Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop
下载地址:http://hadoop.apache.org/releases.html
选择对应版本的二进制文件进行下载
2.解压配置
以hadoop-2.6.5.tar.gz为例
解压文件
tar -zxvf hadoop-2.6.5.tar.gz
移动到/opt 目录下
mv hadoop-2.6.5 /opt
配置JDK环境变量
追加Hadoop的bin和sbin目录到环境变量PATH中,这里不多讲。
使用 source命令使配置立即生效
例如:source /etc/profile
配置四个配置文件core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
本例共四个主机,分别是s10,s11,s12,s13
s10:名称结点
s11、s12:数据结点
s13:辅助名称结点
/etc/hosts 文件配置主机映射如下:

core-site.xml 配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s10:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.6.5/tmp</value>
</property>
</configuration>
hdfs-site.xml 配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>s13:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-2.6.5/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-2.6.5/hdfs/data</value>
</property>
</configuration>
mapred-site.xml 配置
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml 配置
<?xml version="1.0"?> <configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s10</value>
</property>
</configuration>
修改 slaves 文件内容为对应的数据结点
s11
s12
为了保险,此处直接配置JAVA_HOME到 /opt/hadoop-2.6.5/etc/hadoop/hadoop-env.sh 中,防止出现JAVA_HOME is not set and could not be found.错误
