from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p/9635097.html
抖音很火,楼主使用python随机爬取抖音视频,并且无水印下载,人家都说天下没有爬不到的数据,so,楼主决定试试水,纯属技术爱好,分享给大家。。
1.楼主首先使用Fiddler4来抓取手机抖音app这个包,具体配置的操作,网上有很多教程供大家参考。
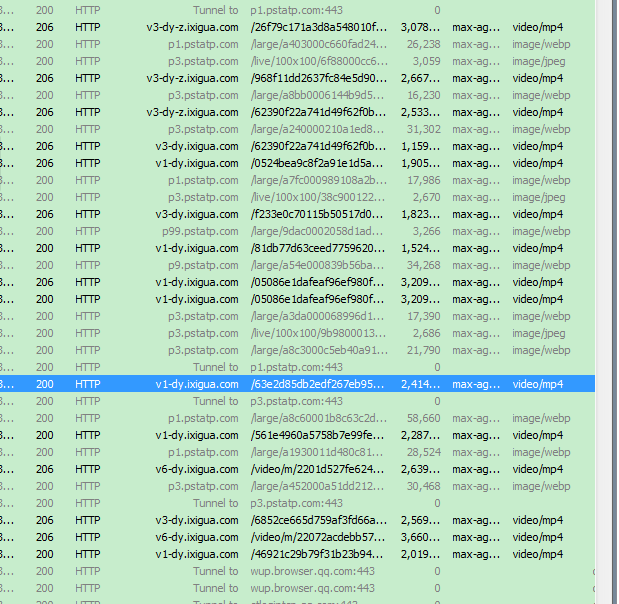
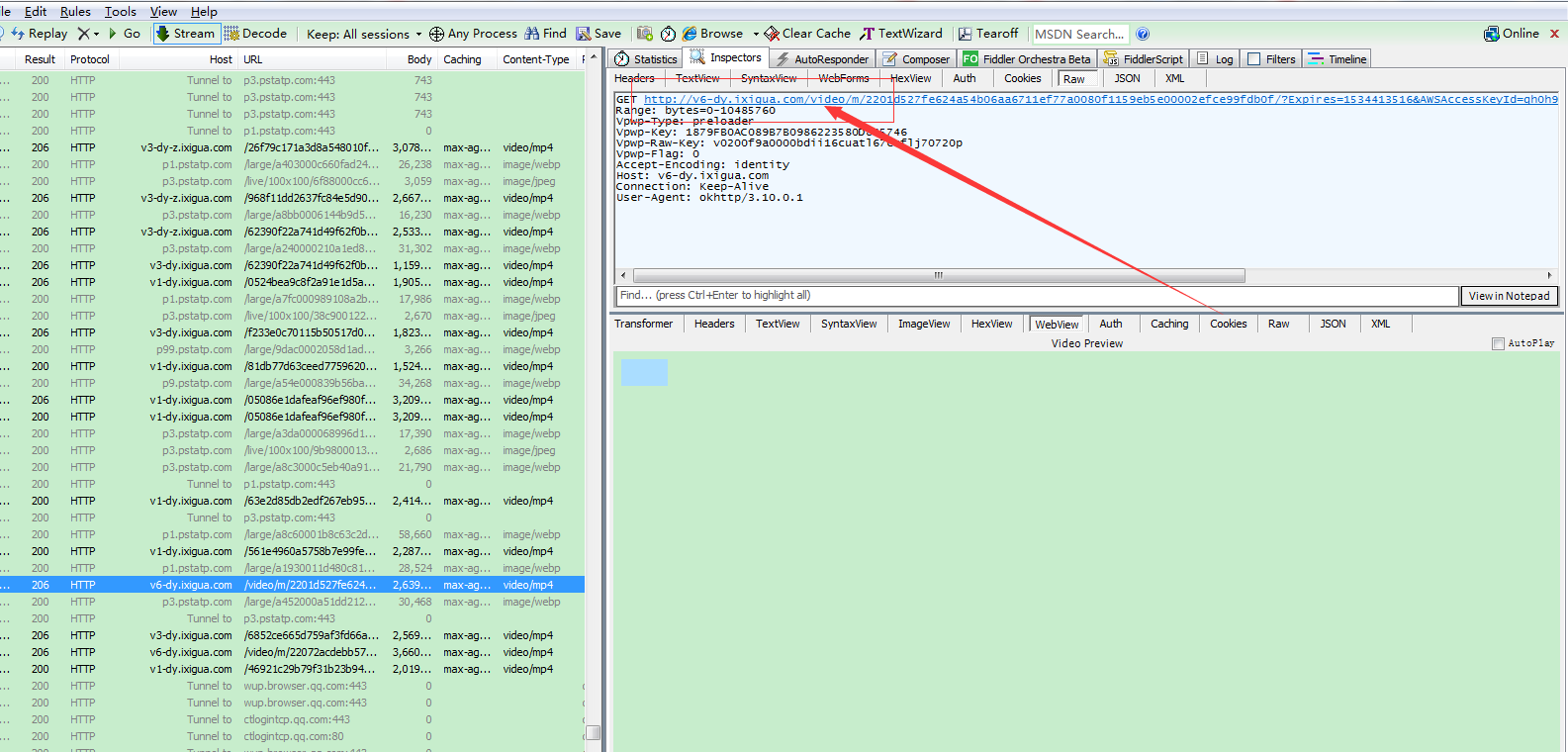
上面得出抖音的视频的url,这些url均能在网页中打开,楼主数了数,这些url的前缀有些不同,一共有这4种类型:
v1-dy.ixigua.com
v3-dy.ixigua.com
v6-dy.ixigua.com
v9-dy.ixigua.com
楼主查看这四种类型得知,v6-dy.ixigua.com 这个前缀后面的参数其中有一个是Expires(中文含义过期的意思)
Expires=1536737310,这个是时间戳,标记的是过期的时间如下图所示,过了15:28分30秒,则表示url不能使用,楼主算了一下,url有效期是一个小时。

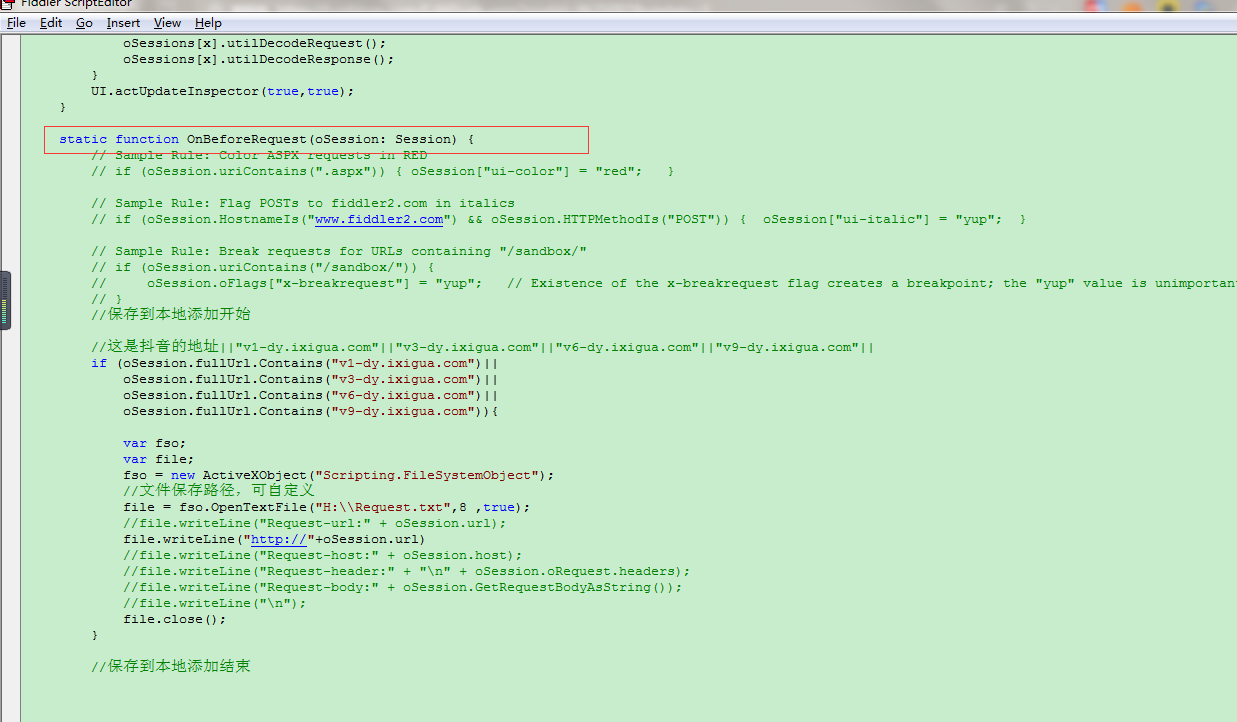
看到这些url,楼主不能手动一个一个粘贴,so楼主需要在+Fiddler4中(在Fiddler4使用script代码网上有大量详细教程)使用如下代码,自动保存到一个txt文档中。

//保存到本地添加开始
//这是抖音的地址||"v1-dy.ixigua.com"||"v3-dy.ixigua.com"||"v6-dy.ixigua.com"||"v9-dy.ixigua.com"||
if (oSession.fullUrl.Contains("v1-dy.ixigua.com")||
oSession.fullUrl.Contains("v3-dy.ixigua.com")||
oSession.fullUrl.Contains("v6-dy.ixigua.com")||
oSession.fullUrl.Contains("v9-dy.ixigua.com")){
var fso;
var file;
fso = new ActiveXObject("Scripting.FileSystemObject");
//文件保存路径,可自定义
file = fso.OpenTextFile("H:\\Request.txt",8 ,true);
//file.writeLine("Request-url:" + oSession.url);
file.writeLine("http://"+oSession.url)
//file.writeLine("Request-host:" + oSession.host);
//file.writeLine("Request-header:" + "\n" + oSession.oRequest.headers);
