class-逻辑回归与最大熵模型
1.1 logistic distribution
1.2 binary logistic regression model
1.3 模型参数估计
1.4 multi-nominal logistic regression model
2 最大熵模型
2.1 最大熵原理
2.2 最大熵模型定义
2.3 最大熵模型的学习training
2.4 极大似然估计
3 模型训练算法
3.1 改进迭代尺度法(IIS)
3.2 拟牛顿法
logistic regression和maximum entropy model 都属于对数线性模型。
1 logistic regression model
1.1 logistic distribution
定义:设X是连续分布随机变量,X服从logistic distribution是指具有下列分布函数和密度函数:
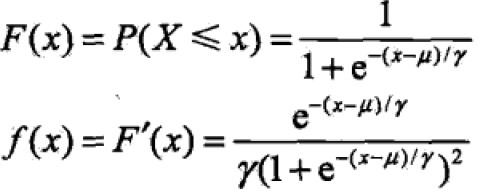
where,μ为位置参数,γ>0为形状参数。
分布曲线:
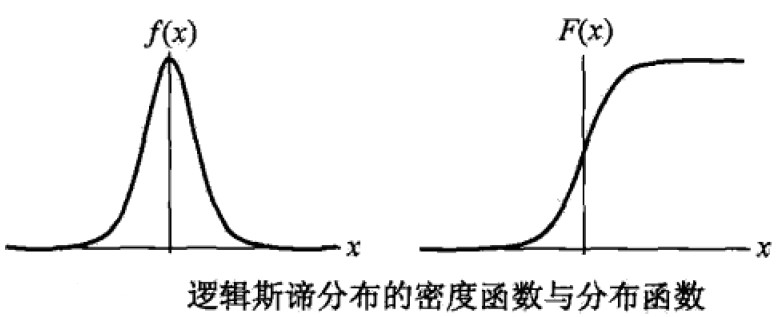
F(x)为S型曲线(sigmoid curve),以(μ,1/2)中心对称,即: ,γ越小中间位置增长越快。
,γ越小中间位置增长越快。
1.2 binary logistic regression model
二项逻辑回归模型是一种分类模型,用条件概率P(Y|X)表示,X取值为实数,Y取值为0或1。通过监督学习来估计模型参数。
条件概率分布:

where,x属于Rn是输入,Y属于{0,1},w是权值向量,b是偏置,w·x是内积inner product。
逻辑回归是对于给定的输入实例x求得P(Y=1|x)和P(Y=0|x)的概率,取概率较大者的类别作为x的分类。
为了简化将w,x扩充为w=(w1,w2,…,wn,b),x=(x1,x2,…,xn,1),则logistic distribution为:

一个事件的几率odds是指该事件发生的概率与不发生的概率比值,若发生为p,则几率为p/(1-p),该事件的对数几率log odds为: 。
。
代入上式可得:
说明:输出Y=1的对数几率是输入x的线性函数,对输入x分类的线性函数w·x其值域为实数域,线性函数的值越接近于无穷,概率值就越接近于1,线性函数的值越接近负无穷概率值就越接近于0,这就是逻辑回归model。
1.3 模型参数估计

这样,目标函数变为对数似然函数为目标函数的最优化问题,常用gradient descent 或者拟牛顿法求解,那么学到的model是:w hat是w的最大似然估计值

