Apache Flink 介绍
本文简单介绍一下Flink,部分内容来源于网络,想深入了解Flink的读者可以参照官方文档深入学习Apache Flink。
流计算
在介绍Flink之前首先说一下流计算的概念,流计算是针对流式数据的实时计算。
- 流式数据是指将数据看作数据流的形式来处理,数据流是在时间分布和数量上无限的一系列动态数据集合体,数据记录是数据流的最小组成单元。
- 流数据具有数据实时持续不断到达、到达次序独立、数据来源众多格式复杂、数据规模大且不十分关注存储、注重数据的整体价值而不关注个别数据等特点。
Apache Flink是什么
Apache Flink是一个分布式流批一体化的开源平台。Flink的核心是一个提供数据分发、通信以及自动容错的流计算引擎。Flink在流计算之上构建批处理,并且原生的支持迭代计算、内存管理以及程序优化。官方称之为Stateful Computations over Data Streams,即数据流上有状态计算。官方对Flink的详细介绍What is Apache Flink。
Flink的特点
现有的开源计算方案会把流处理和批处理作为两种不同的应用类型(如Apache Storm只支持流处理,Apache Spark只支持批(Micro Batching)处理),流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效率。Flink同时支持流处理和批处理,作为流处理时输入数据流是无界的,批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
Flink重要基石
Apache Flink的四个重要基石:Checkpoint、State、Time、Window
- Checkpoint:基于Chandy-Lamport算法实现了分布式一致性快照,提供了一致性的语义
- State:丰富的State API,包括ValueState、ListState、MapState、BoardcastState
- Time:实现了Watermark机制,能够支持基于事件的时间的处理,能够容忍数据的延时、迟到和乱序
- Window:开箱即用的窗口,滚动窗口、滑动窗口、会话窗口和灵活的自定义窗口
Flink的优势
- 支持高吞吐、低延迟、高性能的流数据处理
- 支持高度灵活的窗口(Window)操作
- 支持有状态计算的Exactly-once语义
- 提供DataStream API和DataSet API
适用场景
Flink支持下面这三种最常见类型的应用示例,官网有详细的介绍Use Cases。
- 事件驱动的应用程序
- 数据分析应用
- 数据管道应用
基础架构
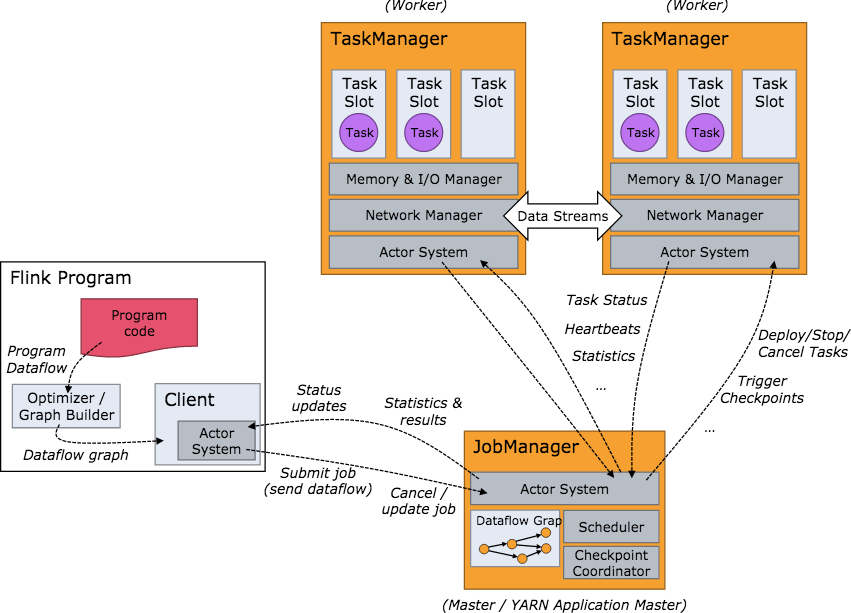
Flink集群启动后,首先会启动一个JobManger和一个或多个TaskManager。由Client提交任务给JobManager,JobManager再调度任务到各个TaskManager去执行,然后TaskManager将心跳和统计信息汇报给JobManager,TaskManager之间以流的形式进行数据的传输。JobManager、TaskManager和Client均为独立的JVM进程。
