Python 爬虫——抖音App视频抓包
APP抓包
前面我们了解了一些关于 Python 爬虫的知识,不过都是基于 PC 端浏览器网页中的内容进行爬取。现在手机 App 用的越来越多,而且很多也没有网页端,比如抖音就没有网页版,那么上面的视频就没法批量抓取了吗?
答案当然是 No!对于 App 来说应用内的通信过程和网页是类似的,都是向后台发送请求,获取数据。在浏览器中我们打开调试工具就可以看到具体的请求内容,在 App 中我们无法直接看到。所以我们就要通过抓包工具来获取到 App 请求与响应的信息。关于抓包工具有 Wireshark,Fiddler,Charles等。今天我们讲一下如何用 Fiddler 进行手机 App 的抓包。
Fiddler 的工作原理相当于一个代理,配置好以后,我们从手机 App 发送的请求会由 Fiddler 发送出去,服务器返回的信息也会由 Fiddler 中转一次。所以通过 Fiddler 我们就可以看到 App 发给服务器的请求以及服务器的响应了。
Fiddler 安装配置
我们安装好 Fiddler 后,首先在菜单 Tool>Options>Https 下面的这两个地方选上。
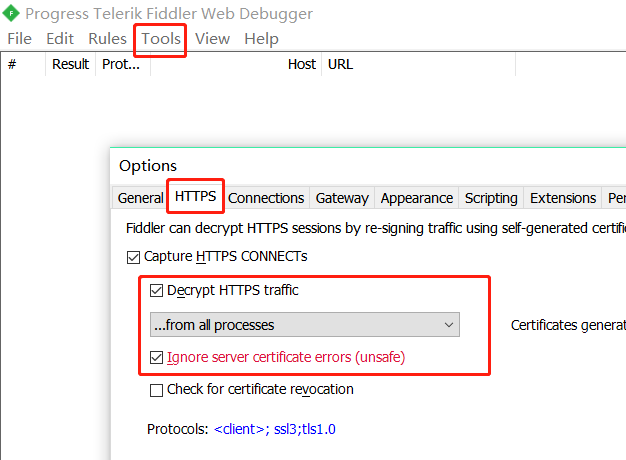
然后在 Connections 标签页下面勾选上 Allow remote computers to connect,允许 Fiddler 接受其他设备的请求。
