MSD_radix_sort
一、这次是在上一次尝试基础上进行的,预期是达到上次性能的9倍。
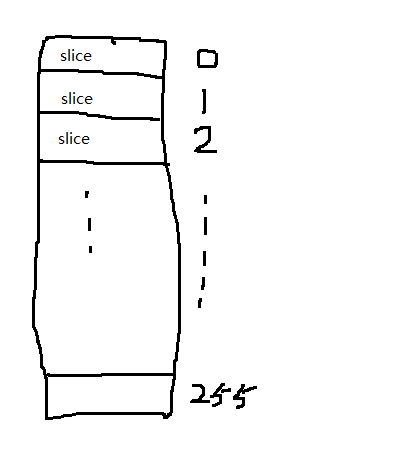
MSD的基本手法就是不断切片。
每一步都是把整体数据切割成256片,如上图所示,实际情况切片未必均匀,有的slice内可能一个元素也没有。
接下来对于每个切片怎么办呢?
答案是继续切,对于特殊数据来讲,切片过程可以很快结束,这样就可以实现比LSD更快的速度。
这里面最困难的地方就是如何存储每个slice的头和尾。
如果采用下述方式,应该是行不通的。
这个方式需要做数组元素插入,还要跟踪中间数据,因此没具体考虑。
我真正采用的是下表:
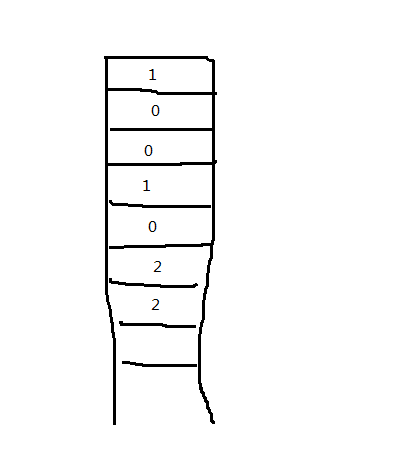
表中第一项表示第一个元素开启一个类别,紧跟的0表示此元素和上面的1是同一类。
至于2表明在切片过程中是一个孤立的元素,后续就没必要再切片了。
这个方式可以大大简化编码。
二、伪代码。
for each slice
if slice-tag == continue;
if slice-tag ==
slice it;
update bookkeeping
int main(){
HANDLE heap = NULL;
Bucket bucket[BUCKETSLOTCOUNT];
PageList * pageListPool;
int plpAvailable = ;
int * pages = NULL;
int * pagesAvailable = NULL;
int * objIdx;
unsigned short * s;
__int8 * classifier = NULL;
time_t timeBegin;
time_t timeEnd;
heap = HeapCreate(HEAP_NO_SERIALIZE|HEAP_GENERATE_EXCEPTIONS, *, );
if (heap != NULL){
pages = (int * )HeapAlloc(heap, , (TFSI/PAGEGRANULAR + BUCKETSLOTCOUNT + ) * PAGEAMOUNT);
pageListPool = (PageList *)HeapAlloc(heap, , (TFSI/PAGEGRANULAR + ) * sizeof(PageList));
s = (unsigned short *)HeapAlloc(heap, , TFSI*sizeof(unsigned short));
objIdx = (int *)HeapAlloc(heap, , TFSI * sizeof(int));
classifier = (__int8 *)HeapAlloc(heap, , (TFSI+)*sizeof(__int8));
}
MakeSure(pages != NULL && pageListPool != NULL && objIdx != NULL && classifier != NULL);
for(int i=; i<TFSI; i++) objIdx[i]=i;
timeBegin = clock();
for (int i=; i<TFSI; i++) s[i] = rand();
timeEnd = clock();
printf("\n%f(s) consumed in generating numbers", (double)(timeEnd-timeBegin)/CLOCKS_PER_SEC);
SecureZeroMemory(classifier, TFSI*sizeof(__int8));
classifier[] = ;
classifier[TFSI] = ;
timeBegin = clock();
bool no_need_further_processing = false;
for (int t=sizeof(short)-; t>=; t--){
int bucketIdx;
int slice_pointer = ;
int slice_base = ;
int flagCounter = ;
if (no_need_further_processing) break;
//classifier: 1 new catagory
//classifier: 2 completed catagory process
while (slice_pointer < TFSI){
if (classifier[slice_pointer] == ){
slice_base = slice_pointer;
classifier[slice_base] = ;
while (classifier[slice_pointer] == ){
slice_pointer++;
flagCounter++;
}
classifier[slice_base] = ;
if (flagCounter == TFSI) no_need_further_processing = true;
continue;
}
if (classifier[slice_pointer] == ){
FillMemory(pages, (TFSI/PAGEGRANULAR + BUCKETSLOTCOUNT + ) * PAGEAMOUNT, 0xff);
SecureZeroMemory(pageListPool, (TFSI/PAGEGRANULAR + ) * sizeof(PageList));
pagesAvailable = pages;
plpAvailable = ;
for(int i=; i<; i++){
bucket[i].currentPagePtr = pagesAvailable;
bucket[i].offset = ;
bucket[i].pl.PagePtr = pagesAvailable;
bucket[i].pl.next = NULL;
pagesAvailable += PAGEGRANULAR;
bucket[i].currentPageListItem = &(bucket[i].pl);
}
slice_base = slice_pointer;
classifier[slice_base] = ;
while (classifier[slice_pointer] == ){
//for each slice element, push_back to pages;
unsigned char * cell = (unsigned char *)&s[objIdx[slice_pointer]];
bucketIdx = cell[t];
//save(bucketIdx, objIdx[i]);
bucket[bucketIdx].currentPagePtr[ bucket[bucketIdx].offset ] = objIdx[slice_pointer];
bucket[bucketIdx].offset++;
