Dubbo 系列(07-2)集群容错 - 服务路由
Dubbo 系列(07-2)集群容错 - 服务路由
1. 背景介绍
相关文档推荐:
在上一节 Dubbo 系列(06-1)集群容错 - 服务字典 中分析服务字典的源码,服务字典是 Dubbo 集群容错的基础,这节只在服务字典的基础上继续分析服务路由策略。
Dubbo 服务路由分为条件路由 ConditionRouter、脚本路由 ScriptRouter 和标签路由 TagRouter。其中条件路由是我们最常使用的。
- 条件路由:用户使用 Dubbo 定义的语法规则定义路由规则;
- 文件路由:需要提交一个文件,里面定义的路由规则;
- 脚本路由:使用 JDK 自身的脚本引擎解析路由规则脚本。
路由配置规则: [服务消费者匹配条件] => [服务提供者匹配条件] 。 如果服务消费者匹配条件为空,表示不对服务消费者进行限制。如果服务提供者匹配条件为空,表示对某些服务消费者禁用服务。如 host = 10.20.153.10 => host = 10.20.153.11 ,表示 IP 为 10.20.153.10 的消费者会路由到 IP 为 10.20.153.11 的服务者。
1.1 继承体系
图1 Dubbo服务路由继承体系图
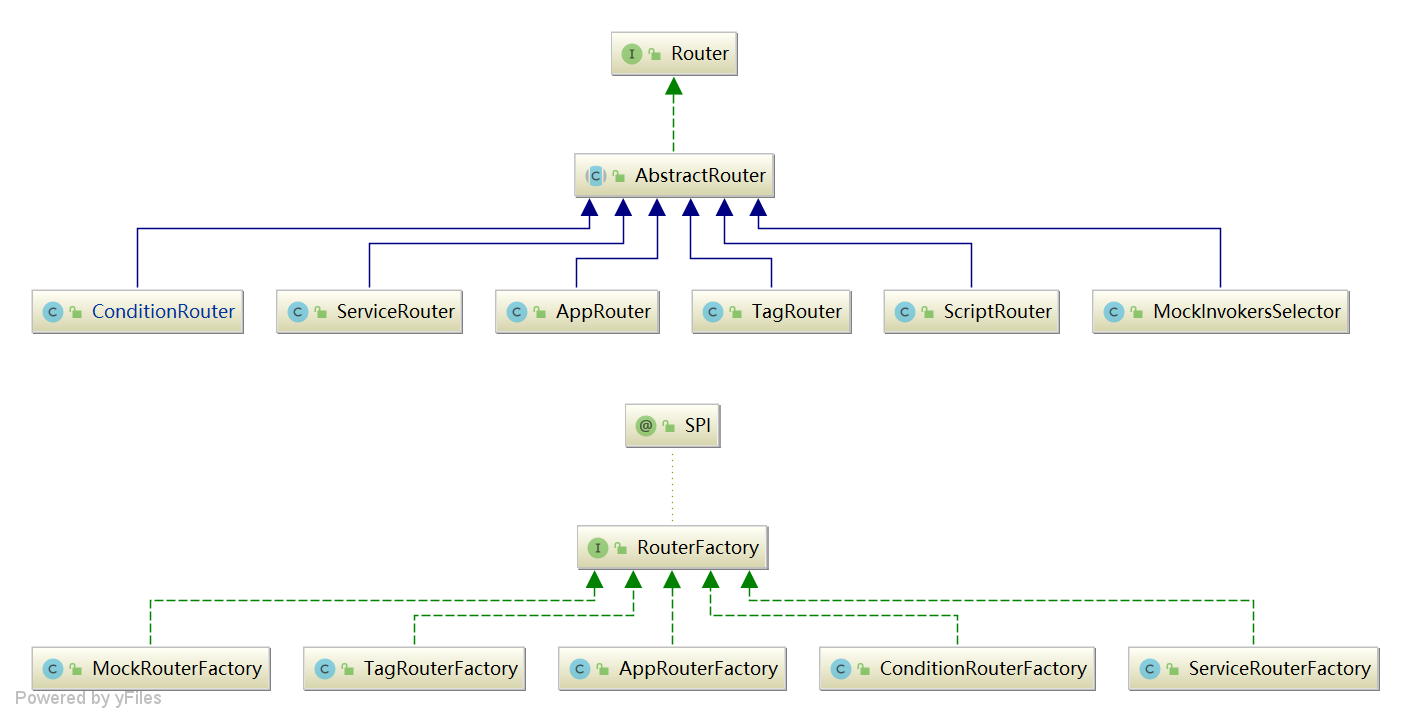
总结: Dubbo 设计的核心理念是:微内核富插件。和其它组件一样,路由策略也是通过 Dubbo SPI 动态生成的。每一个路由规则都对应一个工厂类,工厂类则是 SPI 自适应扩展点。
public interface Router extends Comparable<Router> {
<T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;
// routerUrl
URL getUrl();
boolean isForce();
...
