hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(2)安装hadoop
一、依赖安装
安装JDK
二、文件准备
hadoop-2.7.3.tar.gz
2.2 下载地址
http://hadoop.apache.org/releases.html
三、工具准备
3.1 Xshell
3.2 Xftp
四、部署图
master:192.168.136.128
slave:192.168.136.129
slave:192.168.136.130
五、Hadoop安装
以下操作,均使用root用户
5.1 主机名与IP地址映射关系配置
Master节点上,执行如下命令:
#vi /etc/hosts
在文件最后,输入如下内容:
192.168.136.128 LxfN1
192.168.136.129 LxfN2
192.168.136.130 LxfN3
保存,退出,然后通过scp命令,将配置好的文件拷贝其他两个Slave节点:
#scp /etc/hosts root@LxfN2:/etc
#scp /etc/hosts root@LxfN3:/etc
5.2 SSH免登陆配置
#ssh-keygen -t rsa
一直回车
然后分别拷贝到Master以及Slave节点:
对于LxfN1:
对于LxfN2:
scp ./id_rsa.pub root@LxfN1:/root/.ssh/id_rsa_2.pub
对于LxfN3:
scp ./id_rsa.pub root@LxfN1:/root/.ssh/id_rsa_3.pub 在LxfN1上合并所有文件成authorized_keys
分发合并后的文件authorized_keys到其他机器上
scp ./authorized_keys root@LxfN1:/root/.ssh/
scp ./authorized_keys root@LxfN1:/root/.ssh/
通过#ssh LxfN2 测试是否配置成功,如果不需要输入密码,则证明配置成功
5.3 通过Xftp将下载下来的Hadoop安装文件上传到Master及两个Slave的/usr目录下
5.4 通过Xshell连接到虚拟机,在Master及两个Slave上,执行如下命令,解压文件:
# tar zxvf hadoop-2.7.3.tar.gz
建立到解压目录的连接hadoop
5.5 在Master上,使用Vi编辑器,设置环境变量
# vi /etc/profile
在文件最后,添加如下内容:
# Hadoop Env
export HADOOP_HOME=/opt/moudles/hadoop
export PATH=PATH:PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
5.6 退出vi编辑器,使环境变量设置立即生效
# source /etc/profile
通过scp命令,将/etc/profile拷贝到两个Slave节点:
#scp /etc/profile root@LxfN2:/etc
#scp /etc/profile root@LxfN3:/etc
分别在两个Salve节点上执行# source /etc/profile使其立即生效
5.7 查看Hadoop版本信息

# hadoop version
Hadoop 2.7.3
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on 2016-08-18T01:41Z
Compiled with protoc 2.5.0
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /opt/modules/hadoop/share/hadoop/common/hadoop-common-2.7.3.jar
六、Hadoop配置
以下操作均在Master节点,配置完后,使用scp命令,将配置文件拷贝到两个Slave节点即可。
切换到/opt/modules/hadoop/etc/hadoop/目录下,修改如下文件:
6.1 hadoop-env.sh
在文件最后,增加如下配置:
export JAVA_HOME=/opt/modules/jdk1.8
export HADOOP_PREFIX=/opt/modules/hadoop
6.2 yarn-env.sh
在文件最后,增加如下配置:
export JAVA_HOME=/opt/modules/jdk1.8
6.3 core-site.xml
创建tmp目录:#mkdir /usr/hadoop-2.7.3/tmp
