kmeans 聚类 k 值优化
kmeans 中k值一直是个令人头疼的问题,这里提出几种优化策略。
手肘法
核心思想
1. 肉眼评价聚类好坏是看每类样本是否紧凑,称之为聚合程度;
2. 类别数越大,样本划分越精细,聚合程度越高,当类别数为样本数时,一个样本一个类,聚合程度最高;
3. 当k小于真实类别数时,随着k的增大,聚合程度显著提高,当k大于真实类别数时,随着k的增大,聚合程度缓慢提升;
4. 大幅提升与缓慢提升的临界是个肘点;
5. 评价聚合程度的数学指标类似 mse,均方差,是每个类别的样本与该类中心的距离平方和比上样本数;
示例代码
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn.cluster import KMeans
from scipy.spatial.distance import cdist
# 1 数据可视化
cluster1 = np.random.uniform(0.5, 1.5, (2, 10))
cluster2 = np.random.uniform(3.5, 4.5, (2, 10))
X = np.hstack((cluster1, cluster2)).T
plt.figure()
plt.axis([0, 5, 0, 5])
plt.grid(True)
plt.plot(X[:, 0], X[:, 1], 'k.')
plt.show() # 2 肘部法求最佳K值
K = range(1, 10)
mean_distortions = []
for k in K:
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
mean_distortions.append(
sum(
np.min(
cdist(X, kmeans.cluster_centers_, metric='euclidean'), axis=1))
/ X.shape[0])
plt.plot(K, mean_distortions, 'bx-')
plt.xlabel('k')
font = FontProperties(fname=r'c:\windows\fonts\msyh.ttc', size=20)
plt.ylabel(u'平均畸变程度', fontproperties=font)
plt.title(u'用肘部法确定最佳的K值', fontproperties=font)
plt.show()
输出手肘图
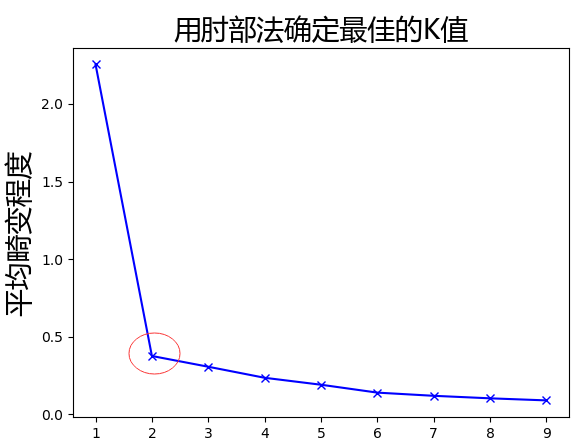
可以明显看出红色圆圈是个肘点。
缺点
1. 不是所有的数据都能呈现这样明显的肘点;
2. 单纯地以数据选择k值,可能脱离实际;
补充
在实际任务中,我们可能根据业务来确定 k 值,如区分男女,k=2,区分人种,k=3,黄黑白;
轮廓系数法
结合类内聚合度和类间分离度来评价聚类效果。
计算方法
1. 计算样本 i 到同簇内其他样本的平均距离 ai;【ai越小,说明该样本越应该被分到该簇,故可将 ai 视为簇内不相似度】
2. 计算簇内所有样本的 ai;
3. 计算样本 i 到其他簇内所有样本的平均距离 bi,并取min;【bi 视为 i 的类间不相似度,bi为i到其他类的所有bi中min,bi越大,越不属于其他类】
4. 样本 i 的簇内不相似度 ai 和类间不相似度 bi,计算轮廓系数
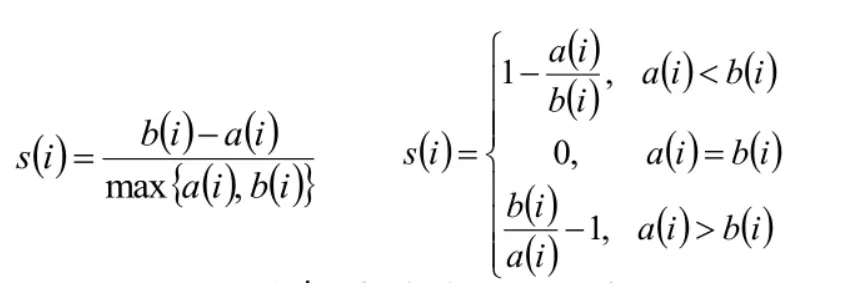
□ s_i 越接近1, 则说明样本 i 聚类合理。
□ s_i 越接近-1,说明样本 i 更适合聚到其他类
□ s_i 越接近0,则说明样本 i 在两个簇的边界上
这种方法计算量大,视情况使用。
参考资料:
https://blog.csdn.net/xiligey1/article/details/82457271
https://www.jianshu.com/p/f2b3a66188f1
kmeans 聚类 k 值优化的更多相关文章
- KMeans聚类 K值以及初始类簇中心点的选取 转
本文主要基于Anand Rajaraman和Jeffrey David Ullman合著,王斌翻译的<大数据-互联网大规模数据挖掘与分布式处理>一书. KMeans算法是最常用的聚类算法, ...
