R语言中聚类确定最佳K值之Calinsky criterion
Calinski-Harabasz准则有时称为方差比准则 (VRC),它可以用来确定聚类的最佳K值。Calinski Harabasz 指数定义为:
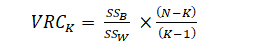
其中,K是聚类数,N是样本数,SSB是组与组之间的平方和误差,SSw是组内平方和误差。因此,如果SSw越小、SSB越大,那么聚类效果就会越好,即Calinsky criterion值越大,聚类效果越好。
1.下载permute、lattice、vegan包
install.packages(c("permute","lattice","vegan"))
2.引入permute、lattice、vegan包
library(permute)
library(lattice)
library(vegan)
3.读取数据
data <- read.csv("data/data.csv")
4.计算最佳K值
fit <- cascadeKM(data,,,iter=,criterion="calinski")
calinski.best <- as.numeric(which.max(fit$results[,]))
5.图片保存
png(file="data/calinskibest.png")
plot(fit, sortg = TRUE, grpmts.plot = TRUE)
dev.off()
6.截图

封装DetermineClustersNumHelper.R类
# ============================
# 确定最佳聚类K值 #
# ============================ # 引入包库
library(permute)
library(lattice)
library(vegan) # 获取最佳K值函数
get_best_calinski <- function(file_name){
# 获取故障数据
data <- read.csv(paste("data/km/",file_name,".csv",sep=""),header = T)
# 计算
fit <- cascadeKM(data,,,iter=,criterion="calinski")
calinski.best <- as.numeric(which.max(fit$results[,]))
# 保存图片
png(file=paste("data/km/",file_name,calinski.best,".png",sep=""))
plot(fit, sortg = TRUE, grpmts.plot = TRUE)
dev.off()
} # ========================================================================== # For example
#file_list <- array(c("failure_data_normalization","failure_normal_data_normalization"))
#for(file in file_list){
# # 调用函数
# get_best_calinski(file)
#} # ==========================================================================
R语言中聚类确定最佳K值之Calinsky criterion的更多相关文章
- R语言中的特殊值 NA NULL NaN Inf
这几个都是R语言中的特殊值,都是R的保留字, NA:Not available 表示缺失值 用 is.na() 来判断是否为缺失值 NULL:表示空值,即没有内容 用 is.null() 来判 ...
- R语言中样本平衡的几种方法
R语言中样本平衡的几种方法 在对不平衡的分类数据集进行建模时,机器学习算法可能并不稳定,其预测结果甚至可能是有偏的,而预测精度此时也变得带有误导性.在不平衡的数据中,任一算法都没法从样本量少的类中获取 ...
- R语言学习笔记1——R语言中的基本对象
R语言,一种自由软件编程语言与操作环境,主要用于统计分析.绘图.数据挖掘.R本来是由来自新西兰奥克兰大学的Ross Ihaka和Robert Gentleman开发(也因此称为R),现在由“R开发核心 ...
- 【R语言入门】R语言中的变量与基本数据类型
说明 在前一篇中,我们介绍了 R 语言和 R Studio 的安装,并简单的介绍了一个示例,接下来让我们由浅入深的学习 R 语言的相关知识. 本篇将主要介绍 R 语言的基本操作.变量和几种基本数据类型 ...
- 机器学习:R语言中如何使用最小二乘法
详细内容见上一篇文章:http://www.cnblogs.com/lc1217/p/6514734.html 这里只是介绍下R语言中如何使用最小二乘法解决一次函数的线性回归问题. 代码如下:(数据同 ...
- R语言中的数据处理包dplyr、tidyr笔记
R语言中的数据处理包dplyr.tidyr笔记 dplyr包是Hadley Wickham的新作,主要用于数据清洗和整理,该包专注dataframe数据格式,从而大幅提高了数据处理速度,并且提供了 ...
- R语言中的四类统计分布函数
R语言中提供了四类有关统计分布的函数(密度函数,累计分布函数,分位函数,随机数函数).分别在代表该分布的R函数前加上相应前缀获得(d,p,q,r).如: 1)正态分布的函数是norm,命令dnorm( ...
- R语言中的字符处理
R语言中的字符处理 (2011-07-10 22:29:48) 转载▼ 标签: r语言 字符处理 字符串 连接 分割 分类: R R的字符串处理能力还是很强大的,具体有base包的几个函数和strin ...
- R 语言中的数据结构
基本数据类型 6种 numaric 如 12, 12.4 integer 如 2L,0L complex 包含实数和虚数 如 3+2i character 要用双引号或者单引号包括起来 如 & ...
随机推荐
- 如何使用微信JS-SDK实际分享功能
http://jingyan.baidu.com/album/d3b74d64c517051f77e609ed.html?picindex=7
- 深入浅出MFC--第一章
Windows程序的生与死 当使用者按下系统菜单中的Close命令项,系统送出WM_CLOSE.通常程序的窗口函数不拦截次消息,于是DefWindowProc函数处理它.DefWindowProc收到 ...
- PHP学习记录第一篇:Ubuntu14.04下LAMP环境的搭建
最近一段时间会学习一下PHP全栈开发,将会写一系列的文章来总结学习的过程,以自勉. 第一篇记录一下LAMP环境的安装 0. 安装Apache Web服务器 安装之前先更新一下系统 sudo apt-g ...
- hdu1978(记忆化搜索)
#include<iostream> #include<stdio.h> #include<string.h> #include<queue> usin ...
- poj2559单调栈
题意:给出连续的矩形的高....求最大面积 #include<iostream> #include<stack> #include<stdio.h> using n ...
- androidStudio简便安装
最近在公司由eclipse换为androidstudio,说句实话,androidstudio还是蛮好用的,但是自己刚刚安装的时候遇到很多的问题,问了度娘,各种说法都有,还是捣鼓不得,于是自己尝试,弄 ...
- Bootstrap学习笔记(5)--实现Bootstrap导航条可点击和鼠标悬停显示下拉菜单
实现Bootstrap导航条可点击和鼠标悬停显示下拉菜单 微笑的鱼 2014-01-03 Bootstrap 5,281 次围观 11条评论 使用Bootstrap导航条组件时,如果你的导航条带有下拉 ...
- jquery清空textarea等输入框
转载自:http://blog.csdn.net/dyllove98/article/details/8870307 完整示例:http://www.keleyi.com/keleyi/phtml/c ...
- C语言 · 最大乘积
算法提高 最大乘积 时间限制:1.0s 内存限制:512.0MB 问题描述 对于n个数,从中取出m个数,如何取使得这m个数的乘积最大呢? 输入格式 第一行一个数表示数据组数 每组 ...
- openvpn 移植之buildroot添加相关选项
openvpn 移植第一步,在buildroot 内添加 openssl ,openvpn , 另外还有一个 RSA 的支持,我不确定这个需要程度如何,但是也添加进去了. buildroot 添加相关 ...