5分钟学习spark streaming之 轻松在浏览器运行和修改Word Counts
方案一:根据官方实例,下载预编译好的版本,执行以下步骤:
- nc -lk 9999 作为实时数据源
- ./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost 9999
- 在第一步的terminal 窗口输入一些句子
- 第二步的output 就是实时执行结果
此方案的问题有
- 探索其中的api 比较困难,比如我想试试另外一种写法,需要改源码,然后编译,时间就变长了
- 如果是一个裸机的话,需要安装好java 环境,spark和java版本之间的依赖也要特别小心
方案二(2个docker 命令,你就可以为所欲为的在浏览器里面运行,更改Word counts这个hello word了)
除去下载docker img的时间,5min没法完成以下步骤,请立即私信给我,有奖,哈哈
- docker run -p 8080:8080 --rm fancyisbest/zeppeinsparkstreaming:0.1 (第一次会花很长时间在pull img)
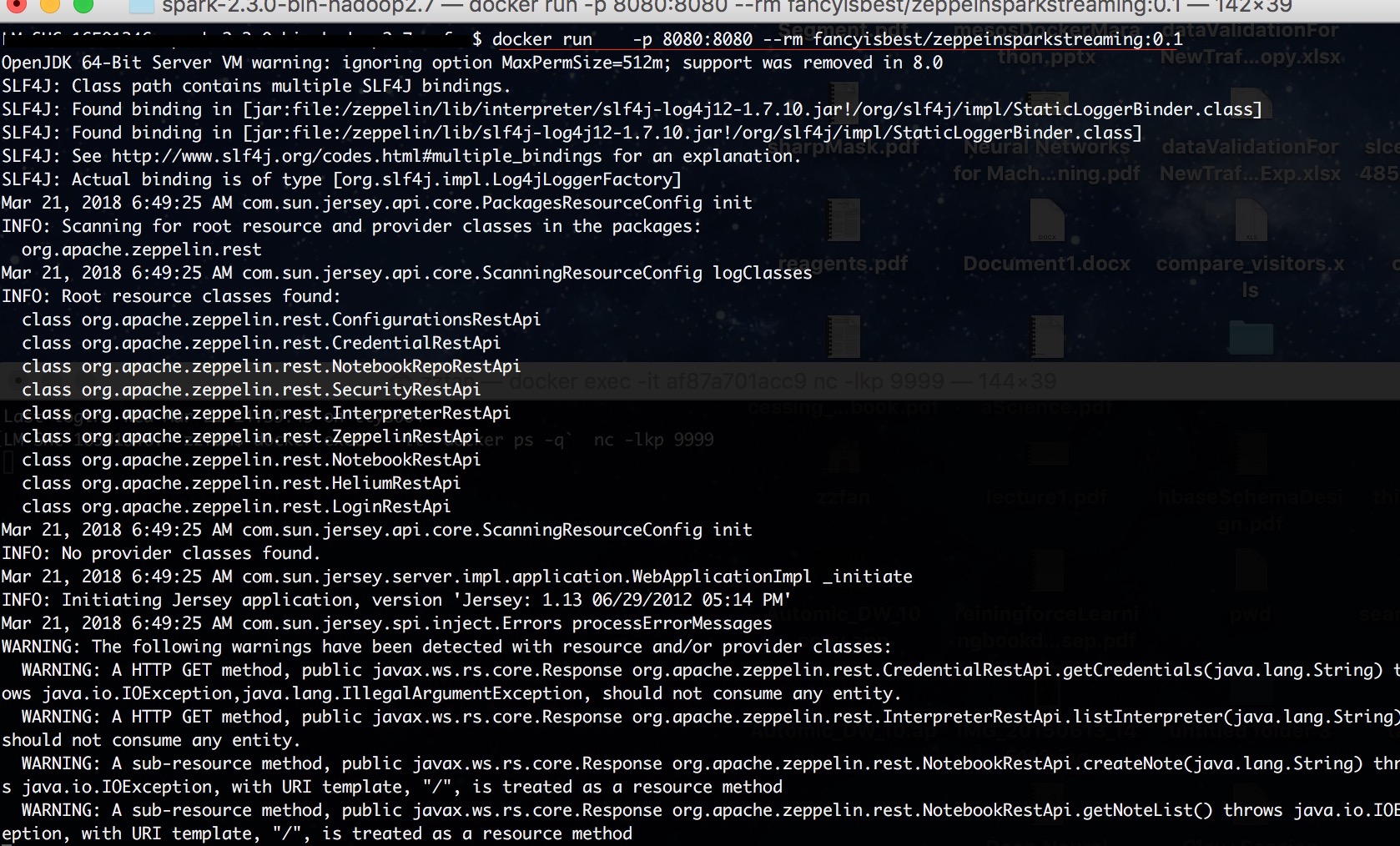
- docker exec -it `docker ps -q` nc -lkp 9999 (注意如果你有多个container在运行,请把`docker ps -q` 替换成上一个的container id)

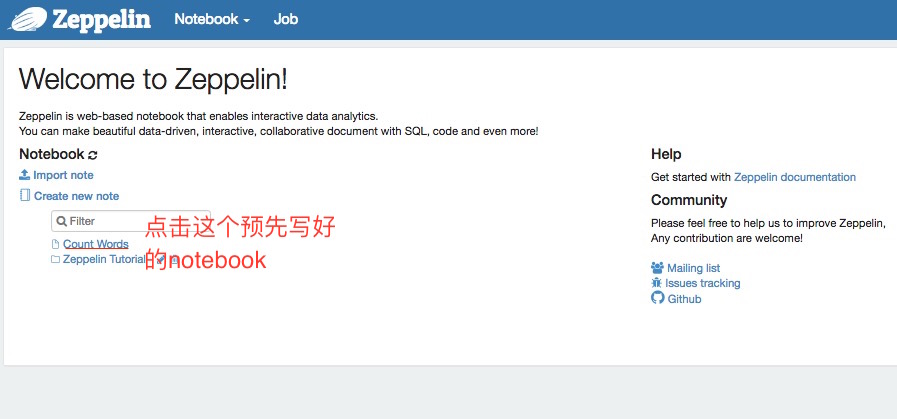