if (bucket[bucketIdx].offset == PAGEGRANULAR){
bucket[bucketIdx].currentPageListItem->next = &pageListPool[plpAvailable];
plpAvailable++;
bucket[bucketIdx].currentPageListItem->next->PagePtr = pagesAvailable;
bucket[bucketIdx].currentPageListItem->next->next = NULL;
bucket[bucketIdx].currentPagePtr = pagesAvailable;
bucket[bucketIdx].offset = ;
pagesAvailable += PAGEGRANULAR;
bucket[bucketIdx].currentPageListItem = bucket[bucketIdx].currentPageListItem->next;
}
slice_pointer++;
}
classifier[slice_base] = ;
//update classifier;
//update objIdx index
int start = slice_base;
for (int i=; i<; i++){
PageList * p;
p = &(bucket[i].pl);
//classifier: 1 new catagory
//classifier: 2 complete catagory process
classifier[start] = ;
int counters = ;
while (p){
for (int t=; t<PAGEGRANULAR; t++){
int idx = p->PagePtr[t];
if (idx != TERMINATOR){
objIdx[start] = idx;
start++;
counters++;
}
if (idx == TERMINATOR) break;
}
p = p->next;
}
if (counters == ) classifier[start-] = ;
}
//update objIdx index
} //if (classifier[slice_pointer] == 1)
} //while (slice_pointer < TFSI)
} //for (int t=sizeof(short)-1; t>=0; t--)
timeEnd = clock();
printf("\n%f(s) consumed in generating results", (double)(timeEnd-timeBegin)/CLOCKS_PER_SEC);
//for(int i=0; i<TFSI; i++) printf("%d\n", s[objIdx[i]]);
HeapFree(heap, , pages);
HeapFree(heap, , pageListPool);
HeapFree(heap, , s);
HeapFree(heap, , objIdx);
HeapFree(heap, , classifier);
HeapDestroy(heap);
return ;
}
三、测试
1024*1024*100 个短整型。
时间 5.438s
看到这里就知道杯具了,比LSD还慢。
如果应用到二维表,会更惨不忍睹。试了下果然如此。
四、讨论
如果哪位有更好的方法,欢迎讨论。
或者,基数排序只是一个花瓶?
MSD_radix_sort的更多相关文章
- 读写ini文件
C# 使用文件流来读写ini文件 背景 之前采用ini文件作为程序的配置文件,觉得这种结构简单明了,配置起来也挺方便.然后操作方式是通过WindowsAPI,然后再网上找到一个基于WindowsAPI ...
随机推荐
- 读书印记 - 《文革前的邓小平:毛XX的副帅》
开始看才发现这居然是本学术著作,阅读难度系数比小说.传记要很多,相比于小说的人物心理.传记的故事套路,这本书的基本写法是举一大坨材料来描述当时的事实然后稍微发表一点学术观点.....我对这个内容本身挺 ...
- "i++"和“++i”的区别
测试: #include <iostream> using namespace std; int main(){ int i =0; cout << "初始化 i = ...
- 性能测试工具LoadRunner03-LR之Virtual User Generator 脚本创建以及回放设置
vuser_init,Action,vuser_end说明 vuser_init 录制的一般是业务流程开始之前的初始化工作(如登录,服务器初始化) Action 录制的一般是业务流程操作的事件 vus ...
- [转]JavaScriptSerializer中日期序列化
本文转自:http://www.cnblogs.com/songxingzhu/p/3816309.html 直接进入主题: class Student { public int age { get; ...
- Oracle SQL Tuning Advisor 测试
如果面对一个需要优化的SQL语句,没有很好的想法,可以先试试Oracle的SQL Tuning Advisor. SQL> select * from v$version; BANNER --- ...
- LeetCode 455.分发饼干(C++)
假设你是一位很棒的家长,想要给你的孩子们一些小饼干.但是,每个孩子最多只能给一块饼干.对每个孩子 i ,都有一个胃口值 gi ,这是能让孩子们满足胃口的饼干的最小尺寸:并且每块饼干 j ,都有一个尺寸 ...
- C#之Clone
因为类的实例是引用类型,要想用原有的类中的实例的数据的话,既要想创建原对象的一个副本的话,只能用clone方法. Clone方法分为深clone和浅clone 在C#中提供了浅clone的方法,即为M ...
- Oracle数据库触发器使用(删除触发)
当我们需要用到触发器的时候,还是很方便,你会指定当我在操作某一事件时触发效果完成我所希望完成的事情:这就是触发器, 下面我给大家上一串代码,这是一个当我在操作删除事件操作时候,我希望把即将删除那条数据 ...
- maven课程 项目管理利器-maven 3-8 maven依赖传递 4星
本节主要讲了 1 maven依赖传递 本地项目路径:F:\xiangmu3\Xin\FuQiang\maven\code 2 maven排除依赖 3 注意事项 4 零散知识点 1 maven依赖传递 ...
- CSS的框模型(div)与边距(margin、padding)
所谓框模型,例如div标签,你就可以直接把它理解成一个相框. 这个相框里面的相片有高度和宽度,框本身也有一定的宽度.相框和别的相框之间,还有一定的边距. div设置常见属性 border:边框 pad ...