Python爬虫获取异步加载站点pexels并下载图片(Python爬虫实战3)
1. 异步加载爬虫
对于静态页面爬虫很容易获取到站点的数据内容,然而静态页面需要全量加载站点的所有数据,对于网站的访问和带宽是巨大的挑战,对于高并发和大访问访问量的站点来说,需要使用AJAX相关的技术来实现异步加载,即根据需要来获取数据,以pexels网站为例,按F12,切换到Network的XHR标签,通过下拉菜单访问该站点,此时数据会以此加载,在XHR页面中会逐步增加访问的URL地址,点击查看其中一个URL地址,发现其URL的地址类似为:https://www.pexels.com/search/book/?page=3&seed=2018-02-22+05:21:39++0000&format=js&seed=2018-02-22 05:21:39 +0000,将其修改为https://www.pexels.com/search/book/?page=3,并修改page后面数的值发现可以访问到不同的页面内容,以此来构造需要访问的url站点内容。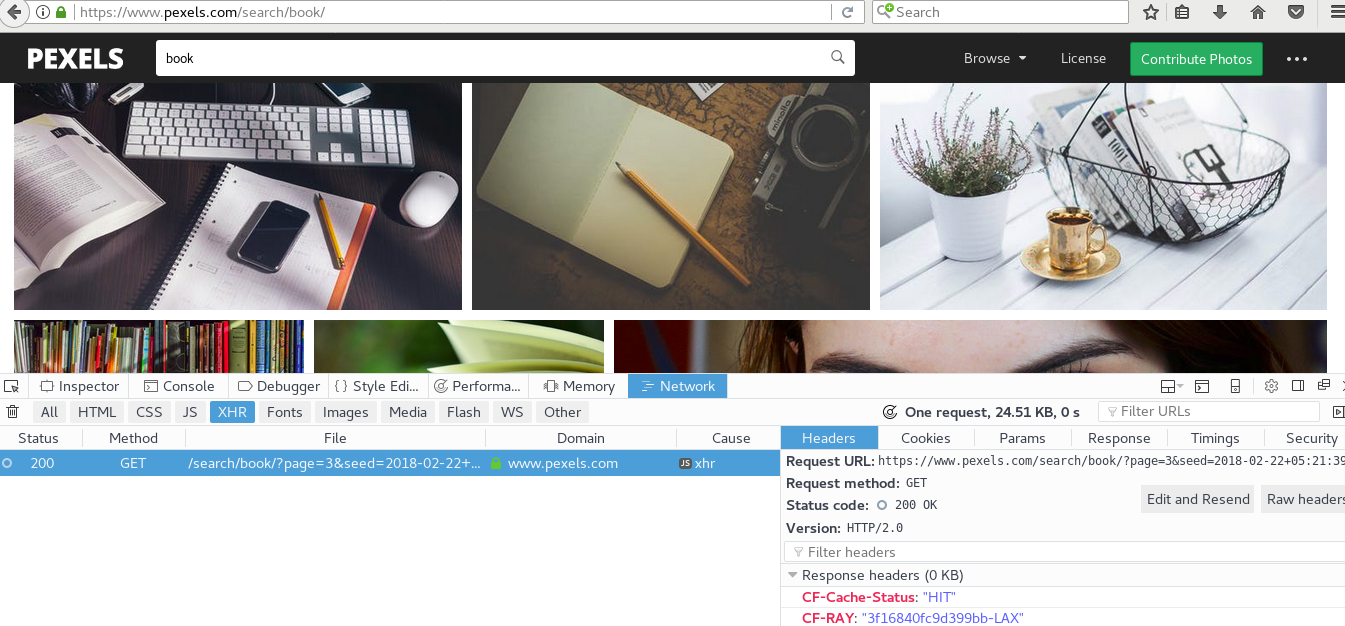
2. 代码内容
#!/usr/bin/python
#_*_ coding:utf _*_
#author: HappyLau
#blog: https://www.cnblogs.com/cloudlab import os
import sys
import time
import os.path
import random
import requests
from lxml import etree reload(sys)
sys.setdefaultencoding('utf8') def get_jianshu(url):
'''
demo简书网站的获取信息
'''
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0"}
try:
req = requests.get(url,headers=headers)
if req.status_code == 200:
return req.text.encode('utf8')
else:
return ''
except Exception as e:
print e def get_picture(url,download_dir):
'''
@params:获取url中的图片信息,并将其下载到download_dir目录中
@download_dir:图片下载的本地路径
'''
if not os.path.exists(download_dir):
os.mkdir(download_dir)
html = get_jianshu(url)
selector = etree.HTML(html)
for url in selector.xpath('//img[@class="photo-item__img"]/@src'):
picture_name = url.split("?")[0].split("/")[-1]
print "downloading picutre %s" % (picture_name)
with file(download_dir + picture_name,'wb') as f:
f.write(requests.get(url).content)
time.sleep(random.randint(1,3)) if __name__ == "__main__":
url_lists = ['https://www.pexels.com/search/book/?page={}'.format(i) for i in range(1,21)]
for url in url_lists:
get_picture(url,'/root/pexels')
3. 下载图片使用方式