同时要记住这里的端口号,默认是 8088,到时候需要在手机端填。
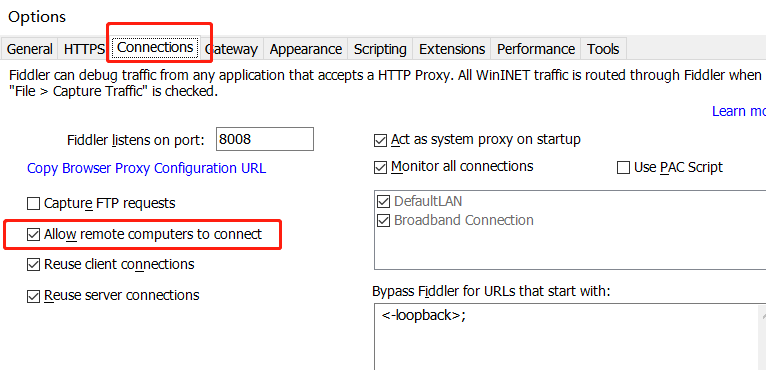
配置完毕,保存后,一定关掉 Fiddler 重新打开。
手机端配置
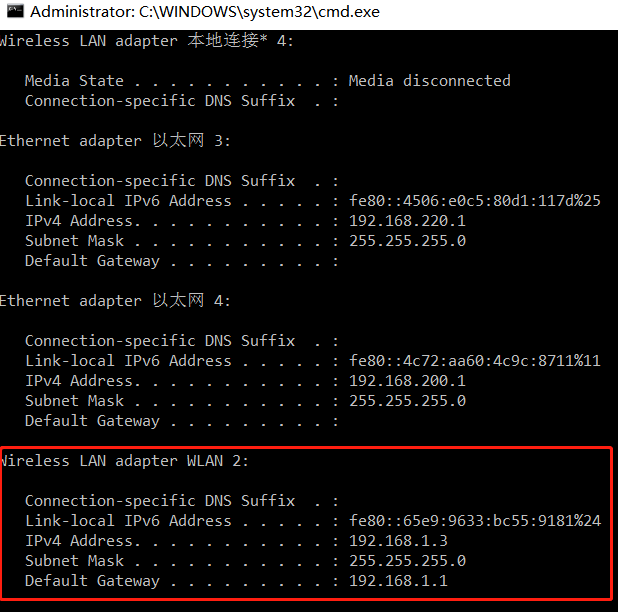
确保手机和电脑在同一个局域网中,我们先看下计算机的 IP 地址,在 cmd 中输入 ipconfig 就可以看到。我电脑用的是无线网,所以 IP 地址为 192.168.1.3。
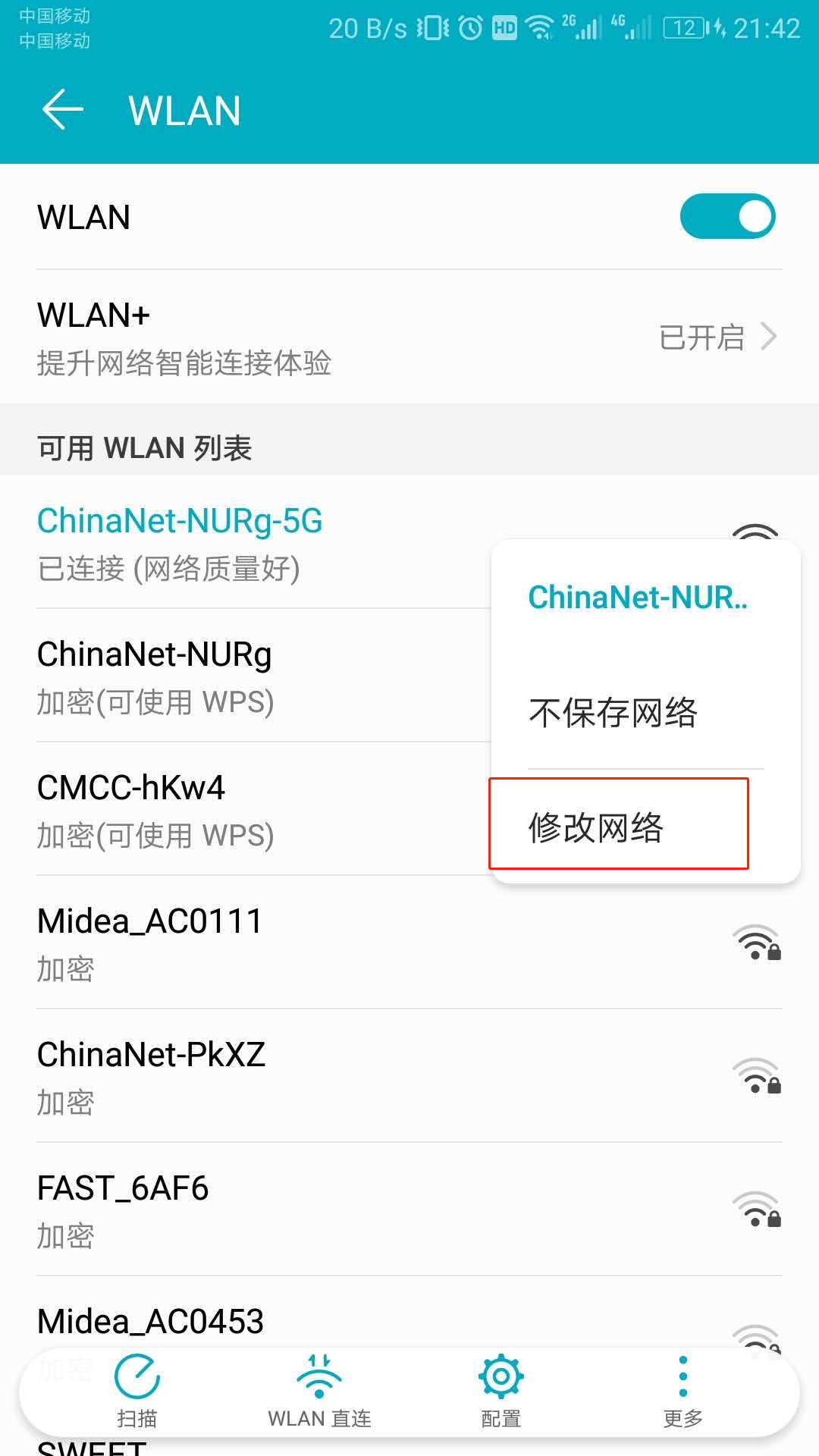
打开手机无线连接,选择要连接的热点。长按选择修改网络,在代理中填上我们电脑的 IP 地址和 Fiddler 代理的端口。如下图所示:
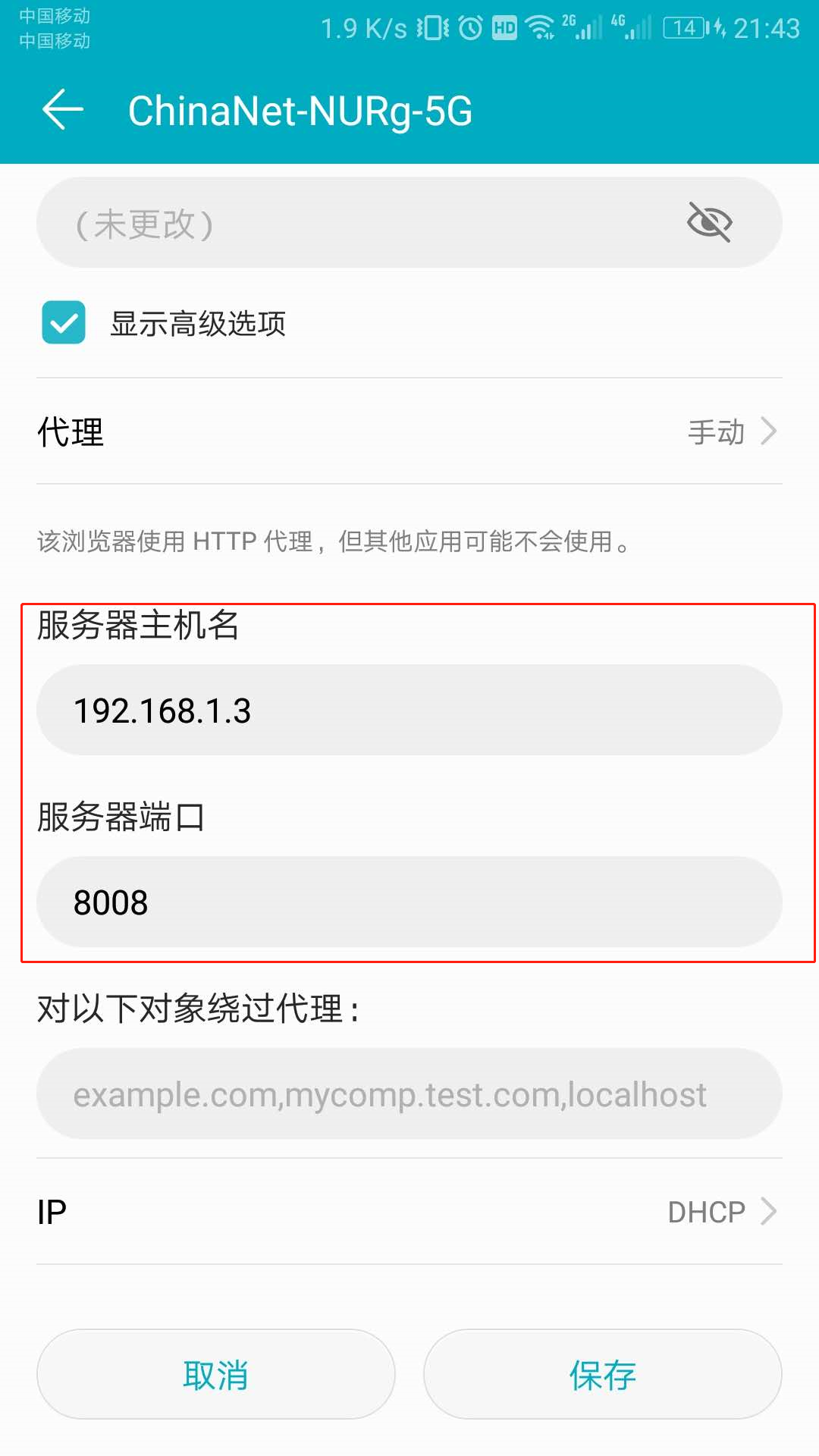
保存后,在手机原生浏览器打开 http://192.168.1.3:8008 ,就是上面我们的计算机 IP 和端口。这一步我在夸克浏览器中打开是不行的,一定要到手机自带的浏览器打开。
打开后,点击下图链接,下载证书,然后安装证书。
电脑端浏览器也需要打开此地址,安装证书,方便以后对浏览器的抓包操作。
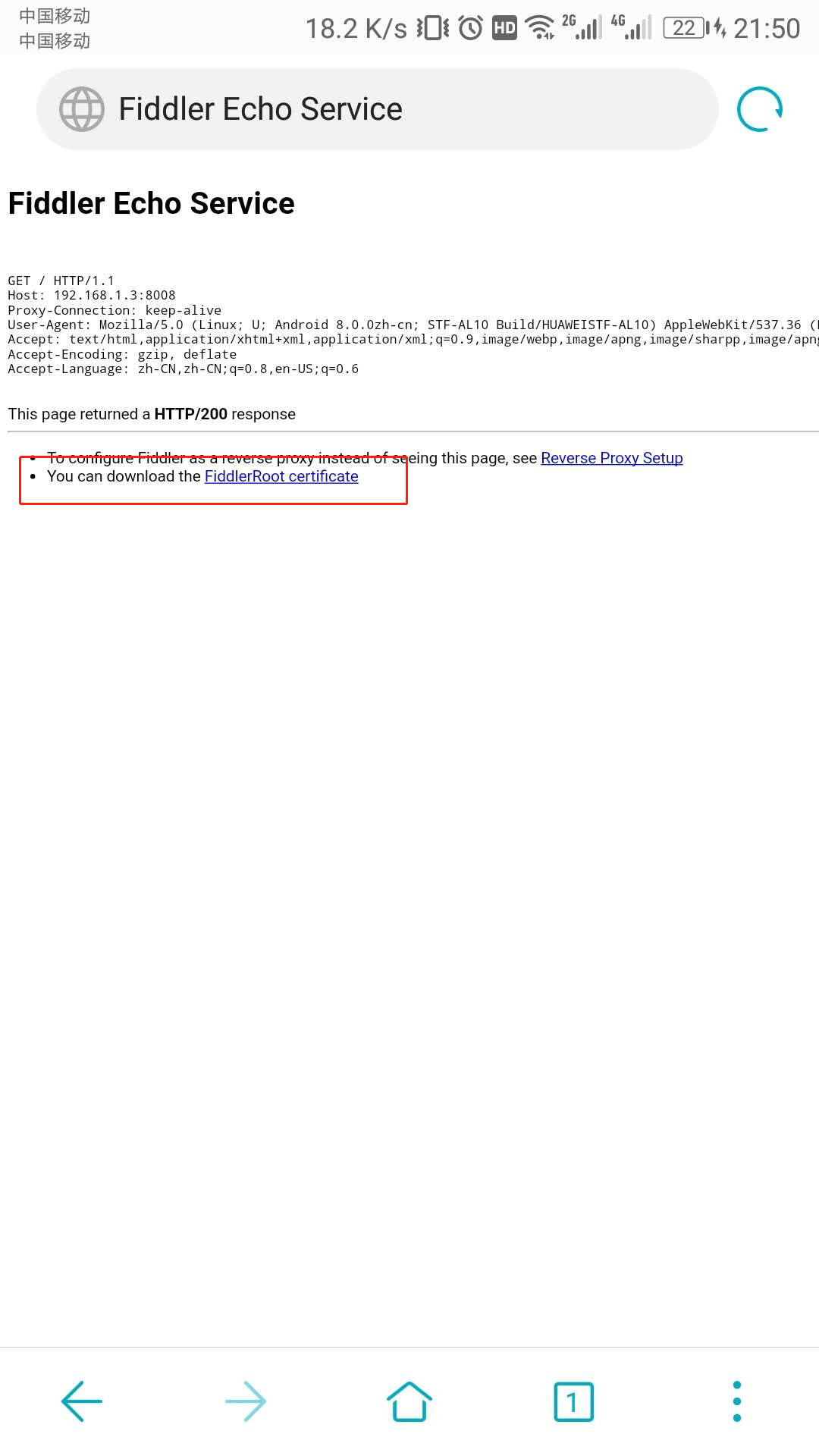
安装后就万事 OK 了,可以用手机打开 App ,在 Fiddler 上愉快的抓包了。
抓包