}
总结: Router 最核心的方法是 route,会根据路由规则过滤 invokers,返回可用的 Invoker。
1.2 SPI
RouterFactory 是一个 SPI 接口,没有默认值,通过获取 URL.protocol 协议来创建对应的 Router 路由规则。
@SPI
public interface RouterFactory {
@Adaptive("protocol")
Router getRouter(URL url);
}
总结: 在 Dubbo-2.7.3 中默认的 org.apache.dubbo.rpc.cluster.RouterFactory 规则有以下几个。
file=org.apache.dubbo.rpc.cluster.router.file.FileRouterFactory
script=org.apache.dubbo.rpc.cluster.router.script.ScriptRouterFactory
condition=org.apache.dubbo.rpc.cluster.router.condition.ConditionRouterFactory
service=org.apache.dubbo.rpc.cluster.router.condition.config.ServiceRouterFactory
app=org.apache.dubbo.rpc.cluster.router.condition.config.AppRouterFactory
tag=org.apache.dubbo.rpc.cluster.router.tag.TagRouterFactory
mock=org.apache.dubbo.rpc.cluster.router.mock.MockRouterFactory
其中自适应扩展点有四个(也就是默认会加载的路由规则策略),按优先级依次为:mock > tag > app > service。
2. 源码分析
在上一节的分析服务字典源码时,当注册信息更新时会调用 notify 方法通知 RegistryDirectory 更新服务列表,其中一步就是根据配置的路由 routerURLs 解析 Router。先回顾一下之前的代码:
// 1. 路由规则创建
@Override
public synchronized void notify(List<URL> urls) {
// routerURLs
List<URL> routerURLs = categoryUrls.getOrDefault(ROUTERS_CATEGORY, Collections.emptyList());
toRouters(routerURLs).ifPresent(this::addRouters);
...
}
// 2. 路由规则使用,过滤 invokers
@Override
public List<Invoker<T>> doList(Invocation invocation) {
...
List<Invoker<T>> invokers = routerChain.route(getConsumerUrl(), invocation);
return invokers == null ? Collections.emptyList() : invokers;
}
总结: toRouters(routerURLs) 实际上在解析路由规则,如果有更新则重新设置 routeChain 的路由规则。而 doList 方法时会根据路由规则过滤服务。routeChain 会依次调用 routers,最终得到可用的 invokers。
2.1 创建路由规则
ROUTER_FACTORY 会读取 routerUrl.protocol 参数,决定使用那种路由策略,再根据 routerUrl.rule 参数解析对应的路由规则。
private static final RouterFactory ROUTER_FACTORY = ExtensionLoader.getExtensionLoader(RouterFactory.class)
.getAdaptiveExtension();
// routerUrl 中 router 定义路由类型,rule 定义具体的路由规则
private Optional<List<Router>> toRouters(List<URL> urls) {
if (urls == null || urls.isEmpty()) {
return Optional.empty();
}
List<Router> routers = new ArrayList<>();
for (URL url : urls) {
if (EMPTY_PROTOCOL.equals(url.getProtocol())) {
continue;
}
// 将 url.router 参数设置为 protocol
String routerType = url.getParameter(ROUTER_KEY);
if (routerType != null && routerType.length() > 0) {
url = url.setProtocol(routerType);
}
try {
Router router = ROUTER_FACTORY.getRouter(url);
if (!routers.contains(router)) {
routers.add(router);
}
} catch (Throwable t) {
logger.error("convert router url to router error, url: " + url, t);
}
}
return Optional.of(routers);
}
总结: toRouters 最核心的代码就是 Router router = ROUTER_FACTORY.getRouter(url) 创建路由规则。路由规则类型是由 url.router 决定的。
2.2 RouteChain
RouteChain 用于管理所有的路由规则,内部维护有几个重要的集合:
// 1. Dubbo 内部默认的路由规则(四种):
// MockInvokersSelector > TagRouter > AppRouter > ServiceRouter
private List<Router> builtinRouters = Collections.emptyList();
// 2. 自定义的路由规则
private volatile List<Router> routers = Collections.emptyList();
// 3. 所有可用的服务(Invoker 可简单理解为一个可执行的服务)
