使用YOLOv2进行图像检测
- 基本配置信息
tensorflow (1.4.0)
tensorflow-tensorboard (0.4.0)
Keras (2.1.5)
Python (3.6.0)
Anaconda 4.3.1 (64-bit)
Windows 7
- darknet链接
https://github.com/pjreddie/darknet
下载后在cfg文件夹下找到yolov2的配置文件yolov2.cfg
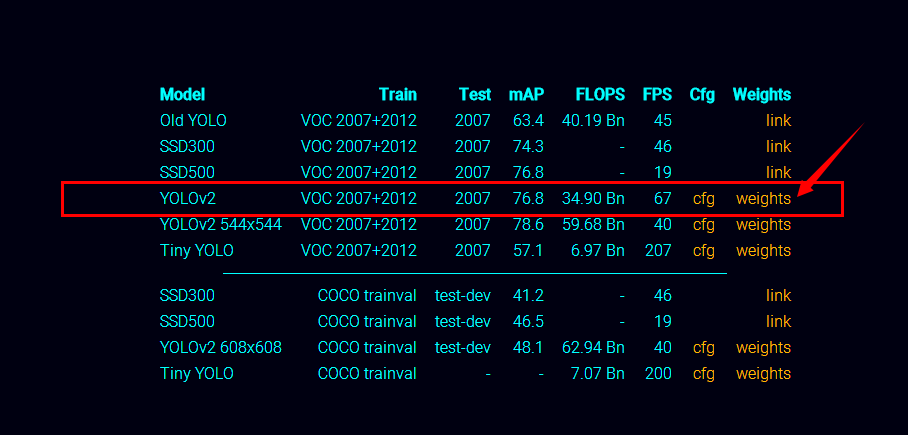
- yolov2权重文件链接
https://pjreddie.com/darknet/yolov2/
在页面中选择YOLOV2 weights下载
- yad2k 链接
https://github.com/allanzelener/YAD2K
下载完成后将之前下载好的yolov2.cfg文件,YOLOV2 weights文件拷贝到yad2k目录下
- 使用spyder 运行yad2k目录下的yad2k.py文件
在运行配置里设置运行时所需的参数信息
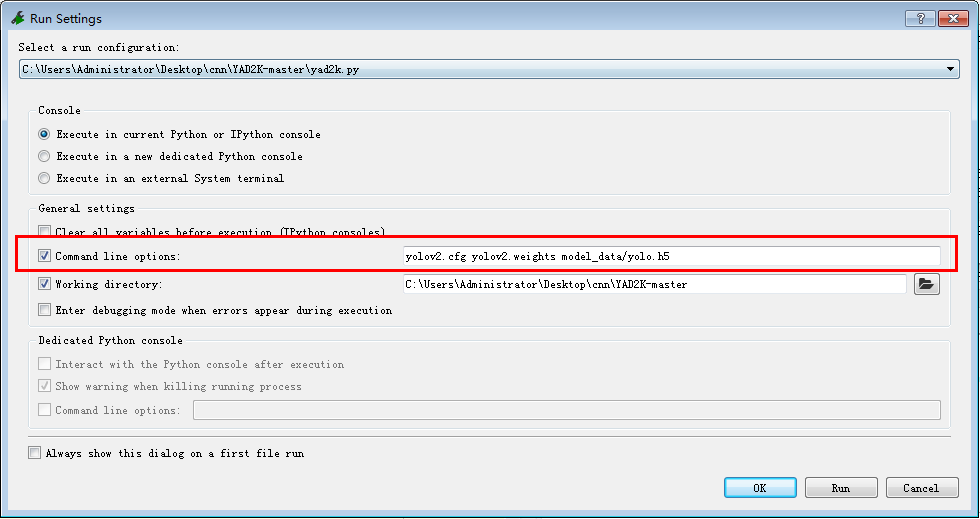
或使用命令行运行yad2k.py
python yad2k.py yolov2.cfg yolov2.weights model_data/yolo.h5
运行结果如图所示

生成的yolo.h5文件在model_data文件夹内
- 利用生成的权重信息,进行图像检测
使用opencv调用电脑摄像头,进行视频图像信息的检测
opencv版本
opencv-python (3.2.0)
在yad2k目录下创建自己的demo,参考https://www.jianshu.com/p/3e77cefeb49b
import cv2
import os
import time
import numpy as np
from keras import backend as K
from keras.models import load_model from yad2k.models.keras_yolo import yolo_eval, yolo_head class YOLO(object):
def __init__(self):
self.model_path = 'model_data/yolo.h5'
self.anchors_path = 'model_data/yolo_anchors.txt'
self.classes_path = 'model_data/coco_classes.txt'
self.score = 0.3
self.iou = 0.5 self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.sess = K.get_session()
self.boxes, self.scores, self.classes = self.generate() def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names def _get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
anchors = np.array(anchors).reshape(-1, 2)
return anchors def generate(self):
model_path = os.path.expanduser(self.model_path)
assert model_path.endswith('.h5'), 'Keras model must be a .h5 file.' self.yolo_model = load_model(model_path) # Verify model, anchors, and classes are compatible
num_classes = len(self.class_names)
num_anchors = len(self.anchors)
# TODO: Assumes dim ordering is channel last
model_output_channels = self.yolo_model.layers[-1].output_shape[-1]
assert model_output_channels == num_anchors * (num_classes + 5), \
'Mismatch between model and given anchor and class sizes'
print('{} model, anchors, and classes loaded.'.format(model_path)) # Check if model is fully convolutional, assuming channel last order.
