java爬虫系列第二讲-爬取最新动作电影《海王》迅雷下载地址
1. 目标
使用webmagic爬取动作电影列表信息

爬取电影《海王》详细信息【电影名称、电影迅雷下载地址列表】
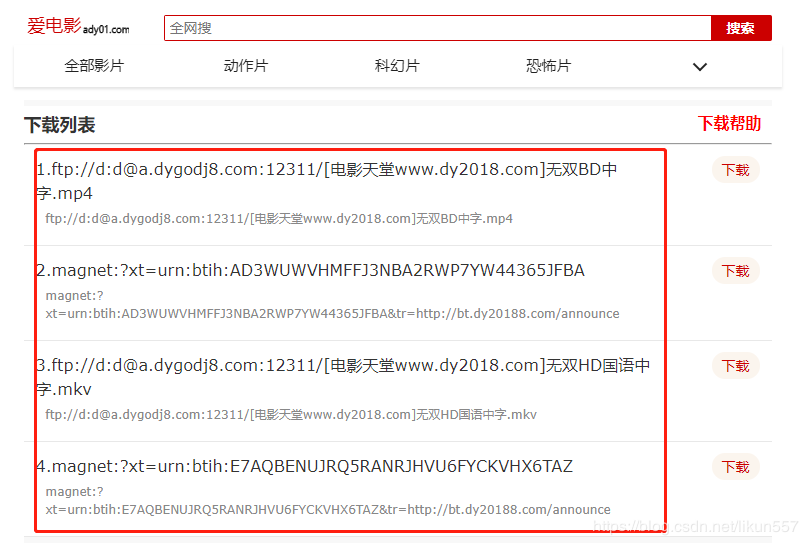
2. 爬取最新动作片列表
获取电影列表页面数据来源地址
访问http://m.ady01.com/rs/film/list/1/1,F12开发者模式中找到页面数据来源地址
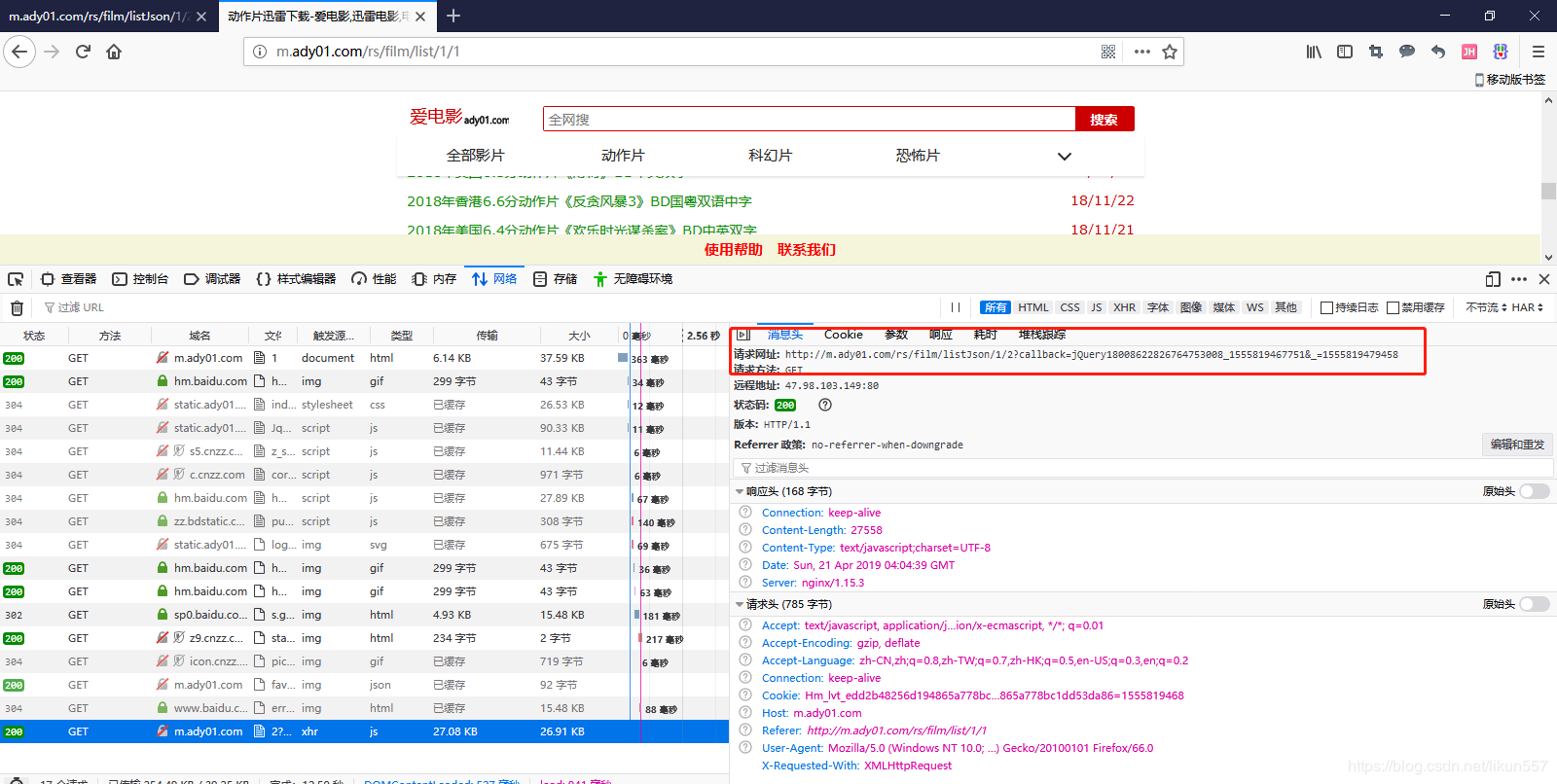
地址是:http://m.ady01.com/rs/film/listJson/1/1
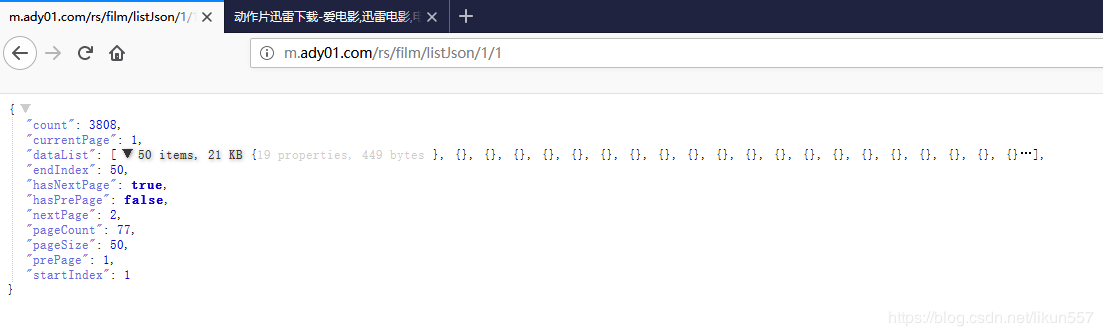
访问:http://m.ady01.com/rs/film/listJson/1/1
抓取列表信息
使用git拉取代码:https://gitee.com/likun_557/java-pachong 这个代码是在第一讲中创建的,需要了解的朋友可以查看第一讲的内容"《java爬虫系列第一讲-爬虫入门》"
将代码导入idea中
新建包com.ady01.demo2.filmlist,本次示例代码全部放在该包中
列表页面数据来源http://m.ady01.com/rs/film/listJson/1/1,是一个json数据
根据http://m.ady01.com/rs/film/listJson/1/1中的数据格式,我们先分析一下
- 最外层是一个分页的类
- dataList是一个集合,内部每项是一个电影资源的信息
创建com.ady01.demo2.filmlist.PageModel类,用于保存分页电影信息
package com.ady01.demo2.filmlist; import lombok.*; import java.io.Serializable;
import java.util.List; /**
* <b>description</b>:分页对象 <br>
* <b>time</b>:2019-04-21 13:46 <br>
* <b>author</b>: 微信公众号:路人甲Java,专注于java技术分享(爬虫、分布式事务、异步消息服务、任务调度、分库分表、大数据等),喜欢请关注!
*/
@Getter
@Setter
@NoArgsConstructor
@ToString
public class PageModel implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 每页显示数量
*/
private long pageSize;
/**
* 当前页行的开始行的索引,如1,2,3....