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://LxfN1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop/tmp</value>
</property>
</configuration>
6.4 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
6.5 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6.6 yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>LxfN1</value>
</property>
</configuration>
6.7 slaves
LxfN1
LxfN2
LxfN3
6.8 拷贝配置文件到两个Slave节点
在Master节点,执行如下命令:
# scp -r /opt/modules/hadoop/etc/hadoop/ root@LxcN2:/opt/modules/hadoop/etc/
# scp -r /opt/modules/hadoop/ root@LxcN3:/opt/modules/hadoop/etc/
七、Hadoop使用
7.1 格式化NameNode
Master节点上,执行如下命令
#hdfs namenode -format
7.2 启动HDFS(NameNode、DataNode)
Master节点上,执行如下命令
#start-dfs.sh
使用jps命令,分别在Master以及两个Slave上查看Java进程
可以在Master上看到如下进程:
34225 SecondaryNameNode
33922 NameNode
34028 DataNode
49534 Jps
在两个Slave上,看到如下进程:
34028 DataNode
49534 Jps
7.3 启动 Yarn(ResourceManager 、NodeManager)
Master节点上,执行如下命令
#start-yarn.sh
使用jps命令,分别在Master以及两个Slave上查看Java进程
可以在Master上看到如下进程:
34225 SecondaryNameNode
33922 NameNode
34632 NodeManager
34523 ResourceManager
34028 DataNode
49534 Jps
在两个Slave上,看到如下进程:
34632 NodeManager
34028 DataNode
49534 Jps
7.4 通过浏览器查看HDFS信息
浏览器中,输入http://LxfN1:50070
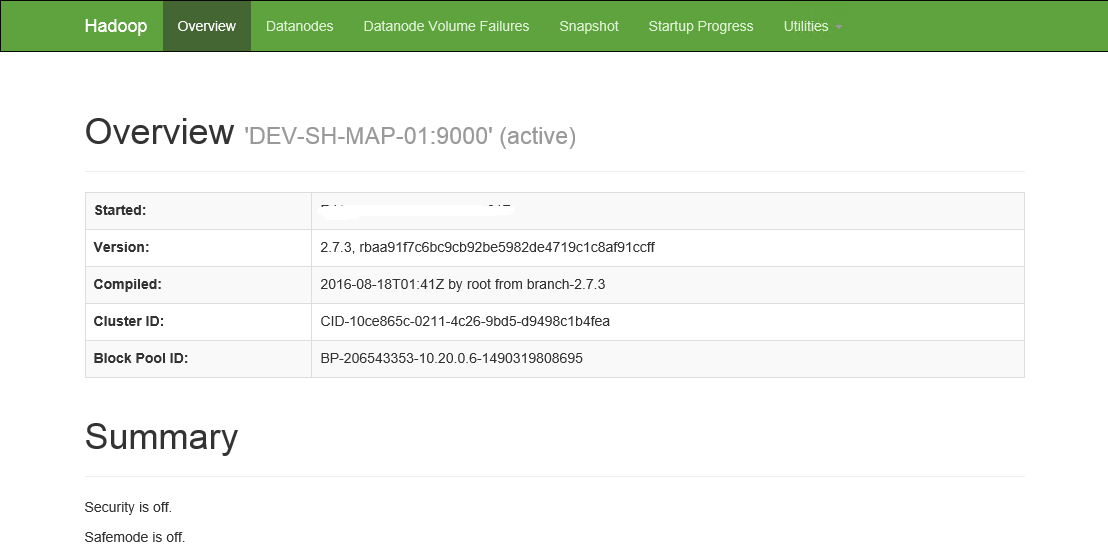
7.5 停止Yarn及HDFS
#stop-yarn.sh
#stop-dfs.sh
hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(2)安装hadoop的更多相关文章
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装
hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装 一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh ...
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(3)http://www.cnblogs.com/liugh/p/6624491.html
一.文件准备 scala-2.12.1.tgz 下载地址: http://www.scala-lang.org/download/2.12.1.html 二.工具准备 2.1 Xshell 2.2 X ...
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(1)安装jdk
一.文件准备 下载jdk-8u131-linux-x64.tar.gz 二.工具准备 2.1 Xshell 2.2 Xftp 三.操作步骤 3.1 解压文件: $ tar zxvf jdk-8u131 ...
- Hadoop2.7.3+Spark2.1.0完全分布式集群搭建过程
1.选取三台服务器(CentOS系统64位) 114.55.246.88 主节点 114.55.246.77 从节点 114.55.246.93 从节点 之后的操作如果是用普通用户操作的话也必须知道r ...
- Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程
一.修改hosts文件 在主节点,就是第一台主机的命令行下; vim /etc/hosts 我的是三台云主机: 在原文件的基础上加上; ip1 master worker0 namenode ip2 ...
- Apache Spark1.1.0部署与开发环境搭建
Spark是Apache公司推出的一种基于Hadoop Distributed File System(HDFS)的并行计算架构.与MapReduce不同,Spark并不局限于编写map和reduce ...
- Windows Server 2003 IIS6.0+PHP5(FastCGI)+MySQL5环境搭建教程
准备篇 一.环境说明: 操作系统:Windows Server 2003 SP2 32位 PHP版本:php 5.3.14(我用的php 5.3.10安装版) MySQL版本:MySQL5.5.25 ...
- Cocos2dx-3.0版本 从开发环境搭建(Win32)到项目移植Android平台过程详解
作为重量级的跨平台开发的游戏引擎,Cocos2d-x在现今的手游开发领域占有重要地位.那么问题来了,作为Cocos2dx的学习者,它的可移植特性我们就需要掌握,要不然总觉得少一门技能.然而这个时候各种 ...
- SDL2.0的VS开发环境搭建
SDL2.0的VS开发环境搭建 [前言] 我是用的是VS2012,VS的版本应该大致一样. [开发环境搭建] >>>SDL2.0开发环境配置:1.从www.libsdl.org 下载 ...
随机推荐
- 纯代码实现wordpress文章隐藏内容评论可见
在很多网站上都看过这个效果,比如说知己知彼网站,他的部分资源是需要我们评论后才能下载的,那么这个到底有什么用呢,对我而言,除了拿来装逼,还可以增加我的评论数量,不多说,先看看效果: 其实WordPre ...
- 【Unity与23种设计模式】适配器模式(Adapter)
GoF中定义: "将一个类的接口转换成为客户端期待的类接口.适配器模式让原本接口不兼容的类能一起合作." 适配器模式与装饰模式有一定的相似之处 两者都是在着手解决C#不能多继承的问 ...
- 浅析JavaScript的prototype
一.JavaScript对象的创建 (1)对象方法 function Student(name){ this.name=name; this.showName=function(){ alert(&q ...
- 员工选票系统-java
Yuangong.java package com.toupiao; public class Yuangong { private String name; private int piao; pu ...
- 关于 BigDecimal处理float、double数据
Big Decimal 在java中,对于float与double中的数据,总会因为精度问题而丢失数据的准确性,也就是说对于两者所处理的得到的值是无限接近于那个数,而并非一个精确数字,而对于电商中所涉 ...
- MySQL聚集索引和非聚集索引
索引分为聚集索引和非聚集索引,mysql中不同的存储引擎对索引的底层实现可能会不同,这里只关注mysql的默认存储引擎InnoDB. 利用下面的命令可以查看默认的存储引擎 show variables ...
- 走近webpack(3)--图片的处理
上一章,咱们学了如何用webpack来打包css,压缩js等.这一篇文章咱们来学习一下如何用webpack来处理图片.废话不多说,咱们开始吧. 首先,咱们随便找一张你喜欢的图片放到src/images ...
- Mycat 分片规则详解--ASCII 取模范围分片
实现方式:该算法与取模范围算法类似,该算法支持数值.符号.字母取模.首先截取长度为 prefixLength 的子串,在对子串中每一个字符的 ASCII 码求和,然后对求和值进行取模运算(sum%pa ...
- SpringBoot快速开发REST服务最佳实践
一.为什么选择SpringBoot Spring Boot是由Pivotal团队提供的全新框架,被很多业内资深人士认为是可能改变游戏规则的新项目.早期我们搭建一个SSH或者Spring Web应用,需 ...
- Post Office
Post Office poj-1160 题目大意:给你在数轴上的n个村庄,建立m个邮局,使得每一个村庄距离它最近的邮局的距离和最小,求距离最小和. 注释:n<=300,m<=min(n, ...