Python爬虫获取异步加载站点pexels并下载图片(Python爬虫实战3)
1. 异步加载爬虫
对于静态页面爬虫很容易获取到站点的数据内容,然而静态页面需要全量加载站点的所有数据,对于网站的访问和带宽是巨大的挑战,对于高并发和大访问访问量的站点来说,需要使用AJAX相关的技术来实现异步加载,即根据需要来获取数据,以pexels网站为例,按F12,切换到Network的XHR标签,通过下拉菜单访问该站点,此时数据会以此加载,在XHR页面中会逐步增加访问的URL地址,点击查看其中一个URL地址,发现其URL的地址类似为:https://www.pexels.com/search/book/?page=3&seed=2018-02-22+05:21:39++0000&format=js&seed=2018-02-22 05:21:39 +0000,将其修改为https://www.pexels.com/search/book/?page=3,并修改page后面数的值发现可以访问到不同的页面内容,以此来构造需要访问的url站点内容。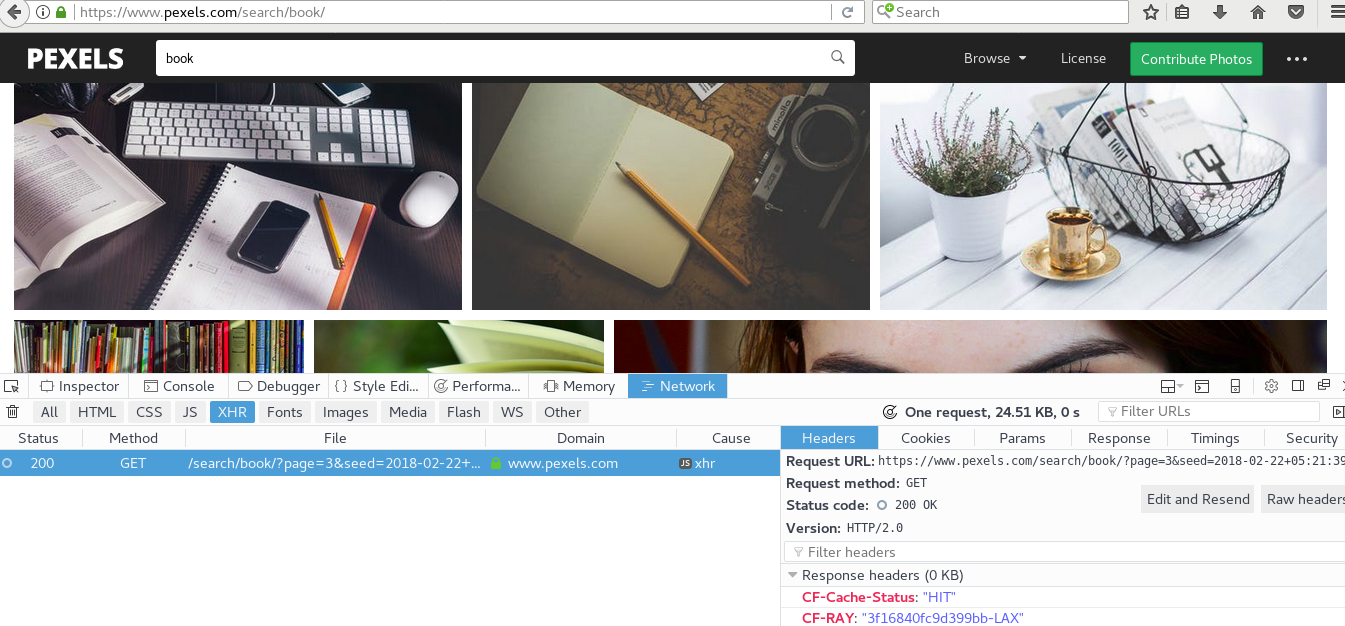
2. 代码内容
#!/usr/bin/python
#_*_ coding:utf _*_
#author: HappyLau
#blog: https://www.cnblogs.com/cloudlab import os
import sys
import time
import os.path
import random
import requests
from lxml import etree reload(sys)
sys.setdefaultencoding('utf8') def get_jianshu(url):
'''
demo简书网站的获取信息
'''
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0"}
try:
req = requests.get(url,headers=headers)
if req.status_code == 200:
return req.text.encode('utf8')
else:
return ''
except Exception as e:
print e def get_picture(url,download_dir):
'''
@params:获取url中的图片信息,并将其下载到download_dir目录中
@download_dir:图片下载的本地路径
'''
if not os.path.exists(download_dir):
os.mkdir(download_dir)
html = get_jianshu(url)
selector = etree.HTML(html)
for url in selector.xpath('//img[@class="photo-item__img"]/@src'):
picture_name = url.split("?")[0].split("/")[-1]
print "downloading picutre %s" % (picture_name)
with file(download_dir + picture_name,'wb') as f:
f.write(requests.get(url).content)
time.sleep(random.randint(1,3)) if __name__ == "__main__":
url_lists = ['https://www.pexels.com/search/book/?page={}'.format(i) for i in range(1,21)]
for url in url_lists:
get_picture(url,'/root/pexels')
3. 下载图片使用方式