上面使用requests.get().content的方式来实现下载图片的方法,还可以通过urllib.urlretrieve()方法来实现图片的下载功能,该函数的使用参数为:retrieve(self, url, filename=None, reporthook=None, data=None),其中url地址为需要访问的url路径,filename为本地存放图片的路径,修改代码内容如下:
#!/usr/bin/python
#_*_ coding:utf _*_
#author: HappyLau
#blog: https://www.cnblogs.com/cloudlab import os
import sys
import time
import os.path
import random
import requests
import urllib
from lxml import etree reload(sys)
sys.setdefaultencoding('utf8') def get_jianshu(url):
'''
demo简书网站的获取信息
'''
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0"}
try:
req = requests.get(url,headers=headers)
if req.status_code == 200:
return req.text.encode('utf8')
else:
return ''
except Exception as e:
print e def get_picture(url,download_dir):
'''
@params:获取url中的图片信息,并将其下载到download_dir目录中
@download_dir:图片下载的本地路径
通过利用urllib模块中的urlretrieve()方法实现图片的下载功能
'''
if not os.path.exists(download_dir):
os.mkdir(download_dir)
html = get_jianshu(url)
selector = etree.HTML(html)
for url in selector.xpath('//img[@class="photo-item__img"]/@src'):
picture_name = download_dir + "/" + url.split("?")[0].split("/")[-1]
print "downloading picutre %s" % (picture_name)
urllib.urlretrieve(url,picture_name) #下载图片
time.sleep(random.randint(1,3)) if __name__ == "__main__":
url_lists = ['https://www.pexels.com/search/book/?page={}'.format(i) for i in range(1,21)]
for url in url_lists:
get_picture(url,'/root/pexels')
Python爬虫获取异步加载站点pexels并下载图片(Python爬虫实战3)的更多相关文章
- 【vue】获取异步加载后的数据
异步请求的数据,对它做一些处理,需要怎么做呢?? axios 异步请求数据,得到返回的数据, 赋值给变量 info .如果要对 info 的数据做一些处理后再赋值给 hobby ,直接在 axios ...
- Python 爬取异步加载的数据
在我们的工作中,可能会遇到这样的情况:我们需要爬取的数据是通过ajax异步加载的,这样的话通过requests得到的只是一个静态页面,而我们需要的是ajax动态加载的数据! 那我们应该怎么办呢??? ...
- Java 爬虫遇上数据异步加载,试试这两种办法!
这是 Java 爬虫系列博文的第三篇,在上一篇 Java 爬虫遇到需要登录的网站,该怎么办? 中,我们简单的讲解了爬虫时遇到登录问题的解决办法,在这篇文章中我们一起来聊一聊爬虫时遇到数据异步加载的问题 ...