*/
private long startIndex;
/**
* 当前页行的结束索引
*/
private long endIndex;
/**
* 当前页
*/
private long currentPage; /**
* 上一页索引
*/
private long prePage; /**
* 下一页索引
*/
private long nextPage; /**
* 总记录数
*/
private long count; /**
* 是否有上一页
*/
private boolean hasPrePage; /**
* 是否有下一页
*/
private boolean hasNextPage; /**
* 总页数
*/
private long pageCount; /**
* 数据集合
*/
private List<FilmModel> dataList;
}
创建com.ady01.demo2.filmlist.FilmModel类,用于保存电影信息
package com.ady01.demo2.filmlist; import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString; import java.io.Serializable;
import java.util.Map; /**
* <b>description</b>:电影信息 <br>
* <b>time</b>:2019/4/21 12:35 <br>
* <b>author</b>:微信公众号:路人甲Java,专注于java技术分享(爬虫、分布式事务、异步消息服务、任务调度、分库分表、大数据等),喜欢请关注!
*/
@Setter
@Getter
@NoArgsConstructor
@ToString
public class FilmModel implements Serializable{
private static final long serialVersionUID = 1L;
/**
* 编号
*/
private java.lang.Long id;
/**
* 片名,完整名称,不包含无关文字
*/
private java.lang.String name;
/**
* 片名全拼音(小写),如英雄:yingxiong
*/
private java.lang.String full_spell;
/**
* 片名简拼(小写),如英雄:yx
*/
private java.lang.String short_spell;
/**
* 标题,可能和片名不同,里面有可能包含推广相关文字
*/
private java.lang.String title;
/**
* 关键词,多个之间用逗号隔开
*/
private java.lang.String keywords;
/**
* 描述
*/
private java.lang.String description;
/**
* 1:电影,2:自定义专辑系列
*/
private java.lang.Integer type;
/**
* 来源站点
*/
private java.lang.Long site_id;
/**
* 来源页面
*/
private java.lang.String source_url;
/**
* 简介,关联t_content_id
*/
private java.lang.Long content_id;
/**
* 评分
*/
private java.lang.String score;
/**
* 来源页面中资源唯一标志,用于去重使用
*/
private java.lang.String source_uid;
/**
* 创建时间
*/
private java.lang.Long create_time;
/**
* 发布时间
*/
private java.lang.Long pub_time;
/**
* 最后更新时间
*/
private java.lang.Long update_time;
/**
* 状态信息
*/
private java.lang.Integer status;
/**
* 版本号
*/
private java.lang.Long version;
/**
* 扩展数据
*/
private Map<Object, Object> extData;
}
创建列表数据采集器com.ady01.demo2.filmlist.FilmListPageProcessor
package com.ady01.demo2.filmlist; import com.ady01.demo2.filmdetail.FilmDetailModel;
import com.ady01.demo2.filmdetail.FilmDetailPageProcessor;
import com.alibaba.fastjson.JSON;
import lombok.extern.slf4j.Slf4j;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Request;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor; /**
* <b>description</b>:电影列表页面数据采集器 <br>
* <b>time</b>:2019/4/21 12:40 <br>
* <b>author</b>:微信公众号:路人甲Java,专注于java技术分享(爬虫、分布式事务、异步消息服务、任务调度、分库分表、大数据等),喜欢请关注!