似然函数的理解1
wiki百科
似然函数就是likelihood function,似然也是一种概率,但是是对已知结果对参数预测进行估计。更大的作用在于当参数变化时似然性的改变,变大就更有“说服力”。
1.4 multi-nominal logistic regression model
与1.2的区别就是Y取值为{1,2,3,…,K},参数估计法也是类似的。
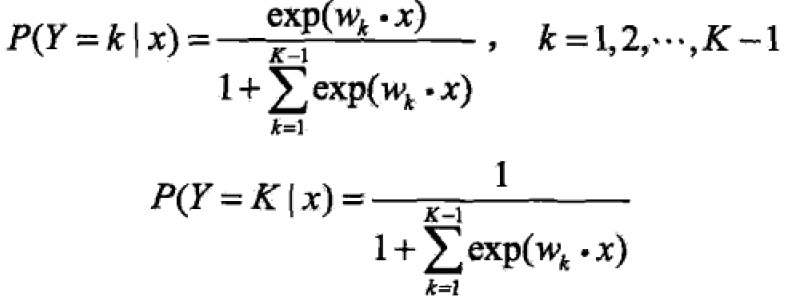
推荐阅读:http://blog.jobbole.com/88521/
https://www.cnblogs.com/sparkwen/p/3441197.html
2 最大熵模型
2.1 最大熵原理
最大熵原理经过推导将得到最大熵模型,其实它是一个概率模型的学习准则。最大熵原理认为学习概率模型时,在所有可能model中,熵最大的model是最好的model,若有约束条件,则是在此条件下选取熵最大的model。
假设离散随机变量X的概率分布为P(X),其熵为: ,满足
,满足 。
。
where,|X|是X的取值个数,当且仅当 X满足均匀分布时等号成立,即均匀分布熵最大。
首先要满足已有事实即约束条件,如果没有别的条件时(如果仅有概率和为1)不确定信息就通过熵的最大化来表示等可能(均匀分布,等可能概率)。
2.2 最大熵模型定义
目标是利用最大熵原理选择最好的分类模型。
考虑模型应该满足的条件:训练集T={{(x1,y1),…(xN,yN)}};可以确定联合概率分布P(X=x,Y=y),边缘概率分布P(X=x):
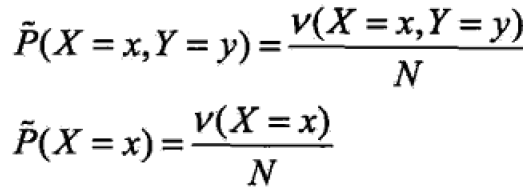 ν是出现的频次,N是总样本数(通过频率来表示概率)
ν是出现的频次,N是总样本数(通过频率来表示概率)
特征函数(feature function):f(x,y)描述输入x与输出y之间的某一事实。定义为:

特征函数与经验分布的期望值: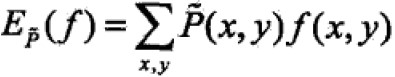 ;
;
进而特征函数关于模型P(Y|X)与经验分布的P(X=x)期望值: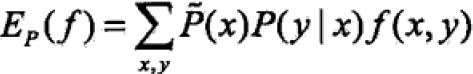 ;
;
注:若model能够获取训练数据的信息,那么可以假设这两个期望值相等——这就是model学习的约束条件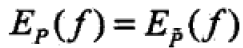 ,其中有n个特征函数就有n个约束条件。
,其中有n个特征函数就有n个约束条件。
最大熵模型:假设所有满足约束条件的模型集合:

定义在条件概率分布P(Y|X)上的条件熵为:
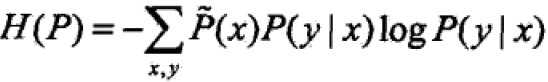
其中,集合C中条件熵H(P)最大的模型称为最大熵模型,对数为自然对数。
2.3 最大熵模型的学习training
最大熵模型的学习就是求解最大熵模型的过程,即约束条件下找最优化的问题(约束最优化)。
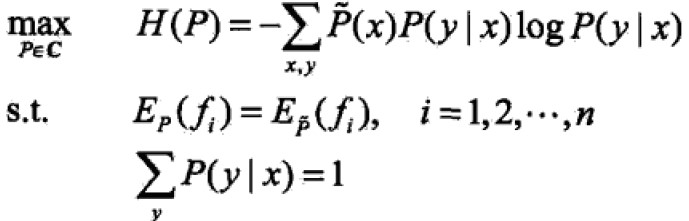 等价于
等价于
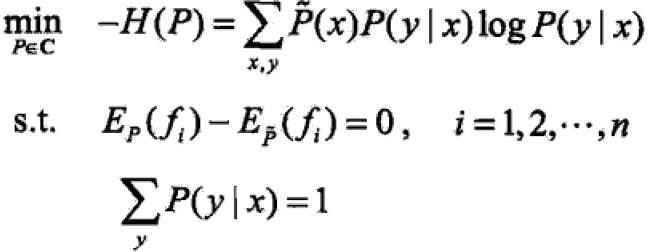
展示推导过程:
首先引入拉格朗日函数L(p,w)将约束问题转化为无约束最优化的对偶问题:
 (可以发现跟高数中拉格朗日乘数法类似)
(可以发现跟高数中拉格朗日乘数法类似)
将原始问题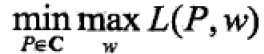 转化为
转化为 的对偶问题。
的对偶问题。
求解对偶问题:
首先求解min部分,记作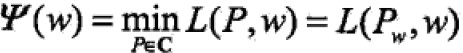 ,其解记作
,其解记作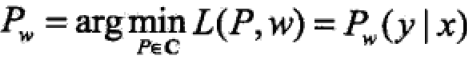
最小化问题就是求解其偏导=0,即
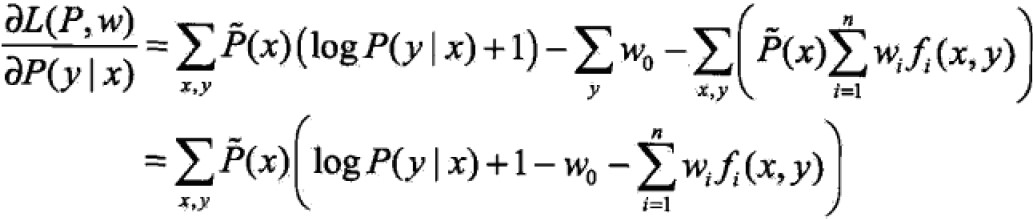
当P(x)>0时,Pw的解为:
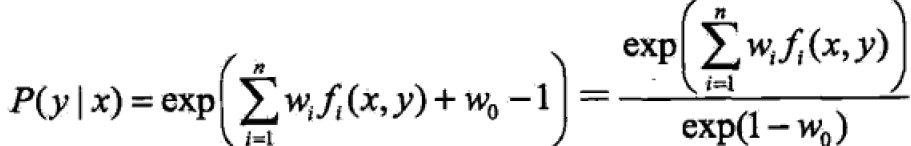
根据summation(P(y|x))=1,消去分母得
 其中,
其中,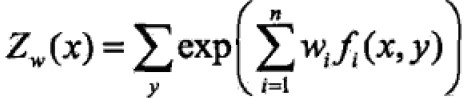