上面使用requests.get().content的方式来实现下载图片的方法,还可以通过urllib.urlretrieve()方法来实现图片的下载功能,该函数的使用参数为:retrieve(self, url, filename=None, reporthook=None, data=None),其中url地址为需要访问的url路径,filename为本地存放图片的路径,修改代码内容如下:
#!/usr/bin/python
#_*_ coding:utf _*_
#author: HappyLau
#blog: https://www.cnblogs.com/cloudlab import os
import sys
import time
import os.path
import random
import requests
import urllib
from lxml import etree reload(sys)
sys.setdefaultencoding('utf8') def get_jianshu(url):
'''
demo简书网站的获取信息
'''
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0"}
try:
req = requests.get(url,headers=headers)
if req.status_code == 200:
return req.text.encode('utf8')
else:
return ''
except Exception as e:
print e def get_picture(url,download_dir):
'''
@params:获取url中的图片信息,并将其下载到download_dir目录中
@download_dir:图片下载的本地路径
通过利用urllib模块中的urlretrieve()方法实现图片的下载功能
'''
if not os.path.exists(download_dir):
os.mkdir(download_dir)
html = get_jianshu(url)
selector = etree.HTML(html)
for url in selector.xpath('//img[@class="photo-item__img"]/@src'):
picture_name = download_dir + "/" + url.split("?")[0].split("/")[-1]
print "downloading picutre %s" % (picture_name)
urllib.urlretrieve(url,picture_name) #下载图片
time.sleep(random.randint(1,3)) if __name__ == "__main__":
url_lists = ['https://www.pexels.com/search/book/?page={}'.format(i) for i in range(1,21)]
for url in url_lists:
get_picture(url,'/root/pexels')
Python爬虫获取异步加载站点pexels并下载图片(Python爬虫实战3)的更多相关文章
- 【vue】获取异步加载后的数据
异步请求的数据,对它做一些处理,需要怎么做呢?? axios 异步请求数据,得到返回的数据, 赋值给变量 info .如果要对 info 的数据做一些处理后再赋值给 hobby ,直接在 axios ...
- Python 爬取异步加载的数据
在我们的工作中,可能会遇到这样的情况:我们需要爬取的数据是通过ajax异步加载的,这样的话通过requests得到的只是一个静态页面,而我们需要的是ajax动态加载的数据! 那我们应该怎么办呢??? ...
- Java 爬虫遇上数据异步加载,试试这两种办法!
这是 Java 爬虫系列博文的第三篇,在上一篇 Java 爬虫遇到需要登录的网站,该怎么办? 中,我们简单的讲解了爬虫时遇到登录问题的解决办法,在这篇文章中我们一起来聊一聊爬虫时遇到数据异步加载的问题 ...