我们打开抖音 App,会发现 Fiddler 上出来很多连接。我们先清空没用的连接信息,然后滑动到某个人的主页上,来查看他发布过的所有视频,同时在 Fiddler 上找到视频链接。
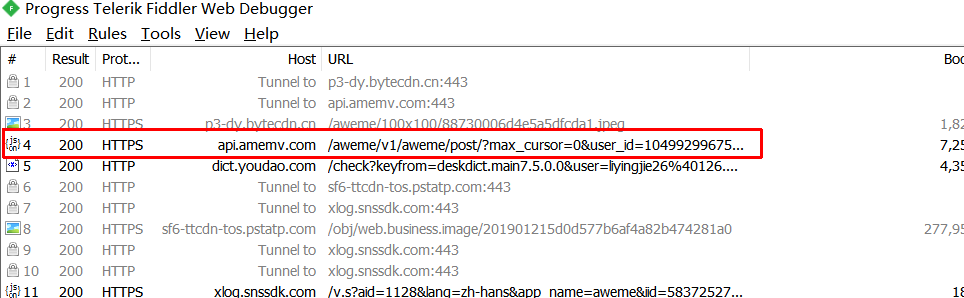
经过观察筛选我们可以看出上图就是我们需要的请求地址,这个地址其实是可以在浏览器上打开的,但是我们需要改一下浏览器的User-Agent,我用的是Firefox的插件,打开后和 Fiddler 右边的信息是一致的。我们看下 Fiddler 右边该请求的响应信息。
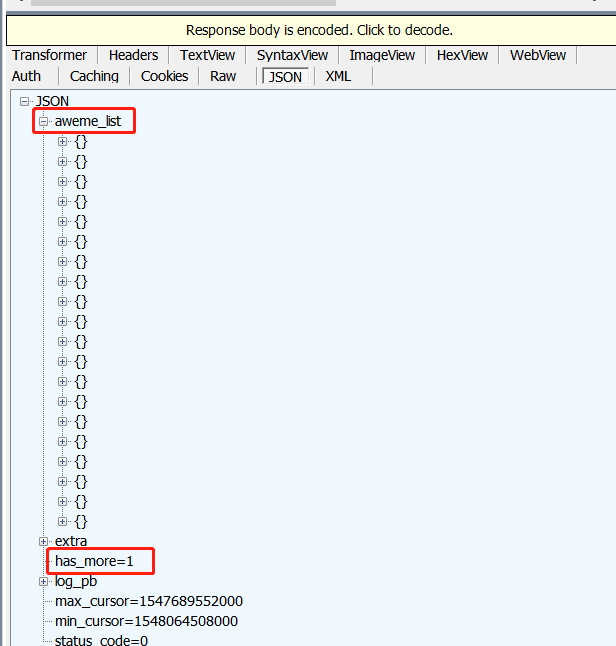
看到返回了一个 JSON 格式的信息,其中aweme_list 就是我们需要的视频地址,has_more=1 表示往上滑动还会加载更多。之后就可以写代码了。
代码
代码很简单,和我们前几篇讲的一样,直接用 requests 请求相应链接即可。
代码仅做为一个简单的例子,仅仅下载当前页面的内容,如果要下载全部的视频,可以根据当次返回 JSON 结果中的 has_more 和 max_cursor 参数构造出新的 URL 地址不断的下载。
URL 中的 user_id 可以根据自己要爬取的用户更改,可以通过把用户分享到微信,然后在浏览器中打开链接,在打开的 URL 中可以看到用户的 user_id。
import requests
import urllib.request
def get_url(url):
headers = {'user-agent': 'mobile'}
