框架,它可以让任务在分布式集群上并行处理,从而提高执行效率.但是,它也有一些缺点,如编码.调试Hadoop程序的难度较大,这样的缺点直接导致开发人员入门门槛高 ...
- hadoop-1.2.0 eclipse插件编译
linux.windows下通用,亲测. 下面以window为例,假设:hadoop工程目录位于D:\work\eclipse64\hadoop-1.2.0.1.3.0.0,eclipse安装目录为E ...
- hadoop eclipse插件生成
hadoop eclipse插件生成 做了一年的hadoop开发.还没有自动生成过eclipse插件,一直都是在网上下载别人的用,今天有时间,就把这段遗憾补回来,自己生成一下,废话不说,開始了. 本文 ...
- Hadoop-2.3.0的Eclipse插件编译
Hadoop-2.3.0的Eclipse插件编译 #cd /usr/local/src/hadoop2x-eclipse-plugin-master/src/contrib/eclipse-plugi ...
- Faster_Rcnn在windows下运行踩坑总结
Faster_Rcnn在windows下运行踩坑总结 20190524 今天又是元气满满的一天! 1.代码下载 2.编译 3.下载数据集 4.下载pre-train Model 5.运行train ...
- # 如何在Windows下运行Linux程序
如何在Windows下运行Linux程序 一.搭建 Linux 环境 1.1 安装 VMware Workstation https://www.aliyundrive.com/s/TvuMyFdTs ...
- windows下运行的linux服务器批量管理工具(带UI界面)
产生背景: 由于做服务器运维方面的工作,需要一人对近千台LINUX服务器进行统一集中的管理,如同时批量对LINUX服务器执行相关的指令.同时批量对LINUX服务器upload程序包.同时批量对LINU ...
随机推荐
- PREV-9_蓝桥杯_大臣的旅费
问题描述 很久以前,T王国空前繁荣.为了更好地管理国家,王国修建了大量的快速路,用于连接首都和王国内的各大城市. 为节省经费,T国的大臣们经过思考,制定了一套优秀的修建方案,使得任何一个大城市都能从首 ...
- 编码知识梳理(UTF-8, Unicode, GBK, X509, ANSI, VIM中编码)
编码小结 1 初识编码 所谓编码,是信息从一种形式或格式转换为另一种形式的过程. 字符编码,从自然语言的字符的一个集合(如字母表或音节表),到其他东西的一个集合(如号码或电脉冲)的映射 ANSI:wi ...
- Unity单例
引自:http://www.unitymanual.com/thread-16916-1-1.html
- seo优化之域名泛解析优缺点分析
原文地址:http://www.phpddt.com/web/analysis-of-domain-name.html 自己也算半个SEOER,虽然没从事过优化工作,由于自己很感兴趣,每天还是会去看很 ...
- Zabbix 创建触发器
#1 配置 主机名10.0.0.33 触发器 点击创建触发器 #2 #4 点击添加 #触发器添加完毕
- qsort实现结构体数组排序
要注意强制转换 #include <stdio.h> #include <stdlib.h> typedef struct{ int num; char name[20]; f ...
- volley 之GsonRequest
这是之前写的http://www.cnblogs.com/freexiaoyu/p/3955137.html 关于GsonReques的用户,这个在POST请求传参数的时候GsonRequest构造第 ...
- git之win安装git和环境配置及常用命令总结
12.windowns安装git和环境变量配置 11.git之常见命令总结 ===== 12.windowns安装git和环境变量配置 ; 转自 https://wuzhuti.cn/2385.htm ...
- CRM 2016 刷新 Iframe
在CRM中刷新IFame: /// <summary>刷新Iframe的内容,用于表单上刷新iframe里的内容</summary> var iframe = Xrm.Page ...
- Apache poi简介及代码操作Excel
一.简介 在我们进行企业的系统开发时,难免会遇到网页表格和Excel之间的操作问题(POI是个不错的选择) Apache POI是Apache软件基金会的开放源码函式库,POI提供API给Java程序 ...