private List<Invoker<T>> invokers = Collections.emptyList();
2.2.1 内建路由规则
RouterChain#buildChain 会调用私有的构造函数,在初始化时会创建默认的路由规则。
// url: 订阅者URL
// 默认有四个路由规则:MockInvokersSelector/TagRouter/AppRouter/ServiceRouter
private RouterChain(URL url) {
List<RouterFactory> extensionFactories = ExtensionLoader.getExtensionLoader(RouterFactory.class)
.getActivateExtension(url, (String[]) null);
// 创建内建的路由规则
List<Router> routers = extensionFactories.stream()
.map(factory -> factory.getRouter(url))
.collect(Collectors.toList());
initWithRouters(routers);
}
public void initWithRouters(List<Router> builtinRouters) {
this.builtinRouters = builtinRouters;
this.routers = new ArrayList<>(builtinRouters);
this.sort();
}
2.2.2 更新路由规则
当路由规则更新时会调用 addRouters 更新路由规则,更新时仍保留内建的路由规则。
public void addRouters(List<Router> routers) {
List<Router> newRouters = new ArrayList<>();
newRouters.addAll(builtinRouters);
newRouters.addAll(routers);
CollectionUtils.sort(newRouters);
this.routers = newRouters;
}
总结: 可以看到 builtinRouters 内建的路由规则仍会保留,路由规则的会通过排序来保证执行顺序。其实 Spring 的 BeanPostProcessor 也是保存在一个 List 中通过排序来保证执行顺序的。路由规则的更新是在 RegistryDirectory#notify 通知时。
2.2.3 更新服务列表
同路由规则的更新一样,也是在 RegistryDirectory#notify 时更新服务列表。
public void setInvokers(List<Invoker<T>> invokers) {
this.invokers = (invokers == null ? Collections.emptyList() : invokers);
routers.forEach(router -> router.notify(this.invokers));
}
2.2.4 执行服务路由
public List<Invoker<T>> route(URL url, Invocation invocation) {
List<Invoker<T>> finalInvokers = invokers;
for (Router router : routers) {
finalInvokers = router.route(finalInvokers, url, invocation);
}
return finalInvokers;
}
总结: 逐个调用 Router 进行路由,这个就很简单了。
2.3 条件路由
路由规则使用见 Dubbo 路由使用手册。
"condition://0.0.0.0/org.apache.demo.DemoService?category=routers&dynamic=false&rule=" + URL.encode("host=10.20.153.10 => host=10.20.153.11")
2.3.1 条件路由规则解析
在 ConditionRouterFactory#getRouter(URL url) 直接 new ConditionRouter(url) 后就返回了,Dubbo SPI 的工厂类一般都很简单。
public ConditionRouter(URL url) {
this.url = url;
this.priority = url.getParameter(PRIORITY_KEY, 0); // 优先级
this.force = url.getParameter(FORCE_KEY, false); // 过滤后没有服务可用,是否强制执行
this.enabled = url.getParameter(ENABLED_KEY, true); // enabled是否启动
init(url.getParameterAndDecoded(RULE_KEY)); // 解析路由规则 url.rule
}
总结: ConditionRouter 解析 url.rule 配置的路由规则。条件路由配置示例如下:host = 10.20.153.10 => host = 10.20.153.11,左侧是消费者配置规则,右侧是服务者配置规则,表示消费者 host=10.20.153.10 会路由到服务者 host=10.20.153.11。
// host = 10.20.153.10 => host = 10.20.153.11
public void init(String rule) {
try {
if (rule == null || rule.trim().length() == 0) {
throw new IllegalArgumentException("Illegal route rule!");
}
rule = rule.replace("consumer.", "")
.replace("provider.", "");
int i = rule.indexOf("=>");
String whenRule = i < 0 ? null : rule.substring(0, i).trim();
String thenRule = i < 0 ? rule.trim() : rule.substring(i + 2).trim();
// 消费者规则解析
Map<String, MatchPair> when = StringUtils.isBlank(whenRule) || "true".equals(whenRule) ?