- UIImageView异步加载网络图片
在iOS开发过程中,经常会遇到使用UIImageView展现来自网络的图片的情况,最简单的做法如下: 去下载https://github.com/rs/SDWebImage放进你的工程里,加入头文件# ...
- 多线程异步加载图片async_pictures
异步加载图片 目标:在表格中异步加载网络图片 目的: 模拟 SDWebImage 基本功能实现 理解 SDWebImage 的底层实现机制 SDWebImage 是非常著名的网络图片处理框架,目前国内 ...
- Unity 异步加载场景
效果图如下: 今天一直在纠结如何加载场景,中间有加载画面和加载完毕的效果动画! A 场景到 B , 看见网上的做法都是 A –> C –> B. C场景主要用于异步加载B 和 播放一些 ...
- ios UIImageView异步加载网络图片
方法1:在UI线程中同步加载网络图片 UIImageView *headview = [[UIImageView alloc] initWithFrame:CGRectMake(0, 0, 40, 4 ...
- Android批量图片加载经典系列——使用xutil框架缓存、异步加载网络图片
一.问题描述 为提高图片加载的效率,需要对图片的采用缓存和异步加载策略,编码相对比较复杂,实际上有一些优秀的框架提供了解决方案,比如近期在git上比较活跃的xutil框架 Xutil框架提供了四大模块 ...
- [翻译]Bitmap的异步加载和缓存
内容概述 [翻译]开发文档:android Bitmap的高效使用 本文内容来自开发文档"Traning > Displaying Bitmaps Efficiently", ...
随机推荐
- 高可用之KeepAlived(一):基本概念和配置文件分析
*/ .hljs { display: block; overflow-x: auto; padding: 0.5em; color: #333; background: #f8f8f8; } .hl ...
- java-redis集合数据操作示例(三)
redis系列博文,redis连接管理类的代码请跳转查看<java-redis字符类数据操作示例(一)>. 一.集合类型缓存测试类 public class SetTest { /** * ...
- Yii2中JSONP跨域问题的解决
Jsonp(JSON with Padding) 是 json 的一种"使用模式",可以让网页从别的域名(网站)那获取资料,即跨域读取数据. 为什么我们从不同的域(网站)访问数据需 ...
- 《清华梦的粉碎》by王垠
清华梦的诞生 小时候,妈妈给我一个梦.她指着一个大哥哥的照片对我说,这是爸爸的学生,他考上了清华大学,他是我们中学的骄傲.长大后,你也要进入清华大学读书,为我们家争光.我不知道清华是什么样子,但是我 ...
- Frequent Pattern (FP Growth算法)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达 到这样的效果,它采用了一种简洁的数据 ...
- nginx笔记6-总结
1.轮询(默认)每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除.2.weight指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况.3.ip_ ...
- linux ftp及C/S服务架构
乱码转换工具使用convmv软件:windows中文字符编码为GB2312 linux中文字符编码为utf-8选项:-f:源文件中中文字符编码-t:转换成字符编码-r:代表递归--notest:不测试 ...
- AM335x(TQ335x)学习笔记——LCD驱动移植
TI的LCD控制器驱动是非常完善的,共通的地方已经由驱动封装好了,与按键一样,我们可以通过DTS配置完成LCD的显示.下面,我们来讨论下使用DTS方式配置内核完成LCD驱动的思路. (1)初步分析 由 ...
- Flex中利用单选按钮切换柱状图横纵坐标以及描述
1.问题描述 一组单选按钮,有周和月之分,选择"周",柱状图横坐标显示的是周,纵坐标显示的是人数:选择"月",柱状图横坐标显示的月,纵坐标显示的是比率. 2.演 ...
- Radar Installation POJ - 1328
Assume the coasting is an infinite straight line. Land is in one side of coasting, sea in the other. ...