hadoop-env.sh文件第一行有效代码(不包含注释)改为
export JAVA_HOME=/usr/soft/jdk1.8.0_181
3. 配置四台主机 ssh 无密码相互访问,复制配置好的 /opt/hadoop-2.6.5 到其它三台主机
快速配置四台主机ssh无密码访问方法如下:
①在四台主机上分别执行 ssh-keygen -t rsa 生成公钥和私钥
②把四台主机的公钥分别追加到s0主机~/.ssh/authorized_keys 文件中
③远程复制 authorized_keys 文件到其它三台主机
更多细节请参考:https://www.cnblogs.com/jonban/p/sshNoPasswordAccess.html
配置完成后使用 ssh 命令在每一台主机上手动登录一下其它三台主机,完成第一次访问的确认,以后就可以直接登录了
远程复制配置好的 /opt/hadoop-2.6.5 到其它三台主机,记得配置JDK环境变量和Hadoop环境变量,参考第2步
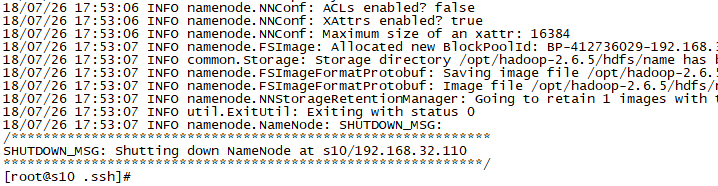
4. 格式化文件系统为hdfs
hadoop namenode -format
运行结果如下:
5. 启动Hadoop集群环境
start-dfs.sh
start-yarn.sh
在四台主机上分别输入 jps 命令,查看集群状态,内容如下:
[root@s10 hadoop]# jps
28417 Jps
28163 ResourceManager
27907 NameNode
[root@s11 hadoop]# jps
27083 Jps
26875 DataNode
26972 NodeManager
[root@s12 hadoop]# jps
27095 Jps
26887 DataNode
26984 NodeManager
[root@s13 hadoop]# jps
26882 Jps
26826 SecondaryNameNode
符合集群预期结果
s10:名称结点
s11、s12:数据结点
s13:辅助名称结点
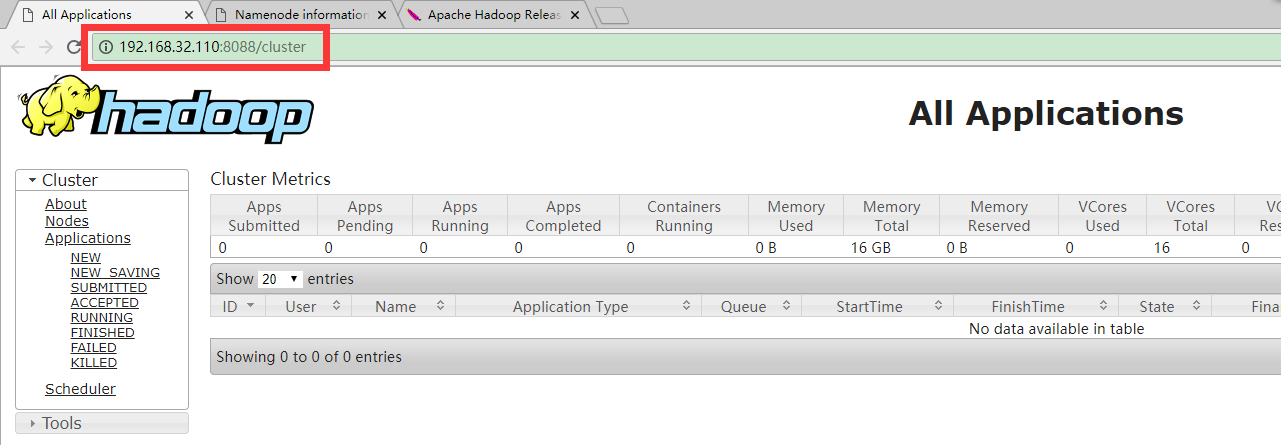
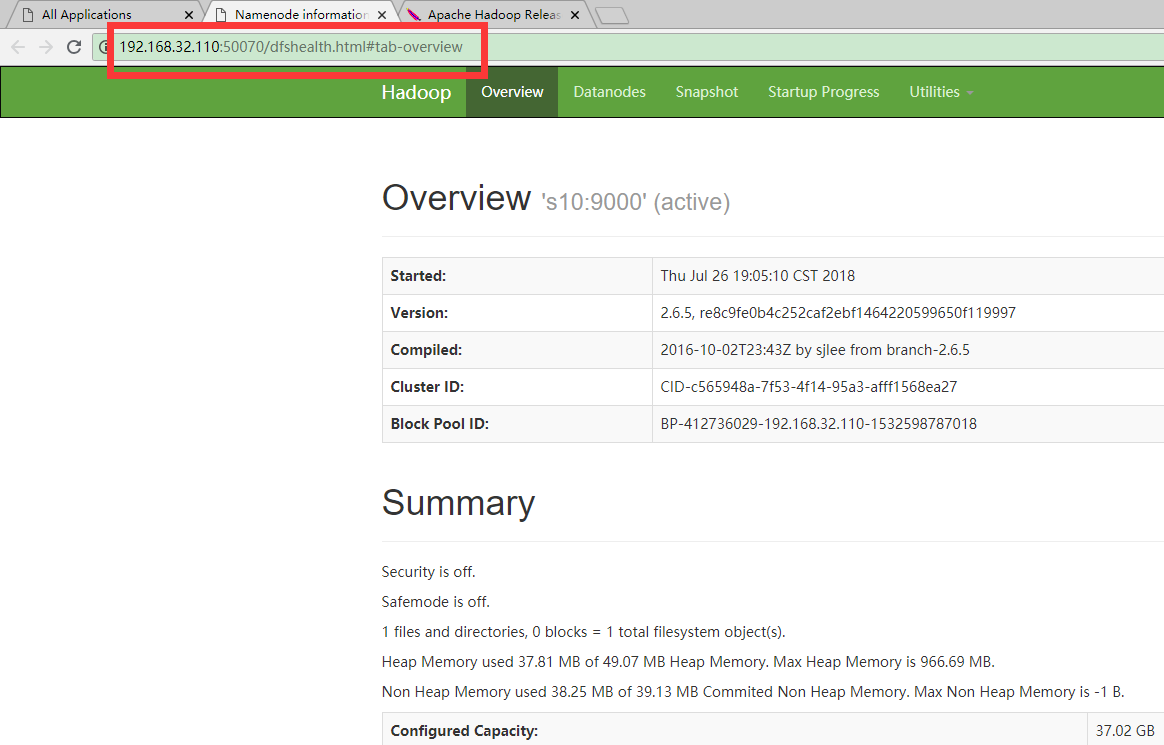
6.验证
浏览器输入地址:
http://192.168.32.110:8088
http://192.168.32.110:50070
这里的IP是主机s10的IP
效果截图如下,地址自动跳转
Hadoop完全分布式集群环境搭建
.