*/
@Slf4j
public class FilmListPageProcessor implements PageProcessor { public static PageModel collector(String url) {
return new FilmListPageProcessor(url).collect().getPageModel();
} private Site site = Site.me().setRetryTimes(3).setSleepTime(100).setTimeOut(10000);
//需要采集的页面
private String url; //采集的数据
private PageModel pageModel; public FilmListPageProcessor(String url) {
this.url = url;
} public FilmListPageProcessor collect() {
Request request = new Request(url);
Spider.create(this).thread(1).addRequest(request).run();
return this;
} @Override
public void process(Page page) {
String text = page.getRawText();
log.info("列表页面数据:{}", text);
this.pageModel = JSON.parseObject(text, PageModel.class);
} @Override
public Site getSite() {
return this.site;
} public PageModel getPageModel() {
return pageModel;
} public void setPageModel(PageModel pageModel) {
this.pageModel = pageModel;
}
}
测试用例com.ady01.demo2.filmlist.FilmListPageProcessorTest
package com.ady01.demo2.filmlist; import lombok.extern.slf4j.Slf4j;
import org.junit.Test; /**
* <b>description</b>: <br>
* <b>time</b>:2019/4/21 13:59 <br>
* <b>author</b>:微信微信公众号:路人甲Java,专注于java技术分享(爬虫、分布式事务、异步消息服务、任务调度、分库分表、大数据等),喜欢请关注!,专注于java技术分享(爬虫、分布式事务、异步消息服务、任务调度、分库分表、大数据)
*/
@Slf4j
public class FilmListPageProcessorTest { @Test
public void collect() {
String url = "http://m.ady01.com/rs/film/listJson/1/1";
PageModel collector = FilmListPageProcessor.collector(url);
log.info("\n\n\n列表页面数:{}", collector);
}
}
运行 com.ady01.demo2.filmlist.FilmListPageProcessorTest#collect() 方法,结果如下:
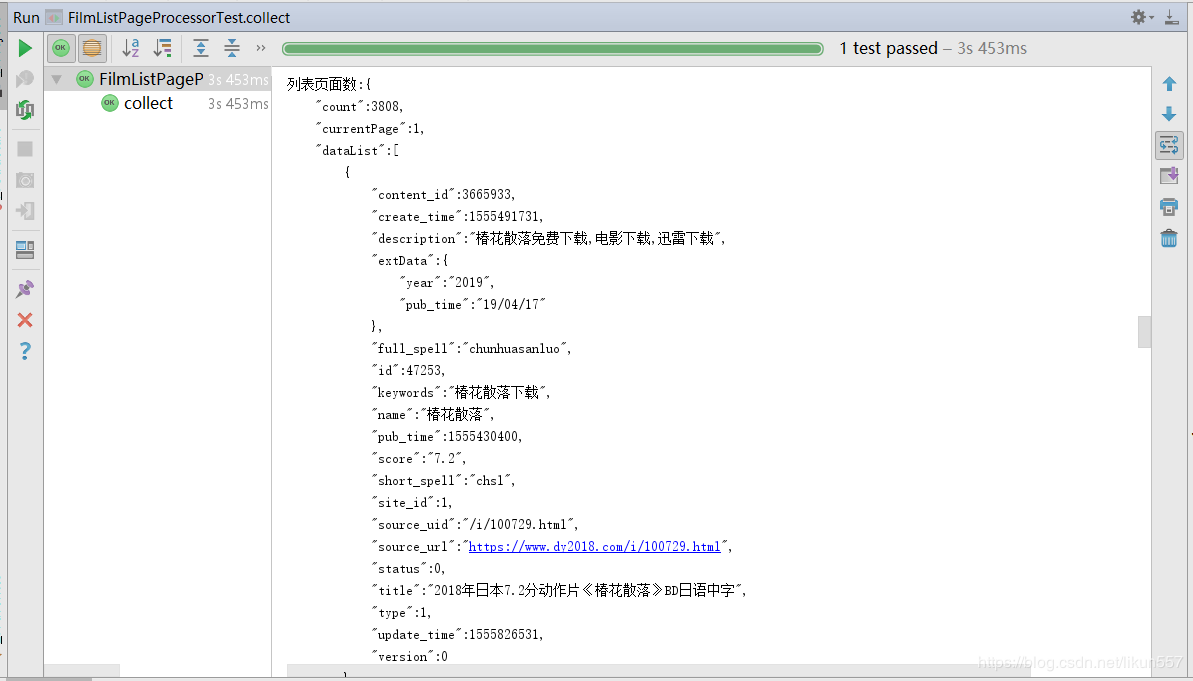
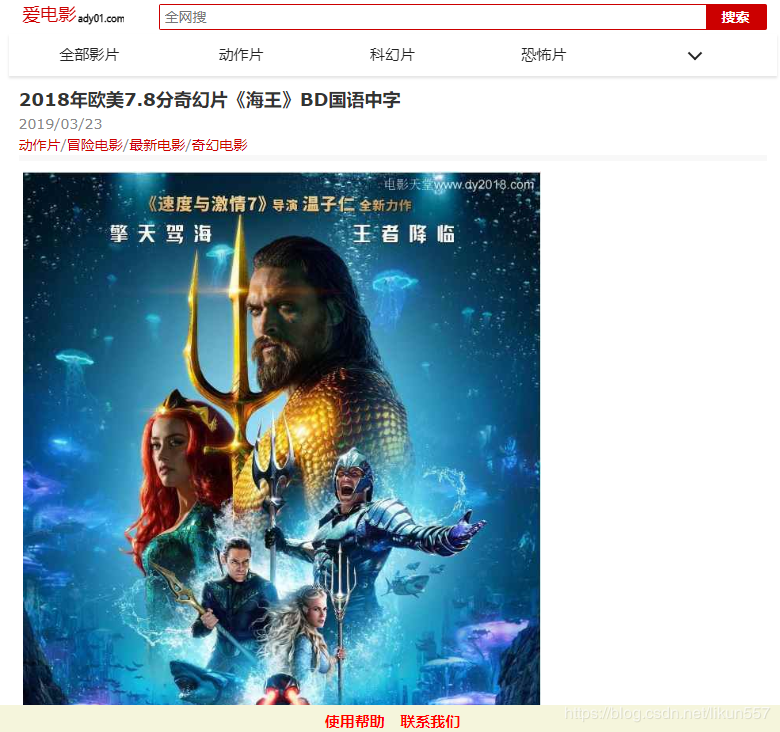
3. 爬取电影《海王》迅雷地址
我们以《海王》页面(http://m.ady01.com/rs/film/detail/46612)为例,来采集详情页的信息
需要采集的信息有:电影名称、描述信息、电影下载地址列表
创建com.ady01.demo2.filmdetail.FilmDetailModel类,用于封装电影详细信息
package com.ady01.demo2.filmdetail; import lombok.Getter;
import lombok.Setter;