self.model_image_size = self.yolo_model.layers[0].input_shape[1:3]
self.is_fixed_size = self.model_image_size != (None, None) # Generate output tensor targets for filtered bounding boxes.
# TODO: Wrap these backend operations with Keras layers.
yolo_outputs = yolo_head(self.yolo_model.output, self.anchors, len(self.class_names))
self.input_image_shape = K.placeholder(shape=(2, ))
boxes, scores, classes = yolo_eval(yolo_outputs, self.input_image_shape, score_threshold=self.score, iou_threshold=self.iou)
return boxes, scores, classes def detect_image(self, image):
start = time.time()
#image = cv2.imread(image)
#cv2.imshow('image',image)
y, x, _ = image.shape if self.is_fixed_size: # TODO: When resizing we can use minibatch input.
resized_image = cv2.resize(image, tuple(reversed(self.model_image_size)), interpolation=cv2.INTER_CUBIC)
image_data = np.array(resized_image, dtype='float32')
else:
image_data = np.array(image, dtype='float32') image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension. out_boxes, out_scores, out_classes = self.sess.run(
[self.boxes, self.scores, self.classes],
feed_dict={
self.yolo_model.input: image_data,
self.input_image_shape: [image.shape[0], image.shape[1]],
K.learning_phase(): 0
})
print('Found {} boxes for {}'.format(len(out_boxes), 'img')) for i, c in reversed(list(enumerate(out_classes))):
predicted_class = self.class_names[c]
box = out_boxes[i]
score = out_scores[i] label = '{} {:.2f}'.format(predicted_class, score)
top, left, bottom, right = box
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(y, np.floor(bottom + 0.5).astype('int32'))
right = min(x, np.floor(right + 0.5).astype('int32'))
print(label, (left, top), (right, bottom)) cv2.rectangle(image, (left, top), (right, bottom), (255, 0, 0), 2)
cv2.putText(image, label, (left, int(top - 4)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1, cv2.LINE_AA)
end = time.time()
print(end - start)
return image def close_session(self):
self.sess.close() def detect_vedio(yolo):
camera = cv2.VideoCapture(0) while True:
res, frame = camera.read() if not res:
break image = yolo.detect_image(frame)
cv2.imshow("detection", image) if cv2.waitKey(1) & 0xFF == ord('q'):
break
yolo.close_session() def detect_img(img, yolo):
image = cv2.imread(img)
r_image = yolo.detect_image(image)
cv2.namedWindow("detection")
while True:
cv2.imshow("detection", r_image)
if cv2.waitKey(110) & 0xff == 27:
break
yolo.close_session() if __name__ == '__main__':
yolo = YOLO()
detect_vedio(yolo)
使用YOLOv2进行图像检测的更多相关文章
- 『科学计算』图像检测微型demo
这里是课上老师给出的一个示例程序,演示图像检测的过程,本来以为是传统的滑窗检测,但实际上引入了selectivesearch来选择候选窗,所以看思路应该是RCNN的范畴,蛮有意思的,由于老师的注释写的 ...
- 第五讲_图像识别之图像检测Image Detection
第五讲_图像识别之图像检测Image Detection 目录 物体检测 ILSVRC竞赛200类(每个图片多个标签):输出类别+Bounding Box(x,y,w,h) PASCAL VOC 20 ...
- 图像检测之sift and surf---sift中的DOG图 surf hessian
http://www.cnblogs.com/tornadomeet/archive/2012/08/17/2644903.html http://www.cnblogs.com/slysky/arc ...