//file.writeLine("Request-body:" + oSession.GetRequestBodyAsString());
//file.writeLine("\n");
file.close();
}
//保存到本地添加结束
把上边的代码插入到如下图所示的地方即可。
2.上面的url是楼主手动点击一个个刷新抖音app出现的,so楼主使用appium来自动刷新抖音app,自动获得url,自动保存到txt文档中。
首先需要在appium中得到抖音这个app包的一些用的信息,如下图所示

楼主使用的是红米手机,至于appium怎么安装配置,大家可参考网上相关教程,appium客户端连接上手机(需要数据线连接)后,在控制台打印出log日志文件,在日志文件中找到这四个参数即可,然后保存
到appium客户端中即可,就能在appium客户端中操作抖音app。
{
"platformName": "Android",
"deviceName": "Redmi Note5",
"appPackage": "com.ss.android.ugc.aweme",
"appActivity": ".main.MainActivity"
}
appPackage这一项com.ss.android.ugc.aweme 则表示抖音短视频。


楼主使用如下代码来实现无限刷新抖音app,前提是需要手机连着数据线连在电脑上并且开启appium客户端的服务和打开Fiddler4抓包(配置好环境手机)。
from appium import webdriver
from time import sleep ##以下代码可以操控手机app
class Action():
def __init__(self):
# 初始化配置,设置Desired Capabilities参数
self.desired_caps = {
"platformName": "Android",
"deviceName": "Mi_Note_3",
"appPackage": "com.ss.android.ugc.aweme",
"appActivity": ".main.MainActivity"
}
# 指定Appium Server
self.server = 'http://localhost:4723/wd/hub'
# 新建一个Session
self.driver = webdriver.Remote(self.server, self.desired_caps)
# 设置滑动初始坐标和滑动距离
self.start_x = 500
self.start_y = 1500
self.distance = 1300 def comments(self):
sleep(3)
# app开启之后点击一次屏幕,确保页面的展示
self.driver.tap([(500, 1200)], 500)
def scroll(self):
# 无限滑动
while True:
# 模拟滑动
self.driver.swipe(self.start_x, self.start_y, self.start_x,
self.start_y - self.distance)