- 打开浏览器输入http://localhost:8080/#/, 左下角有Word counts,点击进入notebook,点击运行所有段落。

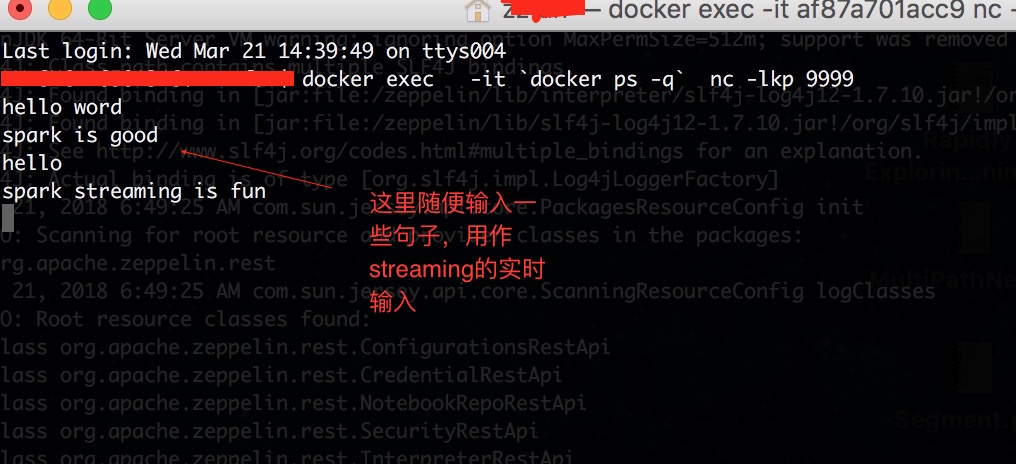
- 在第二步termial输入些句子,你就可以在notebook里面观察到streaming 在执行。
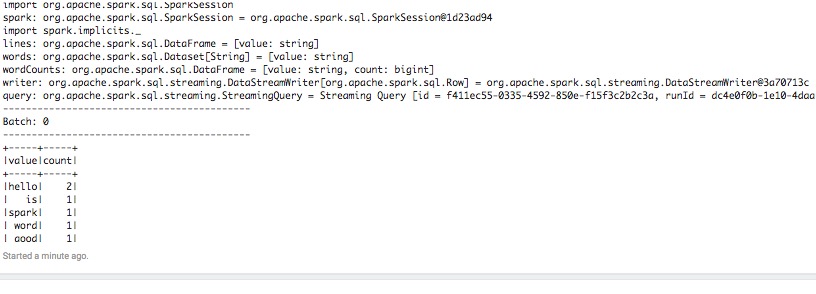
此方案的优势
- 除了docker,不需要安装任何依赖,这很dev ops
- 可以狠狠地改代码,改完就可以立即执行,不用担心会破坏任何环境,探索你的世界,你做主。
提示:
- 此方案的技术堆是:docker+zeppelin+spark
- docker img是我在zeppelin img上加入了必要的命令和notebook 打包成的img,请放心使用。
- 如果你对docker,zeppelin不熟悉,不要担心,它们都很简单,只要稍微花点时间就可以掌握,请记住我们的目标是学习spark streaming
参考:
zeppelin 官网http://zeppelin.apache.org/
5分钟学习spark streaming之 轻松在浏览器运行和修改Word Counts的更多相关文章
- 5分钟学习spark streaming 表格和图形化的文档-概览
看图回答以下问题: 1. spark streaming 架构以及功能特性 2. spark streaming mode?以及每个mode主要特性?包括延迟和语义保证.