import lombok.ToString; import java.io.Serializable;
import java.util.List; /**
* <b>description</b>:电影详细信息 <br>
* <b>time</b>:2019/4/21 13:18 <br>
* <b>author</b>:微信公众号:路人甲Java,专注于java技术分享(爬虫、分布式事务、异步消息服务、任务调度、分库分表、大数据等),喜欢请关注!
*/
@Setter
@Getter
@ToString
public class FilmDetailModel implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 编号
*/
private java.lang.Long id;
/**
* 片名,完整名称,不包含无关文字
*/
private java.lang.String title; /**
* 下载地址列表
*/
private List<String> downList;
}
创建详情页采集器com.ady01.demo2.filmdetail.FilmDetailPageProcessor
package com.ady01.demo2.filmdetail; import lombok.extern.slf4j.Slf4j;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Request;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Selectable; import java.util.List;
import java.util.Objects;
import java.util.stream.Collectors; /**
* <b>description</b>:电影详情页采集器,采集电影详细信息 <br>
* <b>time</b>:2019/4/21 12:40 <br>
* <b>author</b>:微信公众号:路人甲Java,专注于java技术分享(爬虫、分布式事务、异步消息服务、任务调度、分库分表、大数据等),喜欢请关注!
*/
@Slf4j
public class FilmDetailPageProcessor implements PageProcessor {
public static FilmDetailModel collector(long film_id) {
return new FilmDetailPageProcessor(film_id).collect().getFilmDetailModel();
} private Site site = Site.me().setRetryTimes(3).setSleepTime(100).setTimeOut(10000);
//电影资源id
private long film_id; //采集的数据
private FilmDetailModel filmDetailModel; public FilmDetailPageProcessor(long film_id) {
this.film_id = film_id;
} public FilmDetailPageProcessor collect() {
Request request = new Request(String.format("http://m.ady01.com/rs/film/detail/%s", this.film_id));
Spider.create(this).thread(1).addRequest(request).run();
return this;
} @Override
public void process(Page page) {
String text = page.getRawText();
log.info("列表页面数据:{}", text);
this.filmDetailModel = new FilmDetailModel();
//电影标题
String title = page.getHtml().$("span[class='film_title']","text").get();