where,Zw(x)称为规范化因子,fi(x,y)是特征函数;wi是特征的权值。由上式表示的模型就是最大熵模型Pw,w是最大熵模型的参数向量。
其次求解max部分, ,将其解记为w star:
,将其解记为w star: ,通过最优化算法求对偶函数ψ(w)的极大化
,通过最优化算法求对偶函数ψ(w)的极大化
2.4 极大似然估计
证明:对偶函数的极大化等价于最大熵模型的极大似然估计
对数似然函数: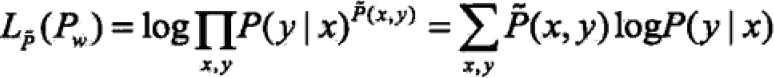
最大熵模型下,代入P(y|x)得到:
 ;
;
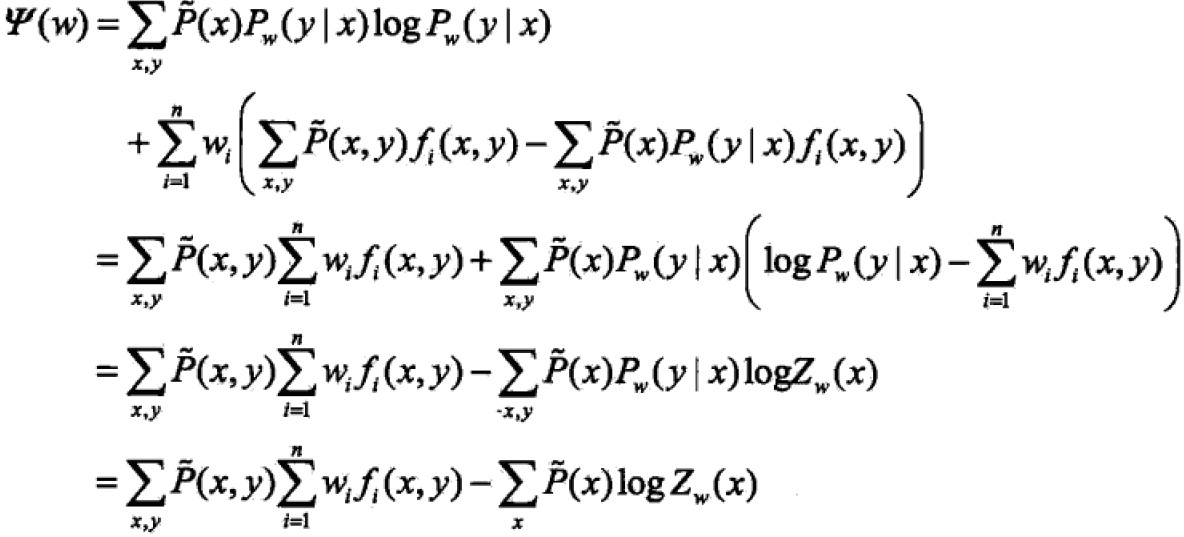 (首尾步用到Summation(P)=1去掉w0);
(首尾步用到Summation(P)=1去掉w0);
比较上二式得,
因此,最大熵模型就转化为具体求解对数似然函数或者对偶函数的极大化问题。
最大熵模型的一般形式:
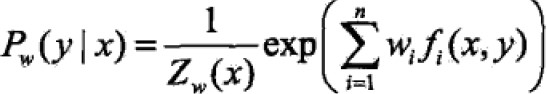 ,
,
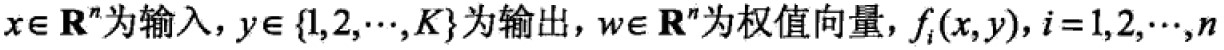 为任意实数的特征函数。
为任意实数的特征函数。
3 模型训练算法
逻辑回归模型和最大熵模型最终都可以归结为以似然函数为目标函数的最优化问题,通常采用迭代法。从优化的观点来看,目标函数是光滑凸函数,很容易找到全局最优解。此处两个方法。
3.1 改进迭代尺度法(IIS)
improved iterative scaling是一种最大熵模型学习的最优化算法。由以上结论可知似然函数为:

目标是求得L的参数,即对数似然函数的极大值时的w hat。
IIS思想:

对于经验分布P(x,y),模型参数从w到w+δ,对数似然函数改变量:

利用不等式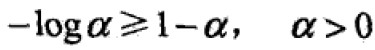 求得该变量的下界:
求得该变量的下界:
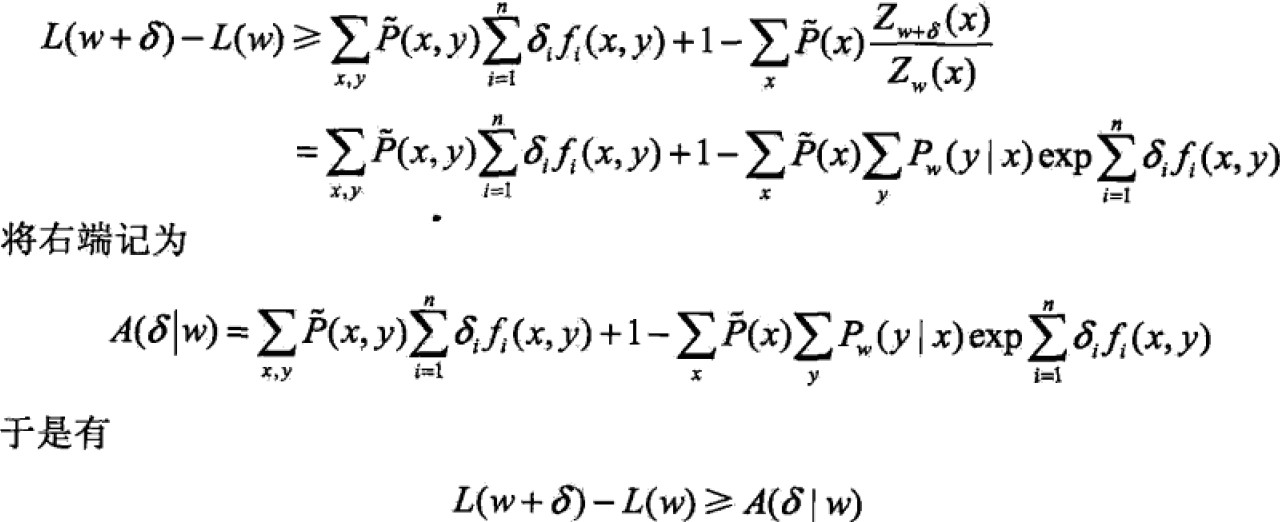
即,得到一个下界。如果使下界不断变大,相应的对数似然函数也会变大。A(δ|w)中δ是向量,同时优化不易,故每次只优化一个变量δi,固定其他。因此,如下处理:引入f#(x,y)=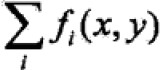 ,表示所有特征在(x,y)出现的次数(fi为二值函数),因此上界A改写为:
,表示所有特征在(x,y)出现的次数(fi为二值函数),因此上界A改写为:
 (乘一个f#,在除一个)
(乘一个f#,在除一个)
根据Jensen不等式:
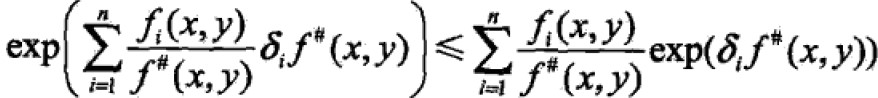
所以,
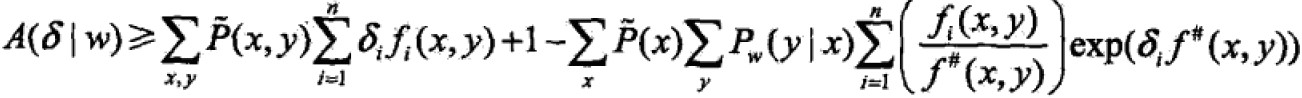
将右侧记为B(δ|w),因此,似然函数变化量为:
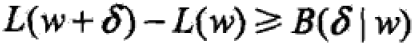
对B偏导δi
 比用A直接偏导δ处简单
比用A直接偏导δ处简单
偏导=0得:
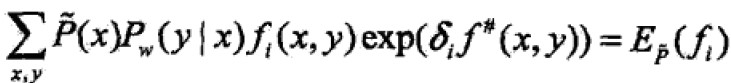 依次求出delta然后w迭代
依次求出delta然后w迭代
IIS算法:

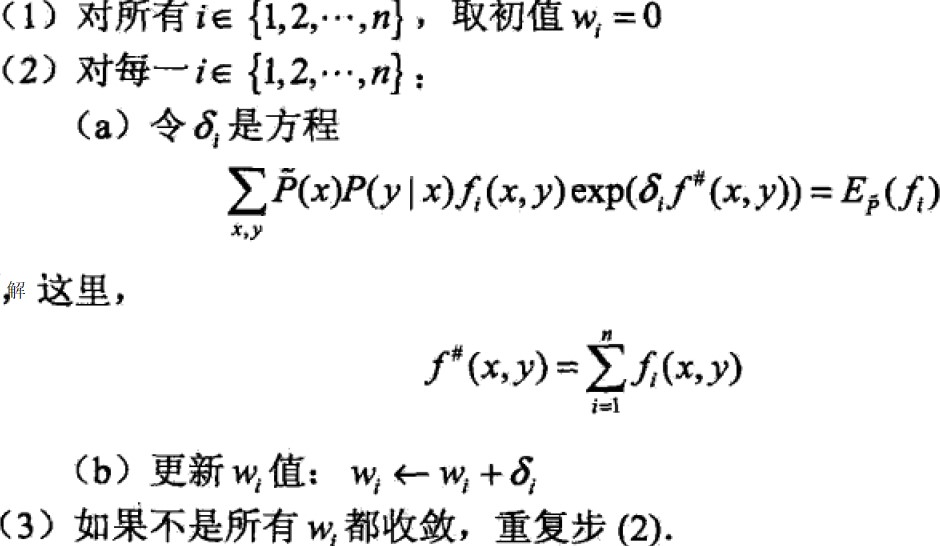
说明:关键步骤(a),求解δi,
如果f#(x,y)是常数则f#(x,y)=M,那么δi可得: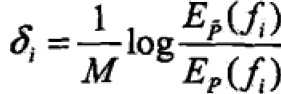
如果f#(x,y)不是常数,则必须通过数值计算来获取δi,最简单有效方法是牛顿法,另g(δi)=0表示(a)中等式,迭代公式为

选取合适的初值,方程有单根,牛顿法恒收敛,且收敛速度快。
3.2 拟牛顿法
最大熵模型:
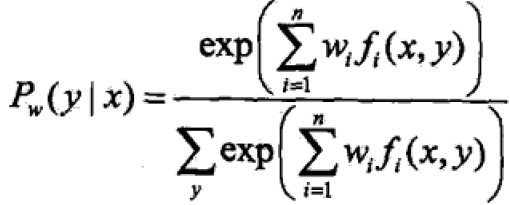
目标函数:

梯度:
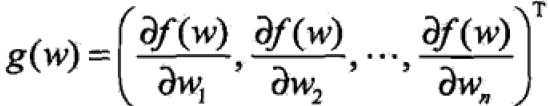 where
where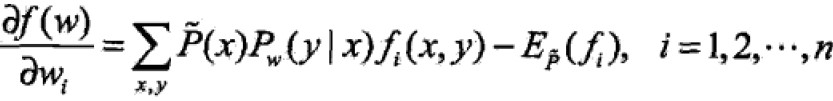
最大熵模型的BFGS算法:

附:更为详细的介绍:
牛顿法
拟牛顿法
DFP algorithm
BFGS algorithm
L-BFGS algorithm
class-逻辑回归与最大熵模型的更多相关文章
- 统计学习方法6—logistic回归和最大熵模型
目录 logistic回归和最大熵模型 1. logistic回归模型 1.1 logistic分布 1.2 二项logistic回归模型 1.3 模型参数估计 2. 最大熵模型 2.1 最大熵原理 ...
- 逻辑斯蒂回归3 -- 最大熵模型之改进的迭代尺度法(IIS)
声明: 1,本篇为个人对<2012.李航.统计学习方法.pdf>的学习总结,不得用作商用.欢迎转载,但请注明出处(即:本帖地址). 2,因为本人在学习初始时有非常多数学知识都已忘记.所以为 ...
- 最大熵模型(Maximum Etropy)—— 熵,条件熵,联合熵,相对熵,互信息及其关系,最大熵模型。。
引入1:随机变量函数的分布 给定X的概率密度函数为fX(x), 若Y = aX, a是某正实数,求Y得概率密度函数fY(y). 解:令X的累积概率为FX(x), Y的累积概率为FY(y). 则 FY( ...
- 100天搞定机器学习|Day55 最大熵模型
1.熵的定义 熵最早是一个物理学概念,由克劳修斯于1854年提出,它是描述事物无序性的参数,跟热力学第二定律的宏观方向性有关:在不加外力的情况下,总是往混乱状态改变.熵增是宇宙的基本定律,自然的有序状 ...
- 线性模型之逻辑回归(LR)(原理、公式推导、模型对比、常见面试点)
参考资料(要是对于本文的理解不够透彻,必须将以下博客认知阅读,方可全面了解LR): (1).https://zhuanlan.zhihu.com/p/74874291 (2).逻辑回归与交叉熵 (3) ...
- scikit-learn 逻辑回归类库使用小结
之前在逻辑回归原理小结这篇文章中,对逻辑回归的原理做了小结.这里接着对scikit-learn中逻辑回归类库的我的使用经验做一个总结.重点讲述调参中要注意的事项. 1. 概述 在scikit-lear ...
- 斯坦福第六课:逻辑回归(Logistic Regression)
6.1 分类问题 6.2 假说表示 6.3 判定边界 6.4 代价函数 6.5 简化的成本函数和梯度下降 6.6 高级优化 6.7 多类分类:一个对所有 6.1 分类问题 在分类问题中 ...
- Matlab实现线性回归和逻辑回归: Linear Regression & Logistic Regression
原文:http://blog.csdn.net/abcjennifer/article/details/7732417 本文为Maching Learning 栏目补充内容,为上几章中所提到单参数线性 ...
- 机器学习入门11 - 逻辑回归 (Logistic Regression)
原文链接:https://developers.google.com/machine-learning/crash-course/logistic-regression/ 逻辑回归会生成一个介于 0 ...
随机推荐
- JDBC访问及操作SQLite数据库
SQLite 是一个开源的嵌入式关系数据库,其特点是高度便携.使用方便.结构紧凑.高效.可靠. 与其他数据库管理系统不同,SQLite 的安装和运行非常简单,在大多数情况下,只要确保SQLite的二进 ...
- Xcode断点 中断不正常 每次断点都进入汇编
该问题是由于XCode的设置引起,其修改方法是: 选择Xcode菜单 -> Debug ->Debug workflow,将Alway show Disassembly前面的勾去掉就好了.
- js跨域解决方案
1.参考该文档:http://blog.csdn.net/enter89/article/details/51205752 2. 参考网络:http://www.ruanyifeng.com/blog ...
- asp.net core 使用html文件
在asp.net core 项目中,使用html文件一般通过使用中间件来提供服务: 打开 NuGet程序管理控制台 输入install-package Microsoft.aspnetcore.sta ...
- 零基础2018如何系统地学习python?
首先告诉你的是,零基础学习开始系统学习Python肯定难,Python的专业程度本身就不简单,学习这事本来就是一件非常煎熬的事情,人都不愿意学习,可是没办法,为了生存掌握一个技能,你必须学,如果你认真 ...
- supervisor配置文件详解
介绍 Supervisor是一个进程控制系统. 它是一个C/S系统(注意: 其提供WEB接口给用户查询和控制), 它允许用户去监控和控制在类UNIX系统的进程. 它的目标与launchd, daemo ...
- 织梦去除tag标签url中的问号
找到文件 include\taglib\tag.lib.php 大概87行 把 $row['link'] = $cfg_cmsurl."/tags.php?/".urlencod ...
- 标签(Label、JLabel)
构造函数 Label( ) Label(String str) Label(String str, int how) 第一种形式生成一个空白标签:第二种形式生成一个包含由参数str所设定的字符串的标签 ...
- 解决cookies存储中文报错问题
URLEncoder.encode("username", "UTF-8"); URLDecoder.decode("123", " ...
- ubuntu重启、关机命令
重启命令 : 1.reboot 2.shutdown -r now 立刻重启 3.shutdown -r 10 过10分钟自动重启 4.shutdown -r 20:35 ...