# 设置延时等待
sleep(5)
def main(self):
self.comments()
self.scroll() if __name__ == '__main__':
action = Action()
action.main()
楼主运行次代码就能在Fiddler4中得到无限量的url。
3.楼主拿到url后,会发现有些url会重复,so楼主加入了去重的功能,为了好看楼主也加入了进度条花里花哨的功能,运行代码最终会下载下来。
# _*_ coding: utf-8 _*_
import requests
import sys
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36" } ##去重方法
def distinct_data():
##读取txt中文档的url列表
datalist_blank=[]
pathtxt='H:/Request.txt'
with open(pathtxt) as f:
f_data_list=f.readlines()#d得到的是一个list类型
for a in f_data_list:
datalist_blank.append(a.strip())#去掉\n strip去掉头尾默认空格或换行符
# print(datalist)
data_dict={}
for data in datalist_blank:
#print(type(data),data,'\n')
#print(data.split('/'),'\n',data.split('/').index('m'),'\n')
#url中以/为切分,在以m为切分 ##把m后面的值放进字典key的位置,利用字典特性去重
if int(data.split('/').index('m'))==4 :#此处为v6开头的url
#print(data,44,data.split('/')[5])
data_key1=data.split("/")[5]
data_dict[data_key1]=data
elif int(data.split('/').index('m'))==6: #此处为v1或者v3或者v9开头的url
#print(data,66,data.split('/')[7],type(data.split('/')[7]))
data_key2=data.split("/")[7]
data_dict[data_key2] =data
#print(len(data_dict),data_dict)
data_new=[]
for x,y in data_dict.items():
data_new.append(y)
return data_new def responsedouyin():
data_url=distinct_data()
# 使用request获取视频url的内容
# stream=True作用是推迟下载响应体直到访问Response.content属性
# 将视频写入文件夹
num = 1
for url in data_url:
res = requests.get(url,stream=True,headers=headers)
#res = requests.get(url=url, stream=True, headers=headers)
#定义视频存放的路径
pathinfo = 'H:/douyin-video/%d.mp4' % num #%d 用于整数输出 %s用于字符串输出
# 实现下载进度条显示,这一步需要得到总视频大小
total_size = int(res.headers['Content-Length'])
#print('这是视频的总大小:',total_size)
#设置流的起始值为0
temp_size = 0
if res.status_code == 200:
with open(pathinfo, 'wb') as file:
#file.write(res.content)
#print(pathinfo + '下载完成啦啦啦啦啦')
num += 1
#当流下载时,下面是优先推荐的获取内容方式,iter_content()函数就是得到文件的内容,指定chunk_size=1024,大小可以自己设置哟,设置的意思就是下载一点流写一点流到磁盘中
for chunk in res.iter_content(chunk_size=1024):
if chunk:
temp_size += len(chunk)
file.write(chunk)
file.flush() #刷新缓存
#############下载进度条部分start###############
done = int(50 * temp_size / total_size)
#print('百分比:',done)
sys.stdout.write("\r[%s%s] %d % %" % ('█' * done, ' ' * (50 - done), 100 * temp_size / total_size)+" 下载信息:"+pathinfo + "下载完成啦啦啦啦啦")
sys.stdout.flush()#刷新缓存
#############下载进度条部分end###############
print('\n')#每一条打印在屏幕上换行输出 if __name__ == '__main__':
responsedouyin()
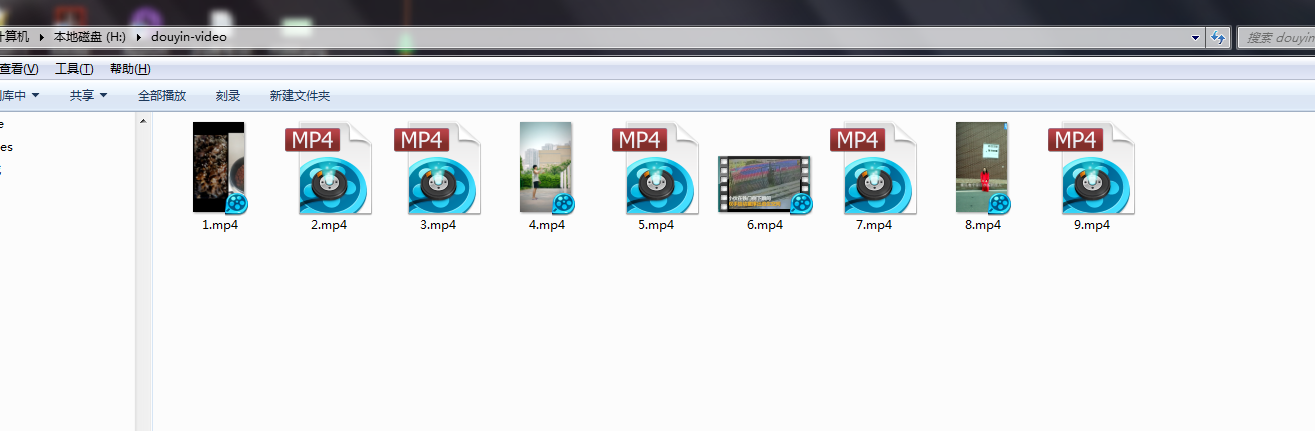
运行代码,效果图如下

视频最终保存到文件夹中
github地址:https://github.com/Stevenguaishushu/douyin
from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)的更多相关文章
- 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
抖音很火,楼主使用python随机爬取抖音视频,并且无水印下载,人家都说天下没有爬不到的数据,so,楼主决定试试水,纯属技术爱好,分享给大家.. 1.楼主首先使用Fiddler4来抓取手机抖音app这 ...