this.filmDetailModel.setId(this.film_id);
this.filmDetailModel.setTitle(title);
//电影下载地址downList
List<Selectable> downNodes = page.getHtml().$("div.film_downurl_txt").nodes();
if (Objects.nonNull(downNodes)) {
List<String> downList = downNodes.stream().map(item -> item.$("div", "text").get()).collect(Collectors.toList());
this.filmDetailModel.setDownList(downList);
}
} @Override
public Site getSite() {
return this.site;
} public FilmDetailModel getFilmDetailModel() {
return filmDetailModel;
} public void setFilmDetailModel(FilmDetailModel filmDetailModel) {
this.filmDetailModel = filmDetailModel;
}
}
创建测试用例com.ady01.demo2.filmdetail.FilmDetailPageProcessorTest
package com.ady01.demo2.filmdetail; import com.ady01.demo2.filmlist.FilmListPageProcessor;
import com.ady01.demo2.filmlist.PageModel;
import com.ady01.util.FrameUtil;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test; @Slf4j
public class FilmDetailPageProcessorTest {
@Test
public void collect() {
long film_id = 46612L;
FilmDetailModel filmDetailModel = FilmDetailPageProcessor.collector(46612L);
log.info("\n\n\n电影《海王》详情:{}", FrameUtil.json(filmDetailModel, true));
} }
运行测试用例com.ady01.demo2.filmdetail.FilmDetailPageProcessorTest#collect()
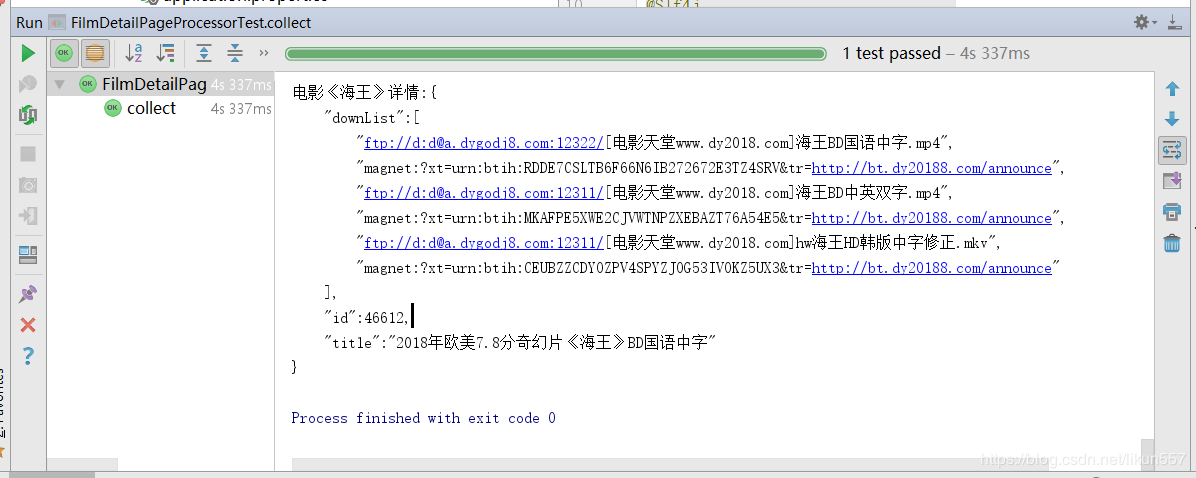
4. 总结
- webmagic中支持xpath、$选择器的方式获取页面中的元素信息,使用非常方便,如果你们对jquery比较熟悉,可以直接使用类似于jquery选择器的语法来解析整个页面的内容;还有xpath的语法,后期会有专门讲解xpath的语法,敬请关注。
- 有问题的可以留言。
- 下期咱们一起来抓取极客时间上面的课程信息
- 爱电影这个网站就是用webmagic做的,内部包含自动采集功能,每天自动采集大量大于资源,爬虫系列完结之后,将把整个网站的源码风险给大家,资源会在公众号中发布,可以提前关注一下公众号【路人甲Java】
可以关注公众号:路人甲Java,获取年薪50万课程,获取最新文章。

java爬虫系列第二讲-爬取最新动作电影《海王》迅雷下载地址的更多相关文章
- java爬虫系列第一讲-爬虫入门
1. 概述 java爬虫系列包含哪些内容? java爬虫框架webmgic入门 使用webmgic爬取 http://ady01.com 中的电影资源(动作电影列表页.电影下载地址等信息) 使用web ...
- Java爬虫_资源网站爬取实战
对 http://bestcbooks.com/ 这个网站的书籍进行爬取 (爬取资源分享在结尾) 下面是通过一个URL获得其对应网页源码的方法 传入一个 url 返回其源码 (获得源码后,对源码进 ...