- JobManager是系统的协调者,负责接收Job,调度组成Job的多个Task的执行,收集Job的状态信息,管理Flink集群中的TaskManager。
- TaskManager是实际负责执行计算的Worker,并负责管理其所在节点的资源信息,在启动的时候将资源的状态向JobManager汇报。
- Client负责提交Job,可以运行在任何与JobManager环境连通的机器上,提交Job后,Client可以结束进程,也可以不结束并等待结果返回。
基本编程模型
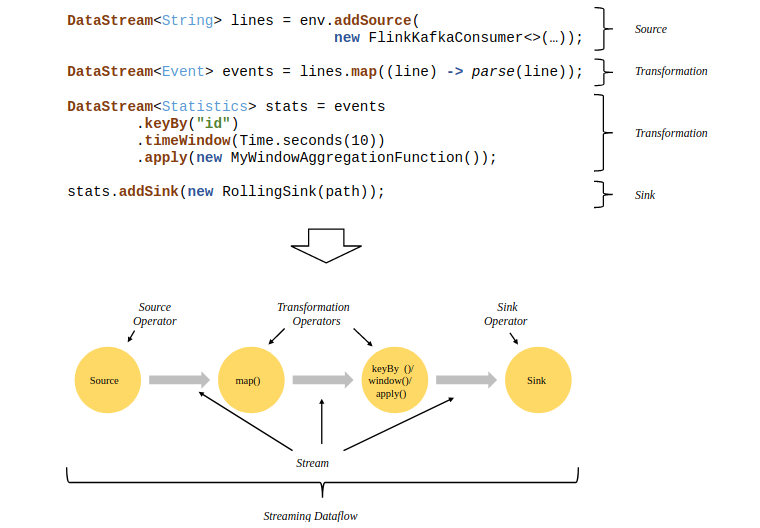
Flink程序的基础构建模块是流(streams)与转换(transformations),每一个数据流都起始于一个或多个source,并终止于一个或多个sink,下面是一个由Flink程序映射为Streaming Dataflow的示意图:
容错机制
Flink的容错机制的核心部分是分布式数据流和operator state的一致性快照,系统发生故障的时候这些快照可以充当一致性检查点来退回,恢复作业的状态和计算位置等。官网有详细介绍Data Streaming Fault Tolerance。
- Checkpointing
- Recovery
- Operator Snapshot Implementation
Apache Flink 介绍的更多相关文章
- Flink 从0到1学习 —— Flink 中如何管理配置?
前言 如果你了解 Apache Flink 的话,那么你应该熟悉该如何像 Flink 发送数据或者如何从 Flink 获取数据.但是在某些情况下,我们需要将配置数据发送到 Flink 集群并从中接收一 ...
- Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
前言 之前也分享了不少自己的文章,但是对于 Flink 来说,还是有不少新入门的朋友,这里给大家分享点 Flink 相关的资料(国外数据 pdf 和流处理相关的 Paper),期望可以帮你更好的理解 ...
- Flink 从 0 到 1 学习 —— Flink 配置文件详解
前面文章我们已经知道 Flink 是什么东西了,安装好 Flink 后,我们再来看下安装路径下的配置文件吧. 安装目录下主要有 flink-conf.yaml 配置.日志的配置文件.zk 配置.Fli ...
- Flink 从 0 到 1 学习 —— 如何自定义 Data Sink ?
前言 前篇文章 <从0到1学习Flink>-- Data Sink 介绍 介绍了 Flink Data Sink,也介绍了 Flink 自带的 Sink,那么如何自定义自己的 Sink 呢 ...
- Flink 从 0 到 1 学习 —— 如何自定义 Data Source ?