- [1] YOLO 图像检测 及训练
YOLO(You only look once)是流行的目标检测模型之一, 原版 Darknet 使用纯 C 编写,不需要安装额外的依赖包,直接编译即可. CPU环境搭建 (ubuntu 18.04) ...
- C#图像检测开源项目
AForge.NET AForge.NET is an open source C# framework designed for developers and researchers in the ...
- 基于YOLO-V2的行人检测(自训练)附pytorch安装方法
声明:本文是别人发表在github上的项目,并非个人原创,因为那个项目直接下载后出现了一些版本不兼容的问题,故写此文帮助解决.(本人争取在今年有空的时间,自己实现基于YOLO-V4的行人检测) 项目链 ...
- 图像检测算法Halcon 10的使用
安装完成HALCON之后,在VS项目中添加动态链接库配置项目,并修改此项目属性的包含目录.库目录和链接器.
- 使用CNN做电影评论的负面检测——本质上感觉和ngram或者LSTM同,因为CNN里图像检测卷积一般是3x3,而文本分类的话是直接是一维的3、4、5
代码如下: from __future__ import division, print_function, absolute_import import tensorflow as tf impor ...
- 一文带你学会使用YOLO及Opencv完成图像及视频流目标检测(上)|附源码
计算机视觉领域中,目标检测一直是工业应用上比较热门且成熟的应用领域,比如人脸识别.行人检测等,国内的旷视科技.商汤科技等公司在该领域占据行业领先地位.相对于图像分类任务而言,目标检测会更加复杂一些,不 ...
随机推荐
- ubuntu apt-get安装、卸载软件命令及如何查看日志
linux亮红灯的我,开始学习linux,学习使我快乐,大家一起来学习... 1.安装软件命令 sudo apt-get apache2 安装apache,安装在默认路径下,指定路径安装,其实 ...
- 第1次作业:小菜鸟的平凡IT梦
#1.结缘计算机的始末 ##1.1与计算机相识的几年 作为一个95后,出生在一个互联网开始兴盛的时代.我记得小学的时候,开始知道电脑这个东西,学校有了机房,开始有了所谓的电脑课.那时候计算机对于我来说 ...
- C语言第二次博客作业---分支结构 陈张鑫
一.PTA实验作业 题目1:计算分段函数[2] 本题目要求计算下列分段函数f(x)的值: 1.实验代码 int main(){double x,y; scanf("%lf",&am ...
- c语言一,二数组
一.PTA实验作业 题目1:7-4 简化的插入排序 1. 本题PTA提交列表 2. 设计思路 1.定义整形变量N,temp,i. 2.输入N 3.通过for(i=1;i<=N;i++)的循环语句 ...
- 20162330 第三周 蓝墨云班课 泛型类-Bag 练习
目录 题目及要求 思路分析 遇到的问题和解决过程 代码实现及托管链接 感想 参考资料 题目及要求 代码运行在命令行中,路径要体现学号信息,IDEA中,伪代码要体现个人学号信息: 参见Bag的UML图, ...
- Beta冲刺NO.6
Beta冲刺 第六天 1. 昨天的困难 1.对于设计模式的应用不熟悉,所以在应用上出现了很大的困难. 2.SSH中数据库的管理是用HQL语句实现的,所以在多表查询时出现了很大的问题. 3.页面结构太凌 ...
- SQLAlchemy 教程 —— 基础入门篇
SQLAlchemy 教程 -- 基础入门篇 一.课程简介 1.1 实验内容 本课程带领大家使用 SQLAlchemy 连接 MySQL 数据库,创建一个博客应用所需要的数据表,并介绍了使用 SQLA ...
- 关于Mac OS 使用GIT的引导
1. 下载Git installer 链接地址:https://ncu.dl.sourceforge.net/project/git-osx-installer/git-2.14.1-intel-un ...
- java 注解的实现机制
一.什么是注解: 注解是标记,也可以理解成是一种应用在类.方法.参数.属性.构造器上的特殊修饰符.注解作用有以下三种: 第一种:生成文档,常用的有@param@return等. 第二种:替代配置文件的 ...
- 【编程开发】PHP---面向对象
面向对象编程 类:在现实世界中,任何事物都有种类的概念:车 类是由特征和行为构成的. 特征:都是不动的,从出厂的时候就已经内置好了(属性) 行为:一种动的状态.(方法(函数)) 行为依赖于这些特征,而 ...