- 机器学习方法(七):Kmeans聚类K值如何选,以及数据重抽样方法Bootstrapping
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入.我的博客写一些自己用得到东西,并分享给 ...
- R语言中聚类确定最佳K值之Calinsky criterion
Calinski-Harabasz准则有时称为方差比准则 (VRC),它可以用来确定聚类的最佳K值.Calinski Harabasz 指数定义为: 其中,K是聚类数,N是样本数,SSB是组与组之间的 ...
- 转载: scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- kmeans聚类理论篇
前言 kmeans是最简单的聚类算法之一,但是运用十分广泛.最近在工作中也经常遇到这个算法.kmeans一般在数据分析前期使用,选取适当的k,将数据分类后,然后分类研究不同聚类下数据的特点. 本文记录 ...
- SparkMLlib聚类学习之KMeans聚类
SparkMLlib聚类学习之KMeans聚类 (一),KMeans聚类 k均值算法的计算过程非常直观: 1.从D中随机取k个元素,作为k个簇的各自的中心. 2.分别计算剩下的元素到k个簇中心的相异度 ...
- 数学建模及机器学习算法(一):聚类-kmeans(Python及MATLAB实现,包括k值选取与聚类效果评估)
一.聚类的概念 聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好.我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结 ...
- Kmeans算法的K值和聚类中心的确定
0 K-means算法简介 K-means是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一. K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的 ...
- 机器学习实战之 第10章 K-Means(K-均值)聚类算法
第 10 章 K-Means(K-均值)聚类算法 K-Means 算法 聚类是一种无监督的学习, 它将相似的对象归到一个簇中, 将不相似对象归到不同簇中.相似这一概念取决于所选择的相似度计算方法.K- ...
随机推荐
- Java 数组复制之clone方法
一.源码 public class Test1 { public static void main(String[] args) { // Student[] arrs = new Student[] ...
- shiro框架学习-2-springboot整合shiro及Shiro认证授权流程
1. 添加依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId> ...
- js-展开评论与隐藏评论
//控制展开评论和隐藏评论 controldiscuss(){ $(".opendiss").click(function(){ if($(this).context.innerH ...
- C2MIF软件使用说明
1.右击---管理员身份运行 2.打开文件txt---搞定!
- jquery lt选择器 语法
jquery lt选择器 语法 作用::lt 选择器选取带有小于指定 index 值的元素.index 值从 0 开始.经常与其他元素/选择器一起使用,来选择指定的组中特定序号之前的元素(如上面的例子 ...
- VSCode编辑器用户设置
{"gitlens.advanced.messages": {"suppressCommitHasNoPreviousCommitWarning": false ...
- memset设置最大值
初始化为最大值 memset(mp,0x7f,sizeof(mp));
- vue相关基础知识
参考文章: Vue 项目里戳中你痛点的问题及解决办法(更新) vue中前进刷新.后退缓存用户浏览数据和浏览位置的实践
- Windows操作系统Apache服务器下配置PHP
在Apache web服务器上发布PHP项目之前,需要进行相应的配置,服务器才能解析php文本,正常显示php动态页面内容.在进行php配置之前默认已经在Windows系统下安装好了Apache服务器 ...
- hibernate中的@GeneratedValue与@GenericGenerator
1.GeneratedValue与GenericGenerator的区别 @GeneratorValue注解----JPA通用策略生成器 @GenericGenerator注解----自定义主键生成策 ...