- UIImageView异步加载网络图片
在iOS开发过程中,经常会遇到使用UIImageView展现来自网络的图片的情况,最简单的做法如下: 去下载https://github.com/rs/SDWebImage放进你的工程里,加入头文件# ...
- 多线程异步加载图片async_pictures
异步加载图片 目标:在表格中异步加载网络图片 目的: 模拟 SDWebImage 基本功能实现 理解 SDWebImage 的底层实现机制 SDWebImage 是非常著名的网络图片处理框架,目前国内 ...
- Unity 异步加载场景
效果图如下: 今天一直在纠结如何加载场景,中间有加载画面和加载完毕的效果动画! A 场景到 B , 看见网上的做法都是 A –> C –> B. C场景主要用于异步加载B 和 播放一些 ...
- ios UIImageView异步加载网络图片
方法1:在UI线程中同步加载网络图片 UIImageView *headview = [[UIImageView alloc] initWithFrame:CGRectMake(0, 0, 40, 4 ...
- Android批量图片加载经典系列——使用xutil框架缓存、异步加载网络图片
一.问题描述 为提高图片加载的效率,需要对图片的采用缓存和异步加载策略,编码相对比较复杂,实际上有一些优秀的框架提供了解决方案,比如近期在git上比较活跃的xutil框架 Xutil框架提供了四大模块 ...
- [翻译]Bitmap的异步加载和缓存
内容概述 [翻译]开发文档:android Bitmap的高效使用 本文内容来自开发文档"Traning > Displaying Bitmaps Efficiently", ...
随机推荐
- prop&attr区别和用法,以多选框为例
1.比较 相同点 : prop和attr作为jquery的方法都可以获取属性值; 不同点 : (1) 对于HTML元素本身就带有的固有属性,使用prop方法, attr获取checkbox的check ...
- Python常用数据结构之heapq模块
Python数据结构常用模块:collections.heapq.operator.itertools heapq 堆是一种特殊的树形结构,通常我们所说的堆的数据结构指的是完全二叉树,并且根节点的值小 ...
- Action里面的自带的字段的含义
- AGC010 - D: Decrementing
原题链接 题意简述 给出一个个数的序列,足够聪明的AB两人轮流进行以下操作: 令一个大于1的数减1,然后所有数除以. 如果一个人不能操作了,那么他就输了. 输入保证所有数都是正整数并且. 分析 这是一 ...
- php面试上机题(2018-3-3)
需求:将第三方api的前3000条数据全部读取出来,存入对应的数据库字段 第三方api:http://pub.cloudmob.mobi/publisherapi/offers/?uid=92& ...
- WEB 小案例 -- 网上书城(二)
寒假结束了,自己的颓废时间同样结束了,早该继续写博客了,尽管我的格式以及内容由于各种原因老被卡,但必须坚持写下去!!! 上次我们对于本案例的数据库部分进行了阐述,这次主要接着上次的内容分享本案例的翻页 ...
- hadoop/storm以及hive/hbase/pig区别整理
STORM与HADOOP的比较 对于一堆时刻在增长的数据,如果要统计,可以采取什么方法呢? 等数据增长到一定程度的时候,跑一个统计程序进行统计.适用于实时性要求不高的场景.如将数据导到HDFS,再运行 ...
- mysql字符串连接
用SQL Server 连接字符串是用“+” 现在数据库用mysql, 写个累加两个字段值SQL语句居然不支持"+",郁闷了半天在网上查下,才知道mysql里的+是数字相加的操作, ...
- Java之List排序
1.Java封装类 Student.java: /** * @Title:Student.java * @Package:com.you.data * @Description: * @Author: ...
- 硬盘GPT分区与MBR分区的转换
如何将gpt分区更改成mbr分区? "因为笔记本电脑硬盘分区表是GPT而导致大家无法安装引导系统.需要转换为MBR分区还能顺利安装." 问题是,分区工具无法转换MBR,这里小编知道 ...