- Dream_Spark-----Spark 定制版:005~贯通Spark Streaming流计算框架的运行源码
Spark 定制版:005~贯通Spark Streaming流计算框架的运行源码 本讲内容: a. 在线动态计算分类最热门商品案例回顾与演示 b. 基于案例贯通Spark Streaming的运 ...
- 【Streaming】30分钟概览Spark Streaming 实时计算
本文主要介绍四个问题: 什么是Spark Streaming实时计算? Spark实时计算原理流程是什么? Spark 2.X下一代实时计算框架Structured Streaming Spark S ...
- 基于案例贯通 Spark Streaming 流计算框架的运行源码
本期内容 : Spark Streaming+Spark SQL案例展示 基于案例贯穿Spark Streaming的运行源码 一. 案例代码阐述 : 在线动态计算电商中不同类别中最热门的商品排名,例 ...
- 5.Spark Streaming流计算框架的运行流程源码分析2
1 spark streaming 程序代码实例 代码如下: object OnlineTheTop3ItemForEachCategory2DB { def main(args: Array[Str ...
- 贯通Spark Streaming流计算框架的运行源码
本章节内容: 一.在线动态计算分类最热门商品案例回顾 二.基于案例贯通Spark Streaming的运行源码 先看代码(源码场景:用户.用户的商品.商品的点击量排名,按商品.其点击量排名前三): p ...
- Spark Streaming概念学习系列之SparkStreaming运行原理
SparkStreaming运行原理 Spark Streaming不断的从数据源获取数据(连续的数据流),并将这些数据按照周期划分为batch. Spark Streaming将每个batch的数据 ...
- spark streaming 接收kafka消息之四 -- 运行在 worker 上的 receiver
使用分布式receiver来获取数据使用 WAL 来实现 exactly-once 操作: conf.set("spark.streaming.receiver.writeAheadLog. ...
- Spark Streaming:大规模流式数据处理的新贵(转)
原文链接:Spark Streaming:大规模流式数据处理的新贵 摘要:Spark Streaming是大规模流式数据处理的新贵,将流式计算分解成一系列短小的批处理作业.本文阐释了Spark Str ...
随机推荐
- python如何使用pymysql模块
Python 3.x 操作MySQL的pymysql模块详解 前言pymysql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同.但目前pymysql支持python3.x而M ...
- Linux SendMail发送邮件失败诊断案例(四)
最近又碰到一起Linux下SendMail发送邮件失败的案例,邮件发送后,邮箱收不到具体邮件, 查看日志/var/log/maillog 发现有"DSN: User unknown" ...
- mongodb副本集中其中一个节点宕机无法重启的问题
2-8日我还在家中的时候,被告知mongodb副本集中其中一个从节点因未知原因宕机,然后暂时负责代管的同事无论如何就是启动不起来. 当时mongodb的日志信息是这样的: 实际上这里这么长一串最重要的 ...
- caffe︱cifar-10数据集quick模型的官方案例
准备拿几个caffe官方案例用来练习,就看到了caffe中的官方案例有cifar-10数据集.于是练习了一下,在CPU情况下构建quick模型.主要参考博客:liumaolincycle的博客 配置: ...
- 如何编译linux第一个模块 hellomod.ko
Linux下的驱动程序也没有听上去的那么难实现,我们可以看一下helloworld这个例子就完全可以了解它的编写的方式! 我们还是先看一个这个例子,helloworld 1. [代码]hellowor ...
- 分析Android-Universal-Image-Loader的缓存处理机制
最近看了UIL中的缓存实现,才发现其实这个东西不难,没有太多的进程调度,没有各种内存读取控制机制.没有各种异常处理.反正UIL中不单代码写的简单,连处理都简单.但是这个类库这么好用,又有这么多人用,那 ...
- 笔记︱支持向量机SVM在金融风险欺诈中应用简述
本笔记源于CDA-DSC课程,由常国珍老师主讲.该训练营第一期为风控主题,培训内容十分紧凑,非常好,推荐:CDA数据科学家训练营 欺诈一般不用什么深入的模型进行拟合,比较看重分析员对业务的了解,从异常 ...
- linux之x86裁剪移植---ffmpeg的H264解码显示(420、422)
在虚拟机上yuv420可以正常显示 ,而945(D525)模块上却无法显示 ,后来验证了directdraw的yuv420也无法显示 ,由此怀疑显卡不支持 ,后把420转换为422显示. 420显示如 ...
- EFI、UEFI、MBR、GPT的区别
UEFI.GPT.MBR是什么?这些专业术语不难理解,UEFI属于主板类名词,其作用类似于BIOS.GPT.MBR则属于硬盘类名词,它们的作用类似一艘航母的骨架,有了这个骨架,我们才可以进行细致到诸如 ...
- 错误代码: 1305 PROCEDURE world.insert_data does not exist
1.错误描述 1 queries executed, 0 success, 1 errors, 0 warnings 查询:call insert_data() 错误代码: 1305 PROCEDUR ...