前言 在 <从0到1学习Flink>-- Data Source 介绍 文章中,我给大家介绍了 Flink Data Source 以及简短的介绍了一下自定义 Data Source,这篇 ...
- Flink 从 0 到 1 学习 —— Flink Data transformation(转换)
toc: true title: Flink 从 0 到 1 学习 -- Flink Data transformation(转换) date: 2018-11-04 tags: Flink 大数据 ...
- Apache Flink 1.5.0 Release Announcement
Apache Flink: Apache Flink 1.5.0 Release Announcement https://flink.apache.org/news/2018/05/25/relea ...
- 当Atlas遇见Flink——Apache Atlas 2.2.0发布!
距离上次atlas发布新版本已经有一年的时间了,但是这一年元数据管理平台的发展一直没有停止.Datahub,Amundsen等等,都在不断的更新着自己的版本.但是似乎Atlas在元数据管理,数据血缘领 ...
- 企业实践 | 如何更好地使用 Apache Flink 解决数据计算问题?
业务数据的指数级扩张,数据处理的速度可不能跟不上业务发展的步伐.基于 Flink 的数据平台构建.运用 Flink 解决业务场景中的具体问题等随着 Flink 被更广泛的应用于广告.金融风控.实时 B ...
- Stream processing with Apache Flink and Minio
转自:https://blog.minio.io/stream-processing-with-apache-flink-and-minio-10da85590787 Modern technolog ...
随机推荐
- Hessian基础入门案例
Hessian是一个轻量级的remoting onhttp工具,使用简单的方法提供了RMI的功能. 相比WebService,Hessian更简单.快捷.采用的是二进制RPC协议,因为采用的是二进制协 ...
- dubbo-admin和dubbo-monitor的安装
一.安装dubbo-admin 去这里 http://download.csdn.net/download/u013081610/10044744 下载dubbo-admin.war 部署dubbo- ...
- 网络IO和磁盘IO详解
1. 缓存IO 缓存I/O又被称作标准I/O,大多数文件系统的默认I/O操作都是缓存I/O.在Linux的缓存I/O机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址 ...
- setInterval setTimeout 详解
JavaScript的setTimeout与setInterval是两个很容易欺骗别人感情的方法,因为我们开始常常以为调用了就会按既定的方式执行, 我想不少人都深有同感, 例如 setTimeout( ...
- app后端设计(4)-- 通讯的安全性
在app的后台设计中,一个很重要的因素是考虑通讯的安全性. 因此,我们需要考虑的要点有: 1. 在app和后台,都不能保存任何用户密码的明文 2. 在app和后台通讯的过程中,怎么保证用户信息的安全性 ...
- Java 开发, volatile 你必须了解一下
上一篇文章说了 CAS 原理,其中说到了 Atomic* 类,他们实现原子操作的机制就依靠了 volatile 的内存可见性特性.如果还不了解 CAS 和 Atomic*,建议看一下我们说的 CAS ...
- (二)Web应用体系结构
容器 Servlet没有main()方法,它们受控于另一个Java应用,这个Java应用称为容器(Container).我们最常见的tomcat就是这样一个容器. Web服务器应用(如Apache)得 ...
- 内连接查询 (select * from a join b on a.id = b.id) 与 关联查询 (select * from a , b where a.id = b.id)的区别
转自https://blog.csdn.net/l690781365/article/details/76261093 1.首先了解 on .where 的执行顺序以及效率? from a join ...
- 【莫比乌斯反演】BZOJ2005 [NOI2010]能量采集
Description 求sigma gcd(x,y)*2-1,1<=x<=n, 1<=y<=m.n, m<=1e5. Solution f(n)为gcd正好是n的(x, ...
- bzoj 2510 弱题 矩阵乘
看题就像矩阵乘 但是1000的数据无从下手 打表发现每一行的数都是一样的,只不过是错位的,好像叫什么循环矩阵 于是都可以转化为一行的,O(n3)->O(n2)*logk #include< ...