req = requests.get(url, headers=headers, verify=False)
data = req.json()
for data in data['aweme_list']:
name = data['desc'] or data['aweme_id']
url = data['video']['play_addr']['url_list'][0]
urllib.request.urlretrieve(url, filename=name + '.mp4')
if __name__ == "__main__":
get_url('https://api.amemv.com/aweme/v1/aweme/post/?max_cursor=0&user_id=98934041906&count=20&retry_type=no_retry&mcc_mnc=46000&iid=58372527161&device_id=56750203474&ac=wifi&channel=huawei&aid=1128&app_name=aweme&version_code=421&version_name=4.2.1&device_platform=android&ssmix=a&device_type=STF-AL10&device_brand=HONOR&language=zh&os_api=26&os_version=8.0.0&uuid=866089034995361&openudid=008c22ca20dd0de5&manifest_version_code=421&resolution=1080*1920&dpi=480&update_version_code=4212&_rticket=1548080824056&ts=1548080822&js_sdk_version=1.6.4&as=a1b51dc4069b2cc6252833&cp=dab7ca5f68594861e1[wIa&mas=014a70c81a9db218501e1433b04c38963ccccc1c4cac4c6cc6c64c')
运行后就可以得到视频列表:

有任何疑问,欢迎加我微信交流。
Python 爬虫——抖音App视频抓包的更多相关文章
- Python爬虫-抖音小视频-mitmproxy与Appium
目的: 爬取抖音小视频 工具: mitmproxy.Appium 思路: 1. 通过 mitmproxy 截取请求, 找出 response 为 video 的请求. 2. 通过 mitmdu ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
抖音很火,楼主使用python随机爬取抖音视频,并且无水印下载,人家都说天下没有爬不到的数据,so,楼主决定试试水,纯属技术爱好,分享给大家.. 1.楼主首先使用Fiddler4来抓取手机抖音app这 ...