new HashMap<String, MatchPair>() : parseRule(whenRule);
// 服务者规则解析
Map<String, MatchPair> then = StringUtils.isBlank(thenRule) || "false".equals(thenRule) ?
null : parseRule(thenRule);
this.whenCondition = when;
this.thenCondition = then;
} catch (ParseException e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
总结: 在 ConditionRouter 中使用两个 Map 保存了对应的匹配规则,最终解析都是在 parseRule(thenRule) 方法中完成的。
Map<String, MatchPair> when;
Map<String, MatchPair> then;
private static final class MatchPair {
final Set<String> matches = new HashSet<String>();
final Set<String> mismatches = new HashSet<String>();
}
这个 Map 的 key 表示匹配项,最终将匹配规则解析成如下结构:
// host = 2.2.2.2 & host != 1.1.1.1 & method = hello
{
"host": {
"matches": ["2.2.2.2"],
"mismatches": ["1.1.1.1"]
},
"method": {
"matches": ["hello"],
"mismatches": []
}
}
2.3.2 执行条件路由
执行条件路由其实就是路由规则的匹配过程:
- 如果禁用路由规则,直接返回原列表。
- 如果服务消费者匹配上,就匹配其可用的服务列表。
- 服务消费者匹配条件为空,表示不对服务消费者进行限制。
- 如果服务提供者匹配条件为空,表示对某些服务消费者禁用服务。
- 如果匹配后没有可用的服务,force=true表示强制执行路由规则,返回空列表,否则返回原列表。
@Override
public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException {
// 1.1 禁用路由规则
if (!enabled) {
return invokers;
}
// 1.2 没有可用的服务
if (CollectionUtils.isEmpty(invokers)) {
return invokers;
}
try {
// 先对服务消费者条件进行匹配,如果匹配失败,表明服务消费者 url 不符合匹配规则,
// 无需进行后续匹配,直接返回 Invoker 列表即可。比如下面的规则:
// host = 10.20.153.10 => host = 10.0.0.10
// 这条路由规则希望 IP 为 10.20.153.10 的服务消费者调用 IP 为 10.0.0.10 机器上的服务。
// 当消费者 ip 为 10.20.153.11 时,matchWhen 返回 false,表明当前这条路由规则不适用于
// 当前的服务消费者,此时无需再进行后续匹配,直接返回即可。
// 2.1 消费者规则无法匹配,表示不对服务消费者进行限制
if (!matchWhen(url, invocation)) {
return invokers;
}
List<Invoker<T>> result = new ArrayList<Invoker<T>>();
// 2.2 服务者规则放弃匹配,表明对指定的服务消费者禁用服务
if (thenCondition == null) {
return result;
}
// 2.3 服务提供者匹配规则,匹配成功表示进行服务路由
for (Invoker<T> invoker : invokers) {
// 若匹配成功,表明当前 Invoker 符合服务提供者匹配规则
if (matchThen(invoker.getUrl(), url)) {
result.add(invoker);
}
}
// 2.4 匹配后没有服务可用,是否强制执行,也就是没有服务可用
// force=false 表示路由规则将自动失效
if (!result.isEmpty()) {
return result;
} else if (force) {
return result;
}
} catch (Throwable t) {
}
// 2.5 出现异常或force=false,表示该条路由规则失效
return invokers;
}
总结: 具体的匹配逻辑都委托给了 matchWhen(url, invocation) 方法。
关于条件路由,规则的解析和具体的匹配过程都没有深入分析,目前来说,了解路由规则的整个运行流程更重要,如果以后用到 Dubbo 的路由规则,出了问题再做具体的深入研究,现在就到此为至。感兴趣的朋友可以参考:Dubbo 源码解读 - 服务路由。
每天用心记录一点点。内容也许不重要,但习惯很重要!
Dubbo 系列(07-2)集群容错 - 服务路由的更多相关文章
- Dubbo 系列(07-1)集群容错 - 服务字典
Dubbo 系列(07-1)集群容错 - 服务字典 [toc] Spring Cloud Alibaba 系列目录 - Dubbo 篇 1. 背景介绍 本篇文章,将开始分析 Dubbo 集群容错方面的 ...