- Python爬虫系列 - 初探:爬取旅游评论
Python爬虫目前是基于requests包,下面是该包的文档,查一些资料还是比较方便. http://docs.python-requests.org/en/master/ POST发送内容格式 爬 ...
- Java爬虫——B站弹幕爬取
如何通过B站视频AV号找到弹幕对应的xml文件号 首先爬取视频网页,将对应视频网页源码获得 就可以找到该视频的av号aid=8678034 还有弹幕序号,cid=14295428 弹幕存放位置为 h ...
- java爬虫入门--用jsoup爬取汽车之家的新闻
概述 使用jsoup来进行网页数据爬取.jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuer ...
- 小伙子自从学会用Python爬取岛国“动作”电影,身体一天不如一天
在互联网的世界里,正确的使用VPN看看外面的世界,多了解了解世界的发展.肉身翻墙后,感受一下外面的肮脏世界.墙内的朋友叫苦不迭,由于某些原因,VPN能用的越来越少.上周我的好朋友狗子和我哭诉说自己常用 ...
- Java爬虫框架WebMagic入门——爬取列表类网站文章
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下. WebMagic框架简介 WebMagic框架包含四个组件,PageProcessor.Sch ...
- Python爬虫系列 - 初探:爬取新闻推送
Get发送内容格式 Get方式主要需要发送headers.url.cookies.params等部分的内容. t = requests.get(url, headers = header, param ...
- java爬虫系列目录
1. java爬虫系列第一讲-爬虫入门(爬取动作片列表) 2. java爬虫系列第二讲-爬取最新动作电影<海王>迅雷下载地址 3. java爬虫系列第三讲-获取页面中绝对路径的各种方法 4 ...
随机推荐
- TensorFlow从1到2(五)图片内容识别和自然语言语义识别
Keras内置的预定义模型 上一节我们讲过了完整的保存模型及其训练完成的参数. Keras中使用这种方式,预置了多个著名的成熟神经网络模型.当然,这实际是Keras的功劳,并不适合算在TensorFl ...
- Flannel工作原理
flanneld程序启动会有一个参数叫做-etcd-prefix和-iface.前者是指定flanneld程序使用etcd的哪个节点来存储数据,-face是指定flanneld使用网络是使用宿主机哪个 ...
- RabbitMQ 消息队列 入门 第一章
RabbitMQ : 官网:https://www.rabbitmq.com/ GitHub:https://github.com/rabbitmq?q=rabbitmq 第一步安装: 点击 htt ...
- 企业级Harbor介绍及安装
企业级Harbor介绍及安装 一.Harbor介绍 VMware公司最近开源了企业级Registry项目Harbor,其的目标是帮助用户迅速搭建一个企业级的Docker registry 服务.它以D ...
- PBFT概念与Go语言入门(Tendermint基础)
Tendermint作为当前最知名且实用的PBFT框架,网上资料并不很多,而实现Tendermint和以太坊的Go语言,由于相对小众,也存在资料匮乏和模糊错漏的问题.本文简单介绍PBFT概念和Go语言 ...
- spring2.0 Consider renaming one of the beans or enabling overriding by setting spring.main.allow-bean-definiti
1. 报错信息 Description: The bean 'dataSource', defined in BeanDefinition defined in class path resource ...
- SQL注入渗透实战
概述: 判断注入点: http://www.xxxxx.com/page.php?pid=42 and 1=1 #true http://www.xxxxx.com/page.php?pid=42 a ...
- 安卓4.0以上系统怎么不用root激活XPOSED框架的方法
在大多单位的引流或业务操作中,基本上都需要使用安卓的高端技术Xposed框架,近期,我们单位购买了一批新的安卓4.0以上系统,基本上都都是基于7.0以上版本,基本上都不能够刷入root超级权限,即便是 ...
- SQL Server作业报错特殊案例
一个作业报错,报错信息如下,从错误信息根本看不出为什么出错,手工运行作业又成功了.一时不清楚什么原因导致作业出错. Message Executed as user: NT SERVICE\SQLSE ...
- 安装windows 10到固态硬盘实践记录
1.前提 由于之前一直用的机械硬盘,电脑用了几年是越来越慢,所以打算买个SSD,装个新系统,其他的机械硬盘都当从盘用 2.准备工作 SSD :256G 3星的 WIN10正版光盘一张 外置光驱一个 3 ...