- 教你用python爬取抖音app视频
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思 ...
- python爬虫——抖音数据
最近挺火的抖音短视频,不仅带火了一众主播,连不少做电商的也进驻其中,于是今天我来扒一扒这火的不要不要的抖音数据: 一.抓包工具获取用户ID 对于手机app数据,抓包是最直接也是最常见的手段,常用的抓包 ...
- python爬虫抖音 个人资料 仅供学习参考 切勿用于商业
本文仅供学习参考 切勿用于商业 本次爬取使用fiddler+模拟器(下载抖音APP)+pycharm 1. 下载最新版本的fiddler(自行百度下载),以及相关配置 1.1.依次点击,菜单栏-Too ...
- python爬虫用drony转发进行抓包转发
转载至https://www.cnblogs.com/lulianqi/p/11380794.html#l_2 实际操作步骤(Android) 笔者这里直接使用上面提到第3种方法(方法1在对于手机AP ...
- python爬虫01在Chrome浏览器抓包
尽量不要用国产浏览器,很多是有后门的 chrome是首选 百度 按下F12 element标签下对应的HTML代码 点击Network,可以看到很多请求 HTTP请求的方式有好几种,GET,POST, ...
- python爬取抖音APP视频教程
本文讲述爬取抖音APP视频数据(本文未完,后面还有很多地方优化总结) 公众号回复:抖音 即可获取源码 1.APP抓包教程,需要用到fiddler fiddler配置和使用查看>>王者荣耀盒 ...
随机推荐
- Thymeleaf利用layout.html文件生成页面布局框架
1.layout.html文件 生成布局 <!DOCTYPE html> <html lang="zh-CN" xmlns:th="http://www ...
- java获取一个月的天数
import java.text.SimpleDateFormat; import java.util.Calendar; public class Test { public static void ...
- Python /usr/bin/python
#!/usr/bin/python是告诉操作系统执行这个脚本的时候,调用/usr/bin下的python解释器: #!/usr/bin/env python这种用法是为了防止操作系统用户没有将pyth ...
- 连接Redis后执行命令错误 MISCONF Redis is configured to save RDB snapshots
今天在redis中执行setrange name 1 chun 命令时报了如下错误提示: (error) MISCONF Redis is configured to save RDB snapsho ...
- nsqlookupd.go
) } l.Lock() l.httpListener = httpListener l.Unlock() httpServer := newHTTPServe ...
- java集合框架之LinkedList
参考http://how2j.cn/k/collection/collection-linkedlist/370.html LinkedList 与 List接口 与ArrayList一样,Linke ...
- B20J_2733_[HNOI2012]永无乡_权值线段树合并
B20J_2733_[HNOI2012]永无乡_权值线段树合并 Description:n座岛,编号从1到n,每座岛都有自己的独一无二的重要度,按照重要度可以将这n座岛排名,名次用1到 n来表示.某些 ...
- 聊聊Socket、TCP/IP、HTTP、FTP及网络编程
1 这些都是什么 既然是网络传输,涉及几个系统之间的交互,那么首先要考虑的是如何准确的定位到网络上的一台或几台主机,另一个是如何进行可靠高效的数据传输.这里就要使用到TCP/IP协议. 1.1 TCP ...
- XMR挖矿教程
XMR挖矿教程 XMR介绍 门罗币(Monero,代号XMR)是一个创建于2014年4月开源加密货币,它着重于隐私.分权和可扩展性.与自比特币衍生的许多加密货币不同,Monero基于CryptoNot ...
- set的便捷操作
认识集合 由一个或多个确定的元素所构成的整体叫做集合. 集合中的元素有三个特征: 1.确定性(集合中的元素必须是确定的) 2.互异性(集合中的元素互不相同.例如:集合A={1,a},则a不能等于1) ...