- 教你用python爬取抖音app视频
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思 ...
- python爬取抖音APP视频教程
本文讲述爬取抖音APP视频数据(本文未完,后面还有很多地方优化总结) 公众号回复:抖音 即可获取源码 1.APP抓包教程,需要用到fiddler fiddler配置和使用查看>>王者荣耀盒 ...
- Python爬虫---爬取抖音短视频
目录 前言 抖音爬虫制作 选定网页 分析网页 提取id构造网址 拼接数据包链接 获取视频地址 下载视频 全部代码 实现结果 待解决的问题 前言 最近一直想要写一个抖音爬虫来批量下载抖音的短视频,但是经 ...
- Python爬虫一爬取B站小视频源码
如果要爬取多页的话 在最下方循环中 填写好循环的次数就可以了 项目源码 from fake_useragent import UserAgent import requests import time ...
- Python爬虫:爬取美拍小姐姐视频
最近在写一个应用,需要收集微博上一些热门的视频,像这些小视频一般都来自秒拍,微拍,美拍和新浪视频,而且没有下载的选项,所以只能动脑想想办法了. 第一步 分析网页源码. 例如:http://video. ...
- Python爬虫-抖音小视频-mitmproxy与Appium
目的: 爬取抖音小视频 工具: mitmproxy.Appium 思路: 1. 通过 mitmproxy 截取请求, 找出 response 为 video 的请求. 2. 通过 mitmdu ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- Python 爬虫——抖音App视频抓包
APP抓包 前面我们了解了一些关于 Python 爬虫的知识,不过都是基于 PC 端浏览器网页中的内容进行爬取.现在手机 App 用的越来越多,而且很多也没有网页端,比如抖音就没有网页版,那么上面的视 ...
随机推荐
- VS code配置go语言开发环境之自定义快捷键及其对应操作
VS code 配置 自定义快捷键 及其对应操作 由于 vs code 的官方 go 插件不支持像 goland 一样运行当前 go 文件, 只能项目 或者 package 级别地运行, 因此有必 ...
- Effective Java 第三版——81. 优先使用并发实用程序替代wait和notify
Tips 书中的源代码地址:https://github.com/jbloch/effective-java-3e-source-code 注意,书中的有些代码里方法是基于Java 9 API中的,所 ...
- Future、FutureTask实现原理浅析(源码解读)
前言 最近一直在看JUC下面的一些东西,发现很多东西都是以前用过,但是真是到原理层面自己还是很欠缺. 刚好趁这段时间不太忙,回来了便一点点学习总结. 前言 最近一直在看JUC下面的一些东西,发现很多东 ...
- 【转】Java并发的AQS原理详解
申明:此篇文章转载自:https://juejin.im/post/5c11d6376fb9a049e82b6253写的真的很棒,感谢老钱的分享. 打通 Java 任督二脉 —— 并发数据结构的基石 ...
- Android Studio 好用的设置
Android Studio 好用的设置 设置目录 Getter 模板修改--自动处理 null 判断 格式化代码自动整理方法位置--广度 or 深度 设置步骤: Getter 模板修改,自动处理 n ...
- 关于python单例的常用几种实现方法
这两天在看自己之前写的代码,所以正好把用过的东西整理一下,单例模式,在日常的代码工作中也是经常被用到, 所以这里把之前用过的不同方式实现的单例方式整理一下 装饰器的方式 这种方式也是工作中经常用的一种 ...
- C#中,重新排列panel中的按钮
https://www.cnblogs.com/hfzsjz/archive/2010/08/13/1799068.html void ArrangeButtons(Panel pn) { , y = ...
- Eclipse Maven编译报不支持muti-catch
最近几次使用maven编译,总是报一下的错误:source 1.6 中不支持 multi-catch 语句,(请使用 -source 7 或更高版本以启用 multi-catch 语句) 问题很清楚, ...
- Variable number of arguments (Varargs)
A parameter of a function (normally the last one) may be marked with vararg modifier: fun <T> ...
- windows下JDK环境配置与Android SDK环境配置
一.JDK环境配置1.配置变量名:JAVA_HOME变量值:jdk安装的绝对路径. 变量名:Path(在系统变量中找到并选中Path点击下面的编辑按钮,不要删除原本变量值中的任何一个字母,在这个变量值 ...