- Dubbo 源码分析 - 集群容错之 LoadBalance
1.简介 LoadBalance 中文意思为负载均衡,它的职责是将网络请求,或者其他形式的负载"均摊"到不同的机器上.避免集群中部分服务器压力过大,而另一些服务器比较空闲的情况.通 ...
- Dubbo 源码分析 - 集群容错之 Cluster
1.简介 为了避免单点故障,现在的应用至少会部署在两台服务器上.对于一些负载比较高的服务,会部署更多台服务器.这样,同一环境下的服务提供者数量会大于1.对于服务消费者来说,同一环境下出现了多个服务提供 ...
- Dubbo 源码分析 - 集群容错之 Router
1. 简介 上一篇文章分析了集群容错的第一部分 -- 服务目录 Directory.服务目录在刷新 Invoker 列表的过程中,会通过 Router 进行服务路由.上一篇文章关于服务路由相关逻辑没有 ...
- Dubbo工作原理,集群容错,负载均衡
Remoting:网络通信框架,实现了sync-over-async和request-response消息机制. RPC:一个远程过程调用的抽象,支持负载均衡.容灾和集群功能. Registry:服务 ...
- Dubbo 源码分析 - 集群容错之 Directory
1. 简介 前面文章分析了服务的导出与引用过程,从本篇文章开始,我将开始分析 Dubbo 集群容错方面的源码.这部分源码包含四个部分,分别是服务目录 Directory.服务路由 Router.集群 ...
- Dubbo负载均衡与集群容错机制
1 Dubbo简介 Dubbo是一款高性能.轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现. 作为一个轻量级RPC框架,D ...
- dubbo源码分析- 集群容错之Cluster(一)
1.集群容错的配置项 failover - 失败自动切换,当出现失败,重试其他服务器(缺省),通常用于读操作,但重试会带来更长的延时. failfast - 快速失效,只发起一次调用,失败立即报错.通 ...
- Dubbo的10种集群容错模式
学习Dubbo源码的过程中,首先看到的是dubbo的集群容错模式,以下简单介绍10种集群容错模式 1.AvailableCluster 顾名思义,就是可用性优先,遍历所有的invokers,选择可用的 ...
随机推荐
- 2. ZooKeeper基础
1. ZooKeeper的特性 ZooKeeper的特性主要从会话.数据节点,版本,Watcher,ACL权限控制,集群角色这些部分来了解,其中需要重点掌握的数据节点与Watcher 1.1 会话 客 ...
- RestController和Controller的区别
知识点:@RestController注解相当于@ResponseBody + @Controller合在一起的作用. 1) 如果只是使用@RestController注解Controller,则Co ...
- es5和es6中的this指向问题
const test ={ id:2, a:function(){ var a_this=this; setTimeout(function(){ console.log('a:',this,a_th ...
- 【知识强化】第三章 存储系统 3.4 主存储器与CPU的连接
我们这节课来看一下关于主存的一些知识.我们将要讲解主存的简单的模型和主存与CPU连接的连接原理. 我们之前呢在第一章已经学过了存储器的构成,包括了存储体.MAR(也就是地址寄存器).MDR(也就是数据 ...
- linux性能分析工具Cpu
- linux的定时任务--crontab
cron是一个linux下的定时执行工具,可以在无需人工干预的情况下运行作业.由于Cron 是Linux的内置服务,但它不自动起来,可以用以下的方法启动.关闭这个服务: /sbin/service c ...
- Java EE会话技术Cookie和Session
会话技术 一.定义 会话技术是帮助服务器记住客户端状态的(区分客户端的).将客户访问的信息存在本地的叫Cookie技术,存在服务器上的叫Session技术. 注意: 一次会话何时开始?从打开一个浏览器 ...
- find按照文件大小查找
例如,find -size +1M:查找大于 1 MB 的文件.其他参数: b: 512-byte blocks. This is the default if no unit is specifie ...
- Vue $ref 的用法
<div id="app"> <cpn $ref="item"></cpn> <cpn></cpn> ...
- Redis原理及拓展
Redis是单线程程序.单线程的Redis为何还能这么快? 1.所有的数据都在内存中,所有的运算都是内存级别的运算(因此时间复杂度为O(n)的指令要谨慎使用) 2.单线程操作,避免了频繁的上下文切换 ...