Hadoop完全分布式集群环境搭建的更多相关文章
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- hadoop完全分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 准备三台虚拟机master,slave01,slave02 hado ...
- ZooKeeper 完全分布式集群环境搭建
1. 搭建前准备 示例共三台主机,主机IP映射信息如下: 192.168.32.101 s1 192.168.32.102 s2 192.168.32.103 s3 2.下载ZooKeeper, 以 ...
- Kafka 完全分布式集群环境搭建
思路: 先在主机s1上安装配置,然后远程复制到其它两台主机s2.s3上, 并分别修改配置文件server.properties中的broker.id属性. 1. 搭建前准备 示例共三台主机,主机IP映 ...
- hadoop伪分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 设置静态IP地址 Hadoop伪分布式集群搭建: 为普通用户添加su ...
- hadoop学习笔记(五)hadoop伪分布式集群的搭建
本文原创,如需转载,请注明作者和原文链接 1.集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点 2.解压tar.gz包 [root@node01 ~]# ...
- Hadoop学习(一):完全分布式集群环境搭建
1. 设置免密登录 (1) 新建普通用户hadoop:useradd hadoop(2) 在主节点master上生成密钥对,执行命令ssh-keygen -t rsa便会在home文件夹下生成 .ss ...
随机推荐
- 接水果(fruit)——整体二分+扫描线
题目 [题目描述] 风见幽香非常喜欢玩一个叫做 osu! 的游戏,其中她最喜欢玩的模式就是接水果.由于她已经 DT FC 了 The big black,她觉得这个游戏太简单了,于是发明了一个更加难的 ...
- SKlearn中分类决策树的重要参数详解
学习机器学习童鞋们应该都知道决策树是一个非常好用的算法,因为它的运算速度快,准确性高,方便理解,可以处理连续或种类的字段,并且适合高维的数据而被人们喜爱,而Sklearn也是学习Python实现机器学 ...
- linux下find查找与批量替换文件中指定内容
经常在部署tomcat时需要替换配置文件中的ip,find命令批量替换还是很方便的 查找需要替换的ip,看看哪些文件有配置这个ip,执行下面命令: find ./ -type f -regex &qu ...
- spring boot与 spring.factories
spring boot启动加载过程 META-INF下面的spring.factories 解析@Configuration https://www.jianshu.com/p/346cac67bfc ...
- jquery——解决鼠标移入移出导致盒子不停移动的bug
使用mouseover().mouseout()时会出现这样一种情况,鼠标快速多次移入移出后这个盒子会在鼠标不动后继续运动 代码如下: <!DOCTYPE html> <html l ...
- 非递归遍历二叉树Java版的实现代码(没写层次遍历)
直接上代码呵呵,里面有注解 package www.com.leetcode.specificProblem; import java.util.ArrayList; import java.util ...
- Spring Cloud微服务初探
学习初衷 因为加了不少优秀的知识星球,结交了更多的小伙伴,加了更多的群,每每在自我介绍的时候,都说自己是Android & Java攻城狮. 然鹅,有的小伙伴就来问了,你是搞Java的,那对S ...
- java多线程,如何防止脏读数据
多线程容易“非线程安全”的情况,是由于用了全局变量,而又没有很好的控制起情况.所以无论做什么程序,谨慎使用全局变量 "非线程安全"其实会在多个线程对同一个对象中的实例变量进行并发访 ...
- Unity3d中使用assetbundle
1.导出assetbundle: ①单个资源导出成assetbundle: ②多个资源导出成一个assetbundle: 2.读取assetbundle: ①加载到内存: ②解压为具体资源. 1.导出 ...
- Int与String之间相互转换
1 如何将字串 String 转换成整数 int? A. 有两个方法: 1). int i = Integer.parseInt([String]); 或 i = Integer.parseInt([ ...